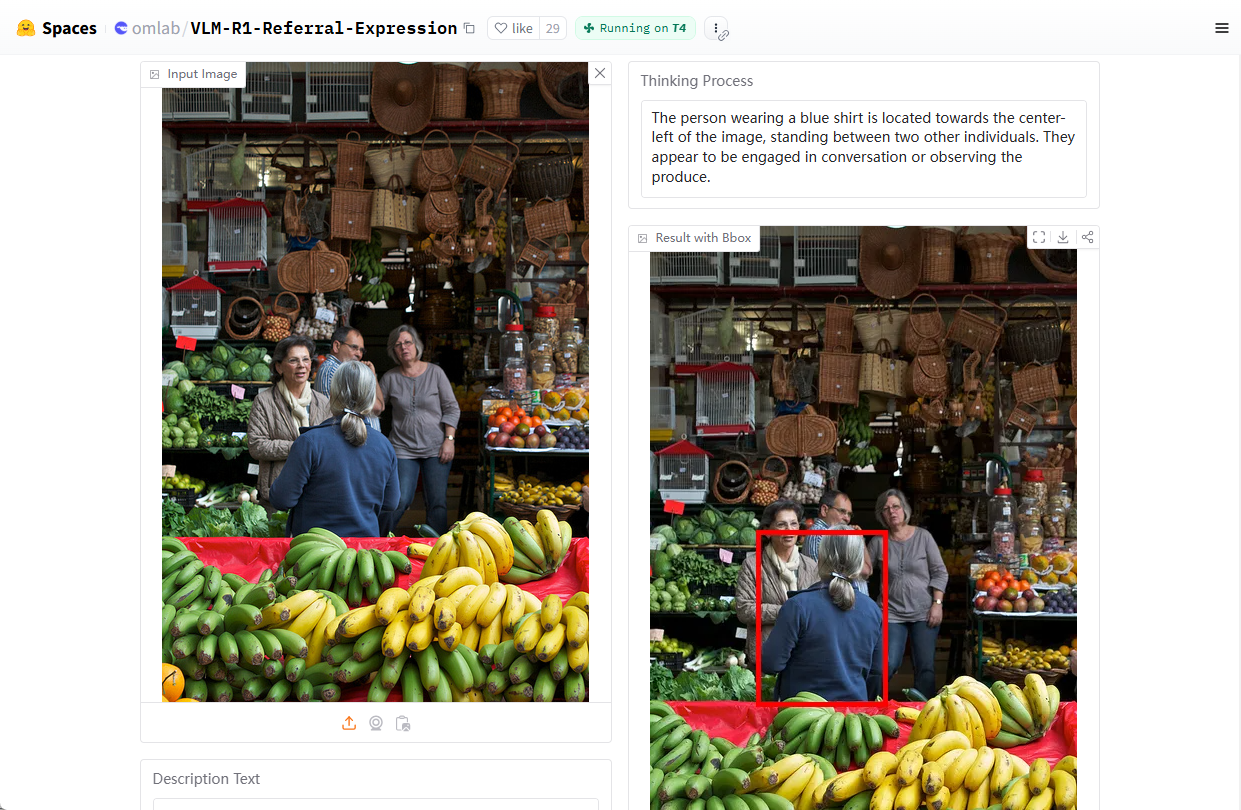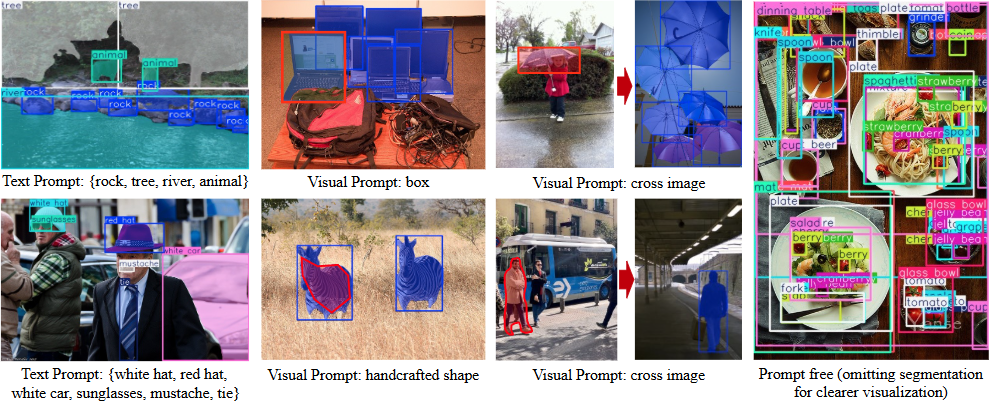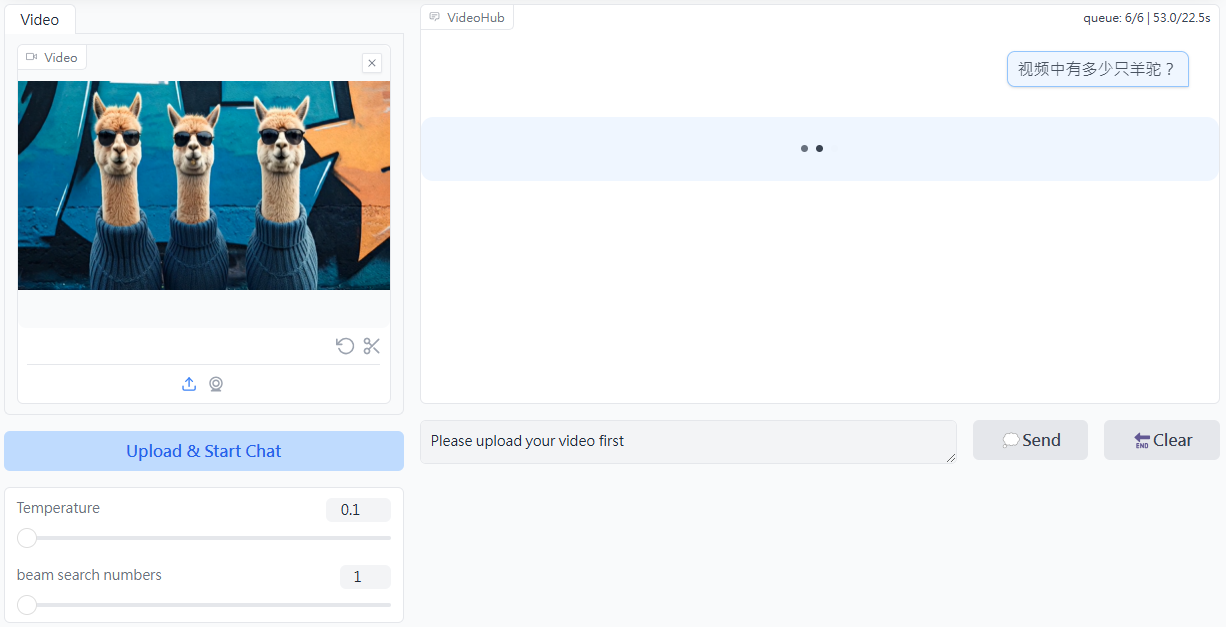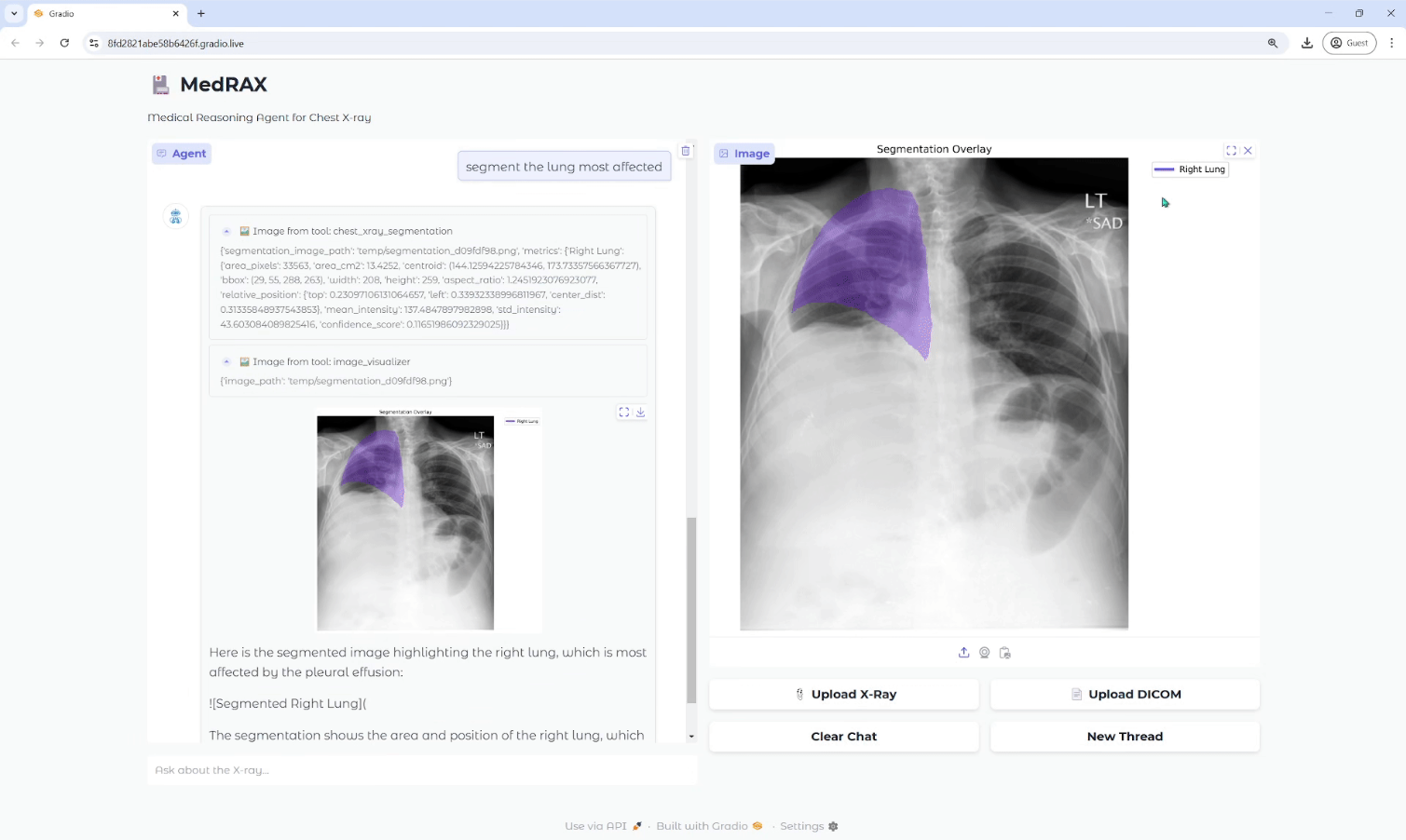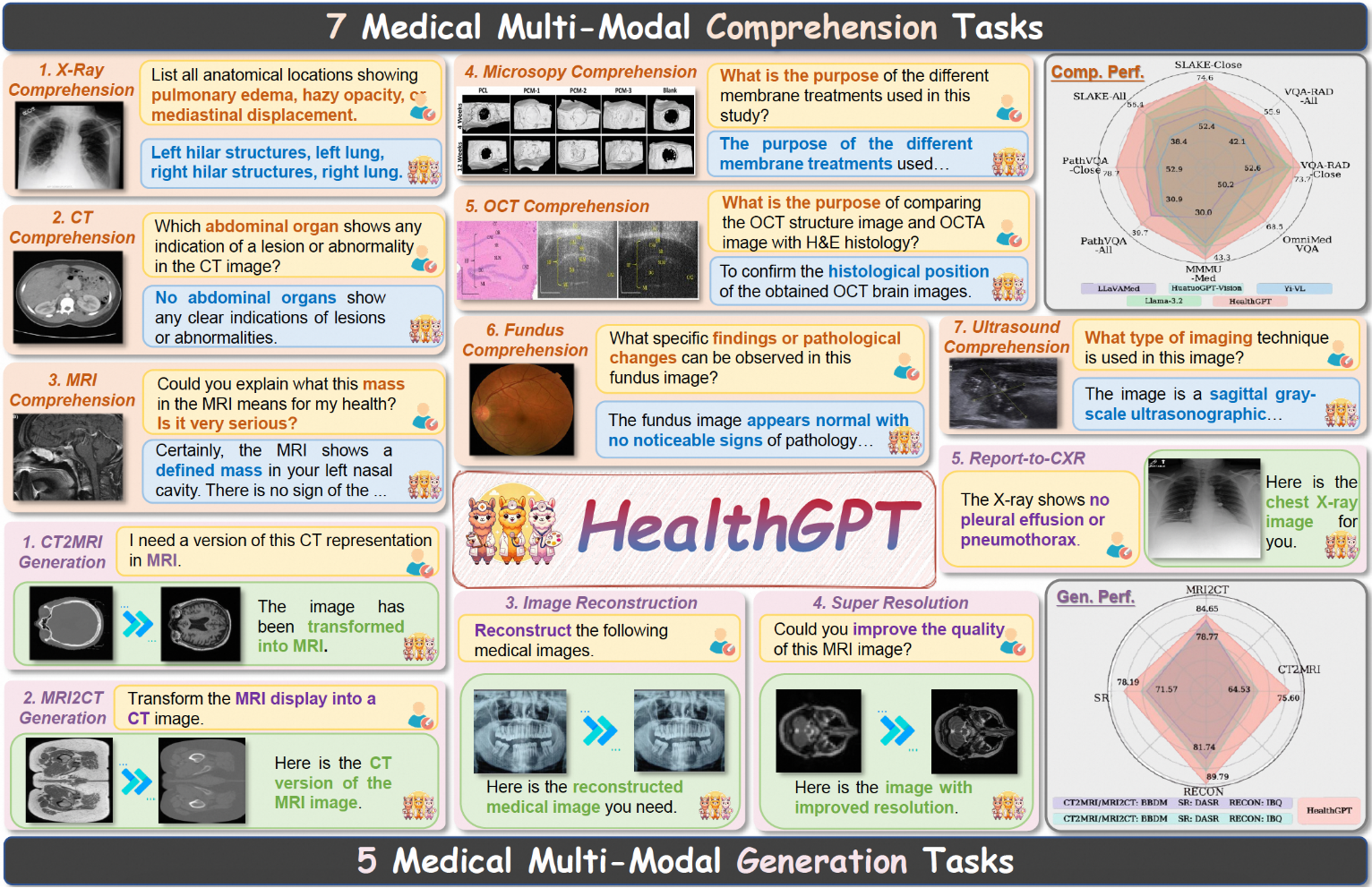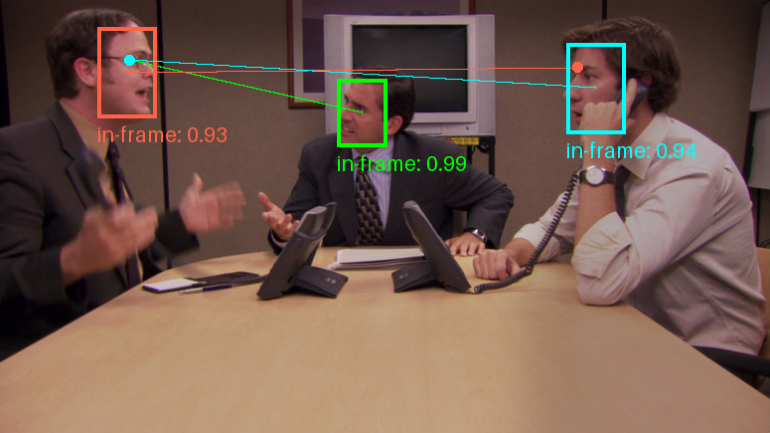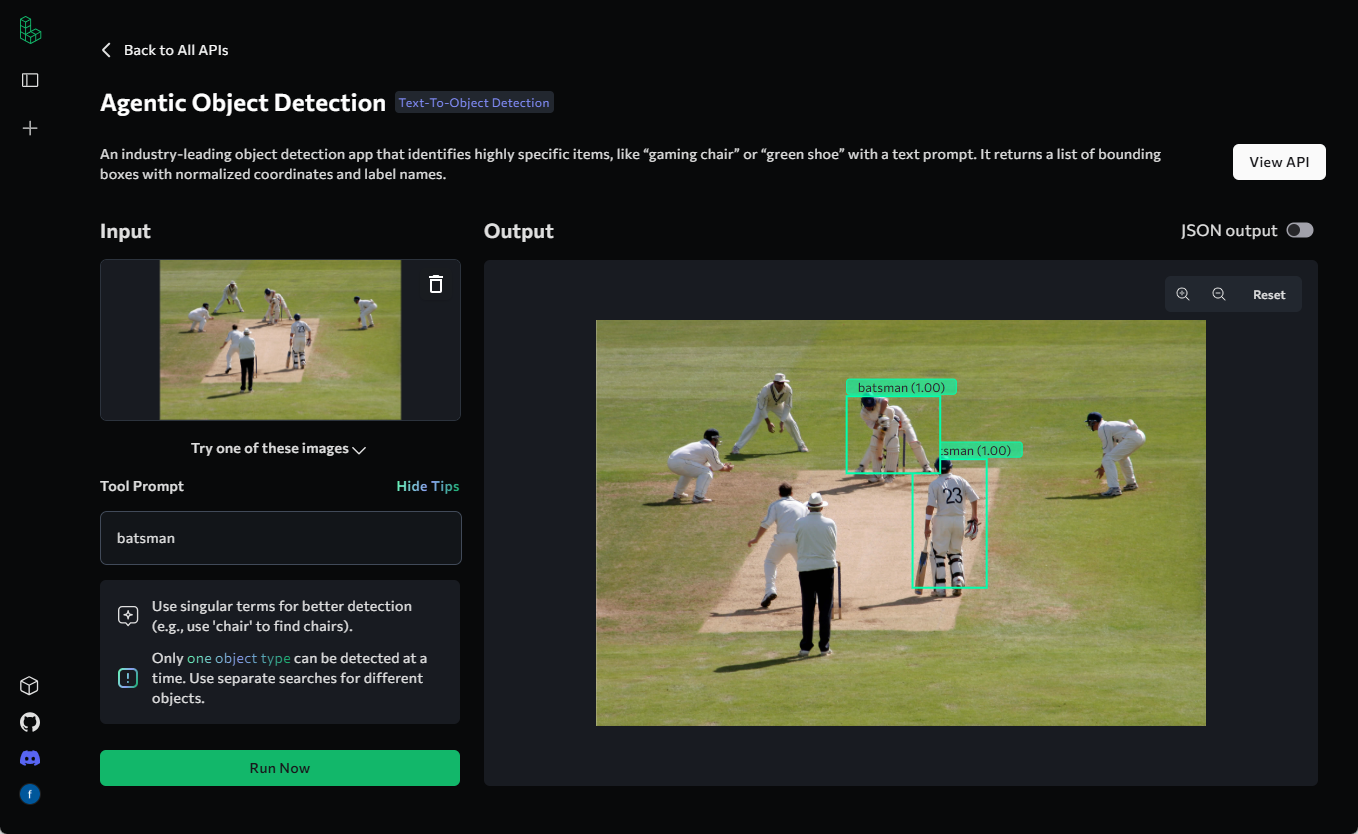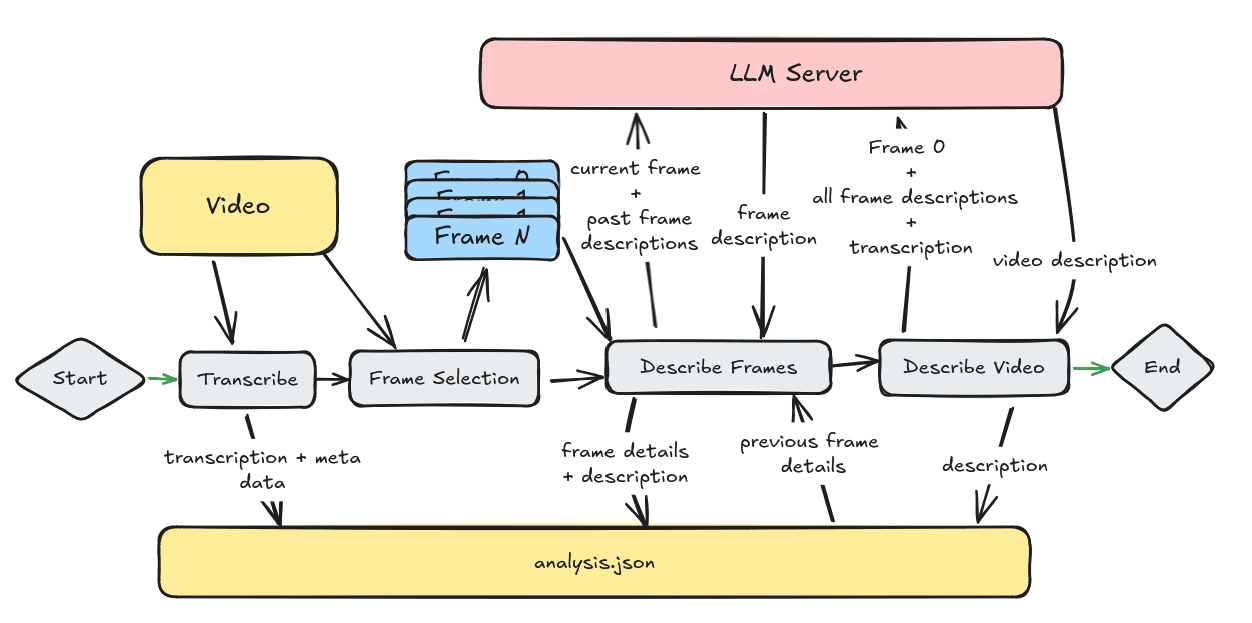
Видеоанализатор: анализирует видеоконтент и создает подробные описания
Comprehensive Introduction Video Analyzer - это инструмент комплексного анализа видео, сочетающий компьютерное зрение, транскрипцию аудио и методы обработки естественного языка для создания подробных описаний видеоконтента. Инструмент расшифровывает аудиоконтент, извлекая ключевые кадры из видео...