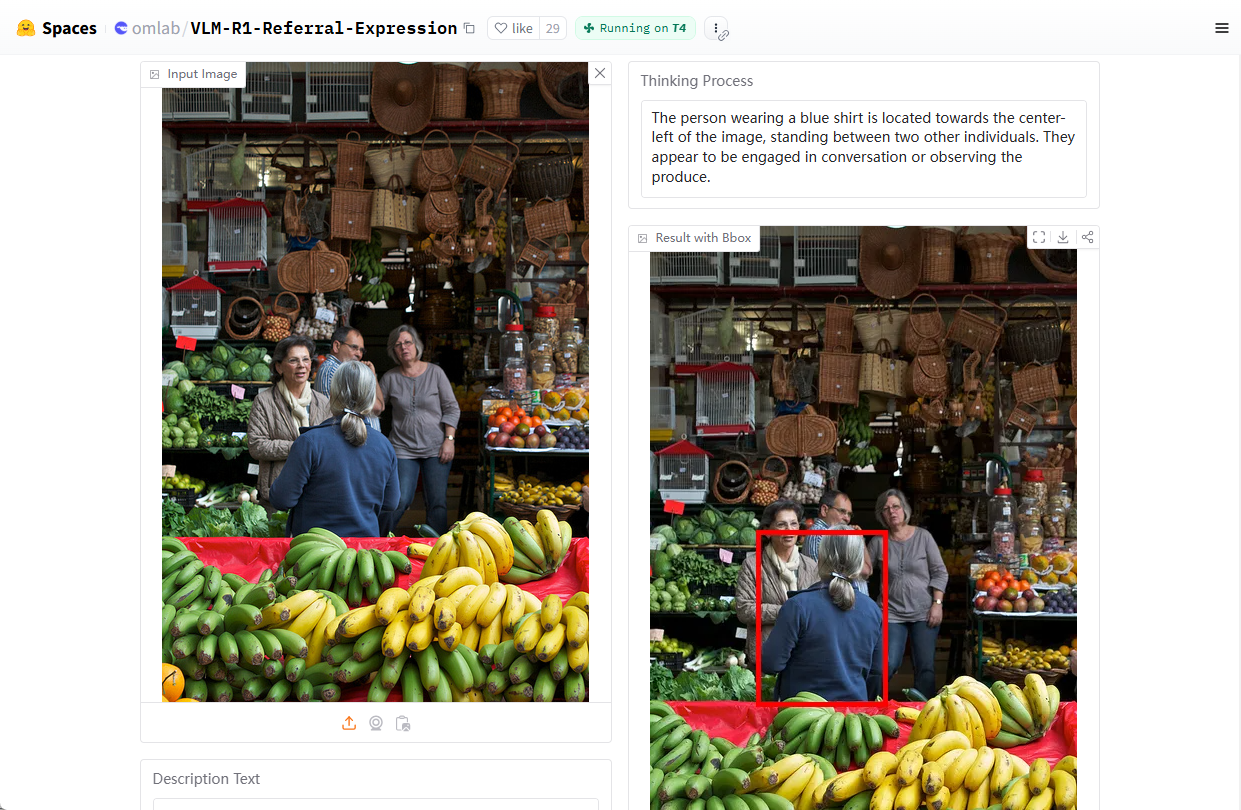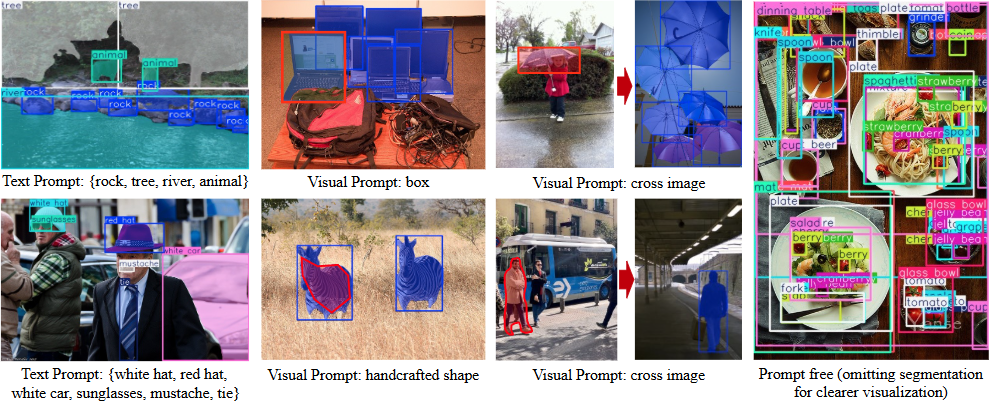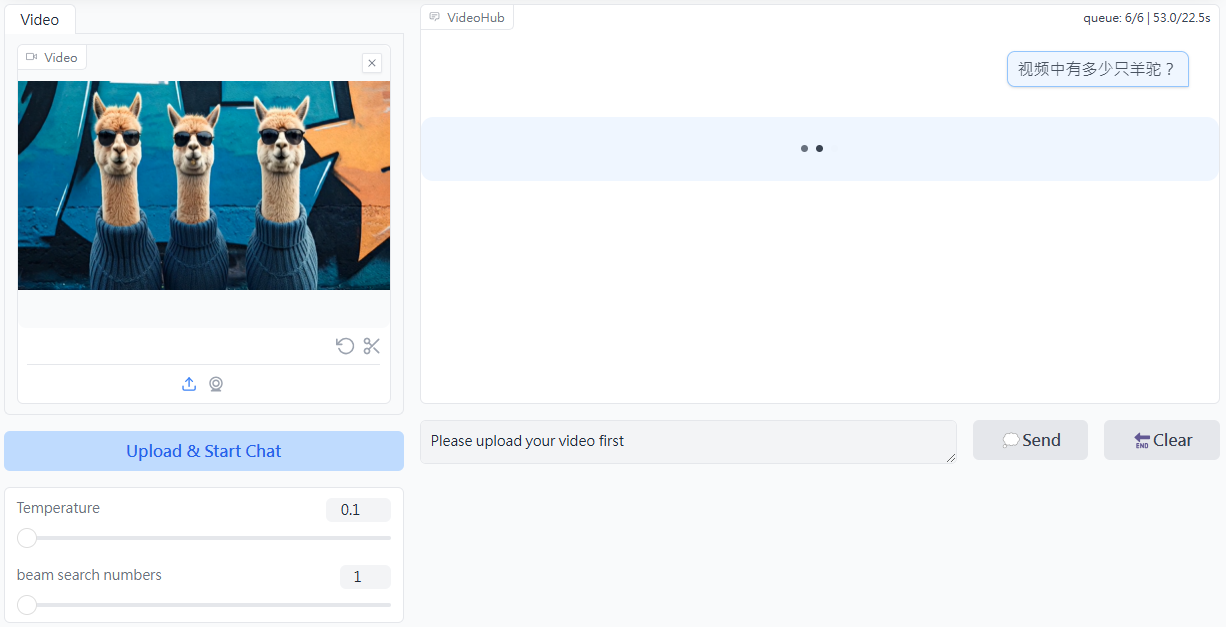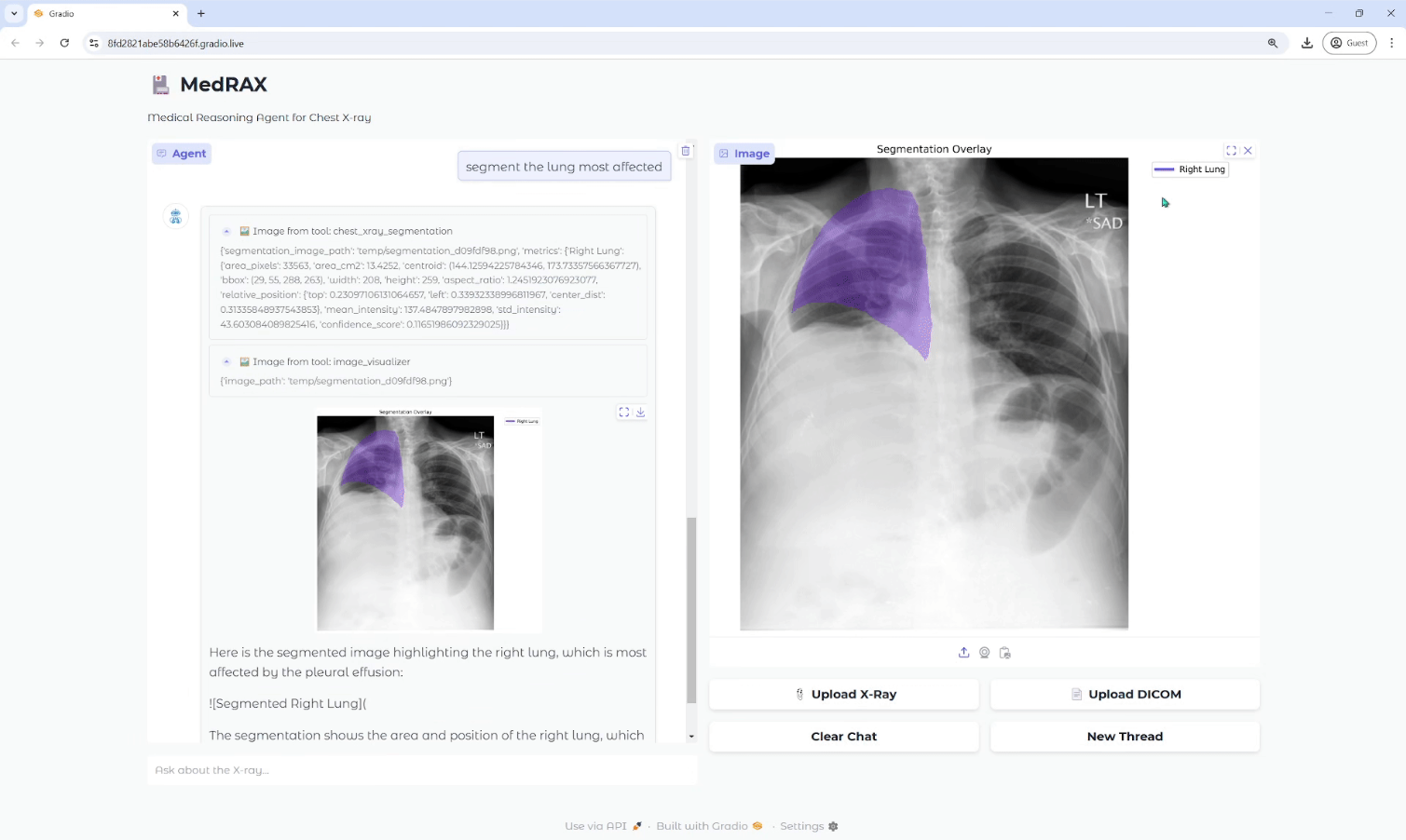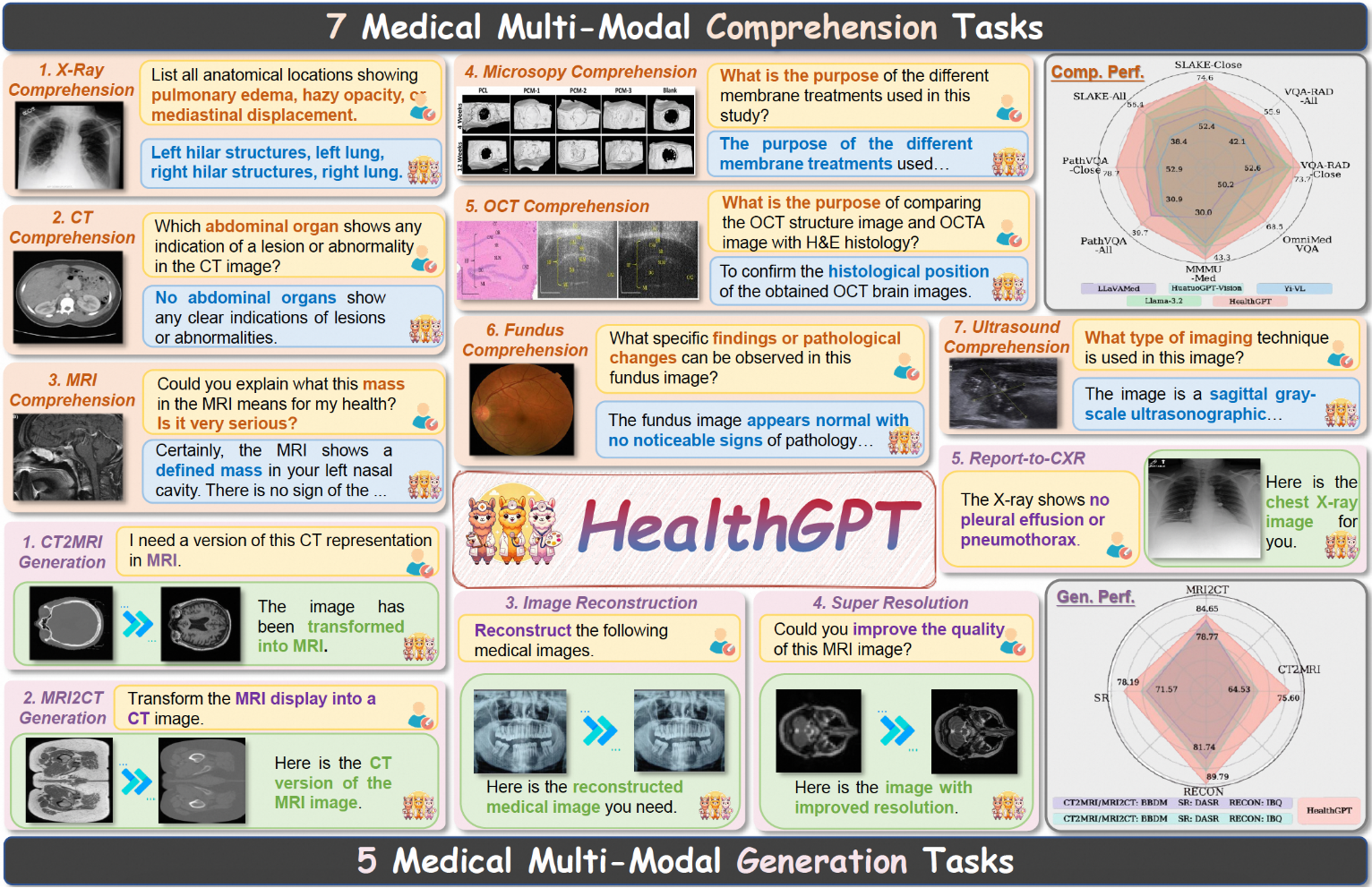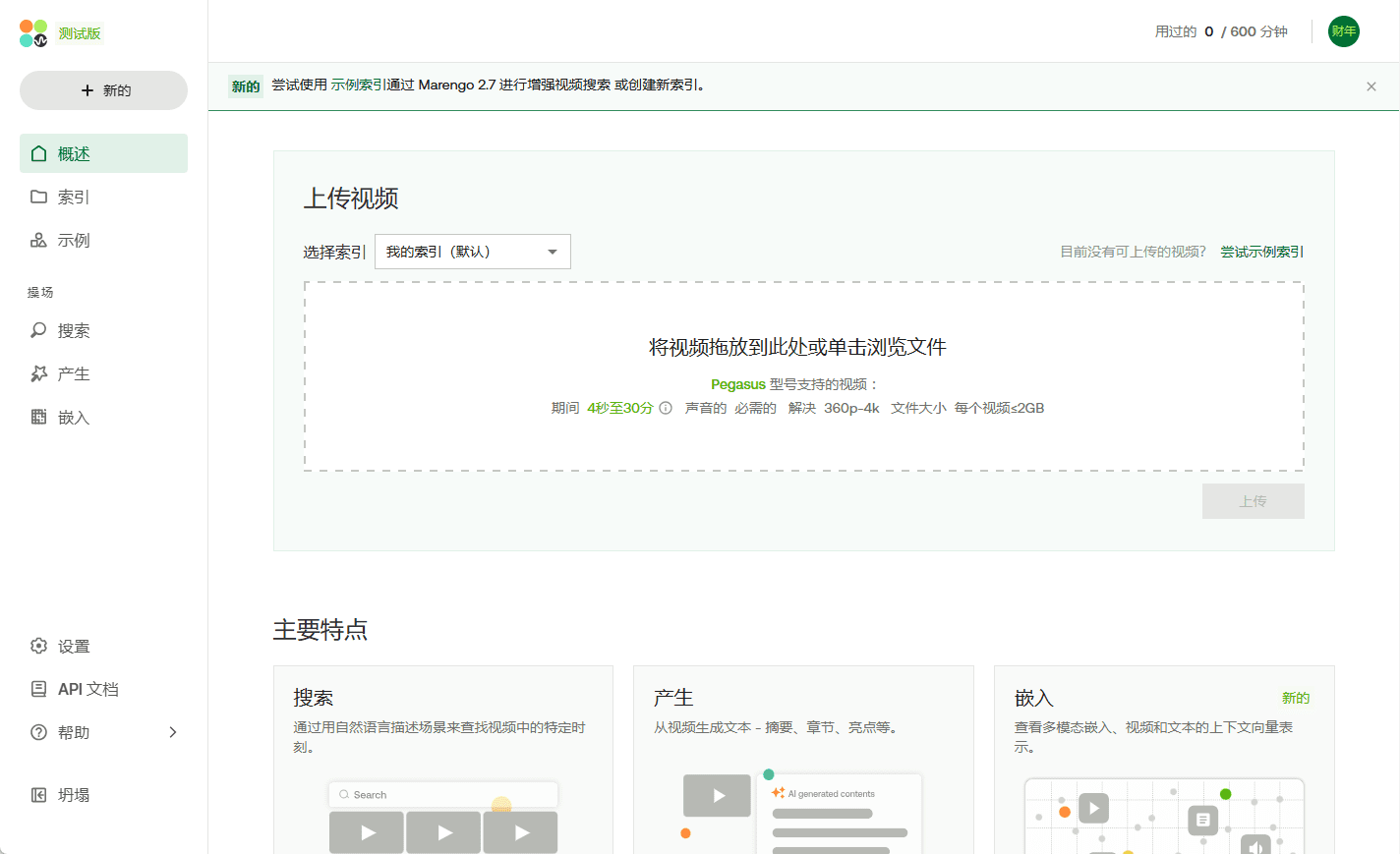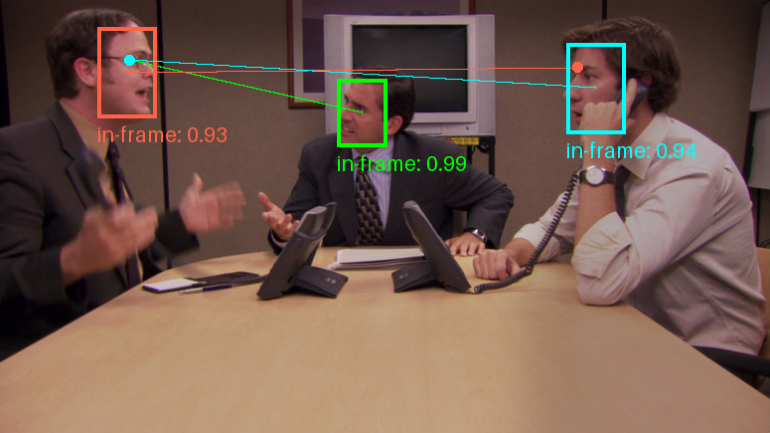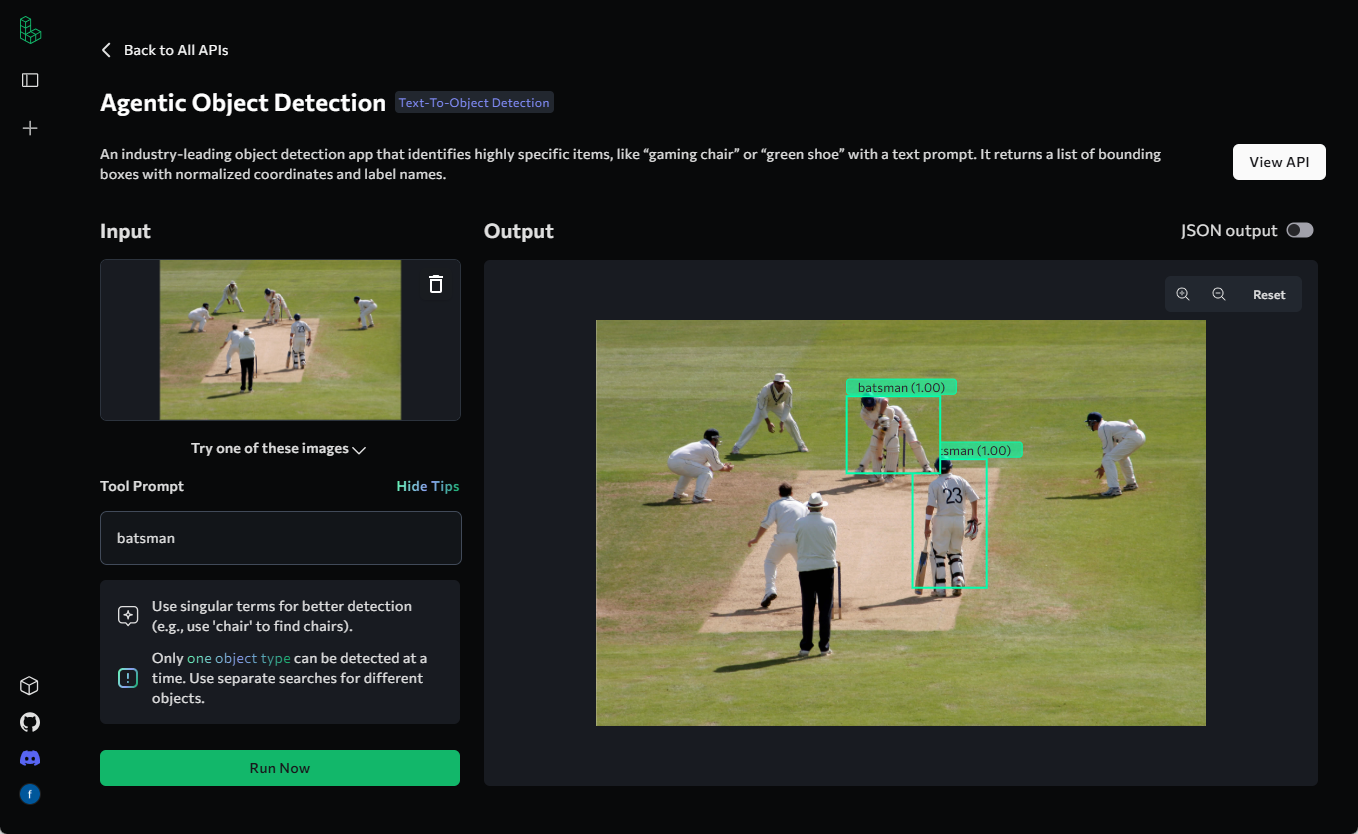
Analizador de vídeo: analiza el contenido de los vídeos y genera descripciones detalladas.
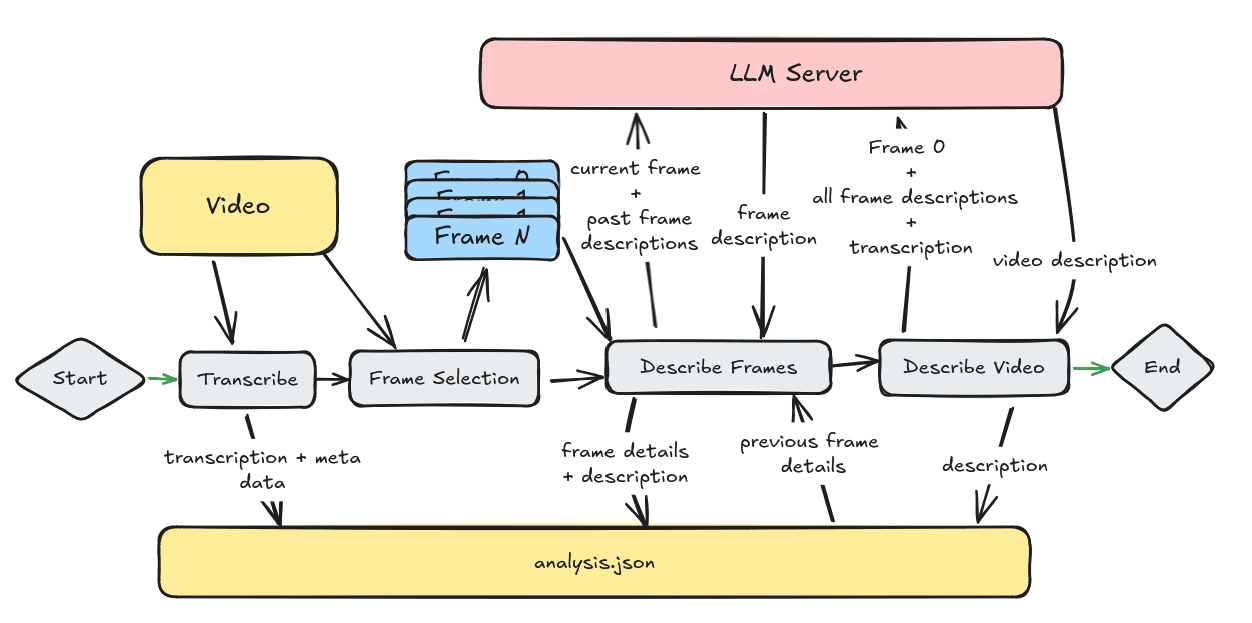
Comprehensive Introduction Video Analyzer es una completa herramienta de análisis de vídeo que combina técnicas de visión por ordenador, transcripción de audio y procesamiento del lenguaje natural para generar descripciones detalladas del contenido del vídeo. La herramienta transcribe el contenido de audio extrayendo fotogramas clave del vídeo....