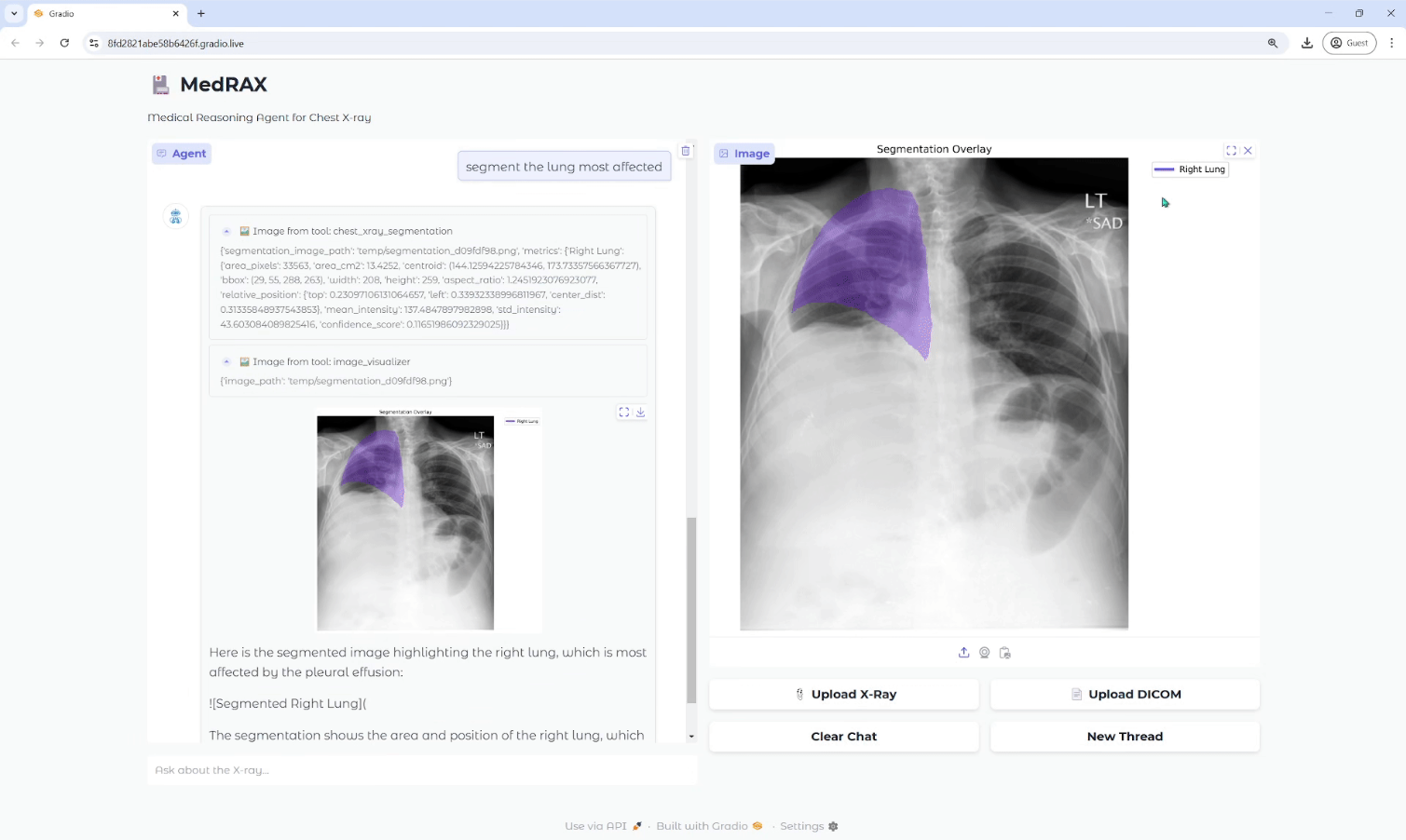
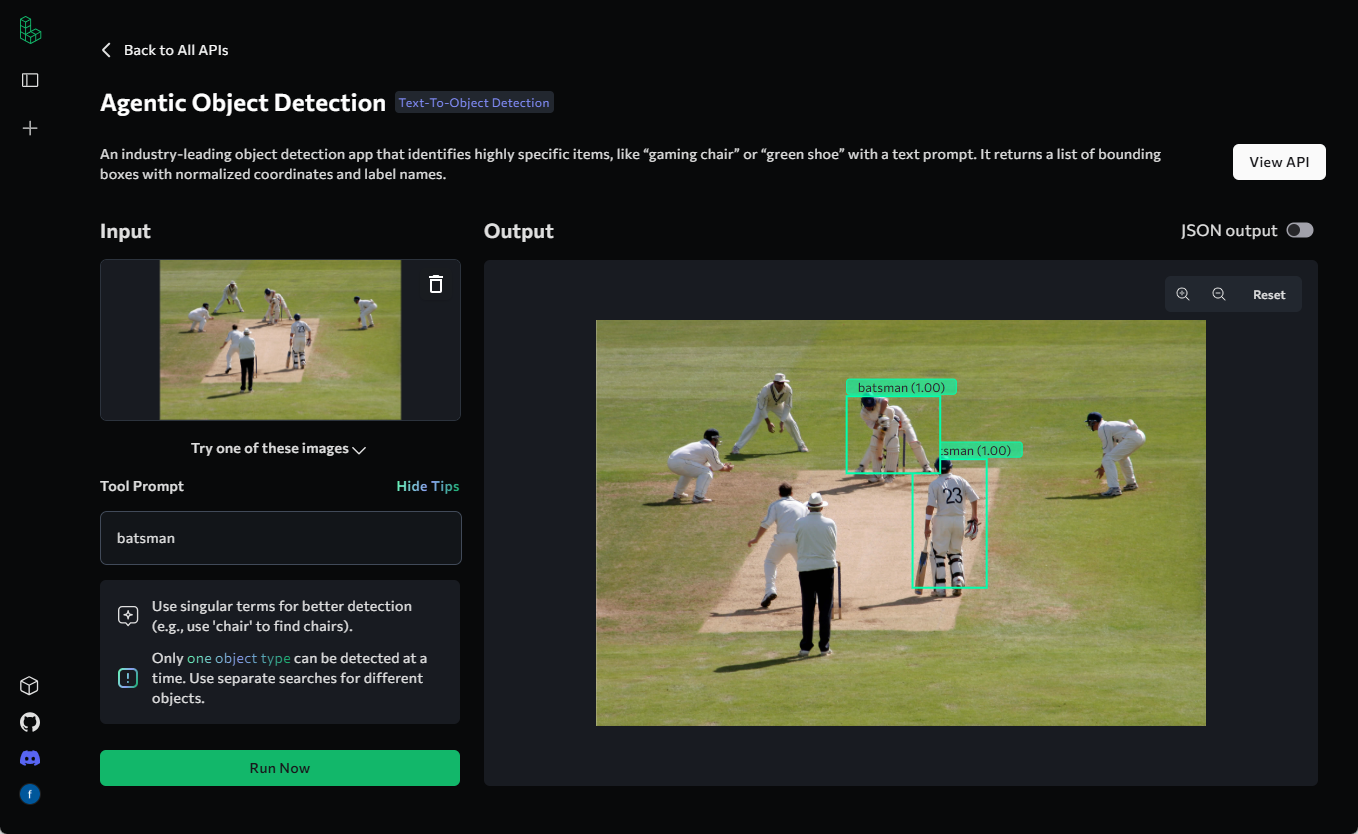
일반 소개 Make Sense는 사용자가 컴퓨터 비전 프로젝트를 위한 데이터 세트를 빠르게 준비할 수 있도록 설계된 무료 온라인 이미지 주석 도구입니다. 복잡한 설치 없이 브라우저에 액세스하기만 하면 사용할 수 있고, 여러 운영 체제를 지원하며, 소규모 딥 러닝 프로젝트에 이상적입니다. 사용자는 다음을 수행할 수 있습니다.
종합 소개 RF-DETR은 Roboflow 팀에서 개발한 오픈 소스 객체 감지 모델입니다. 트랜스포머 아키텍처를 기반으로 하며 핵심 기능은 실시간 효율성입니다. 이 모델은 처음으로 Microsoft COCO 데이터 세트에서 60개 이상의 실시간 AP를 달성했습니다....
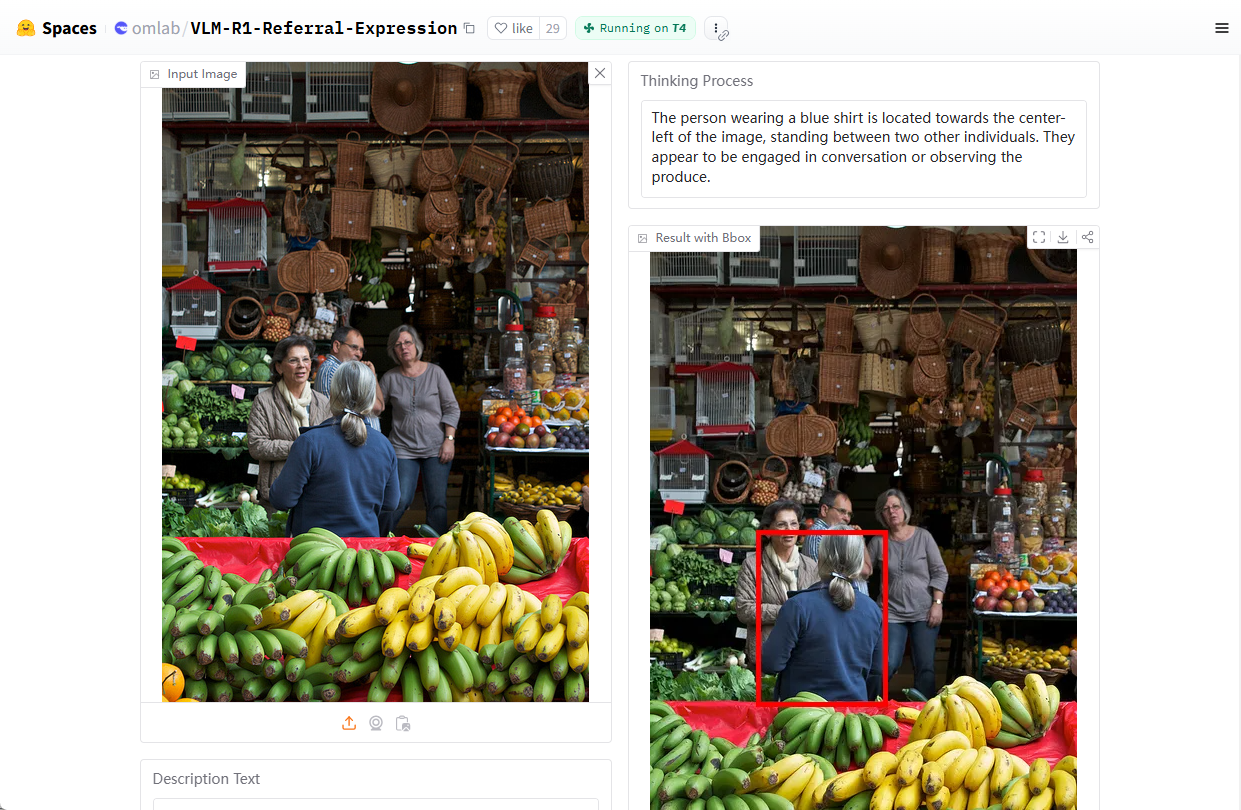
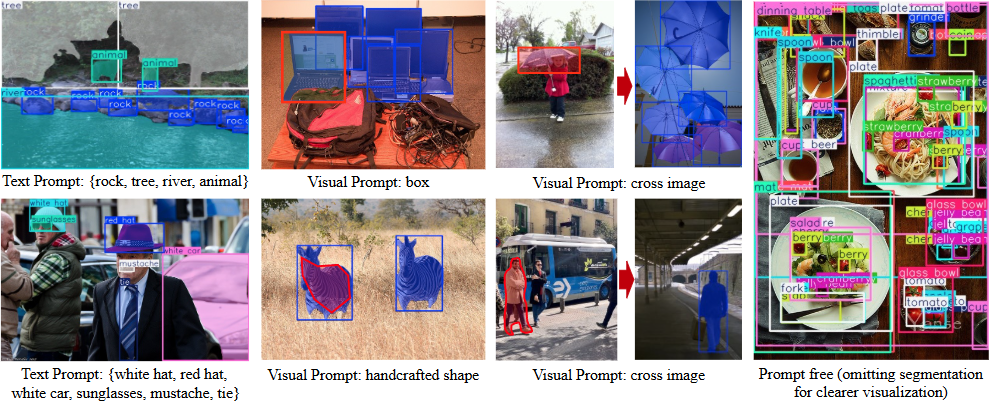
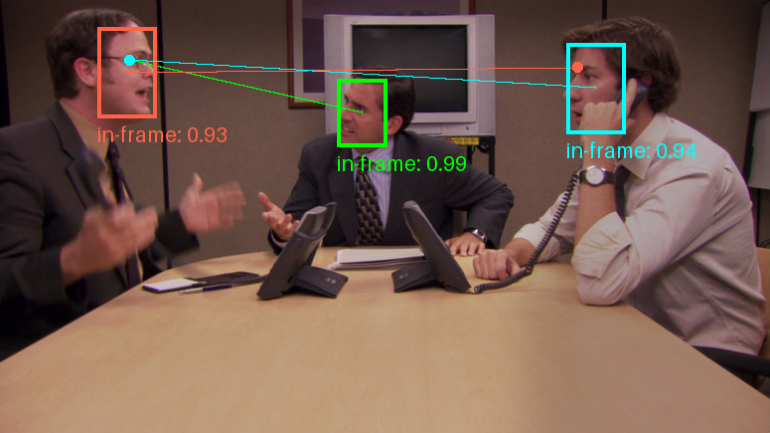
일반 소개 SegAnyMo는 UC 버클리와 북경대학교의 연구팀이 개발한 오픈 소스 프로젝트로, Nan Huang 등의 멤버가 참여하고 있습니다. 이 도구는 동영상 처리에 중점을 두고 있으며 동영상에서 사람, 동물 또는... 등 임의의 움직이는 물체를 자동으로 식별하고 세그먼트화할 수 있습니다.
종합 소개 CogVLM2는 칭화대학교 데이터 마이닝 연구 그룹(THUDM)에서 개발한 오픈 소스 멀티모달 모델로, Llama3-8B 아키텍처를 기반으로 하며 GPT-4V와 비슷하거나 더 나은 성능을 제공하는 것을 목표로 합니다. 이 모델은 이미지 이해, 다원 대화, 시각적 ...
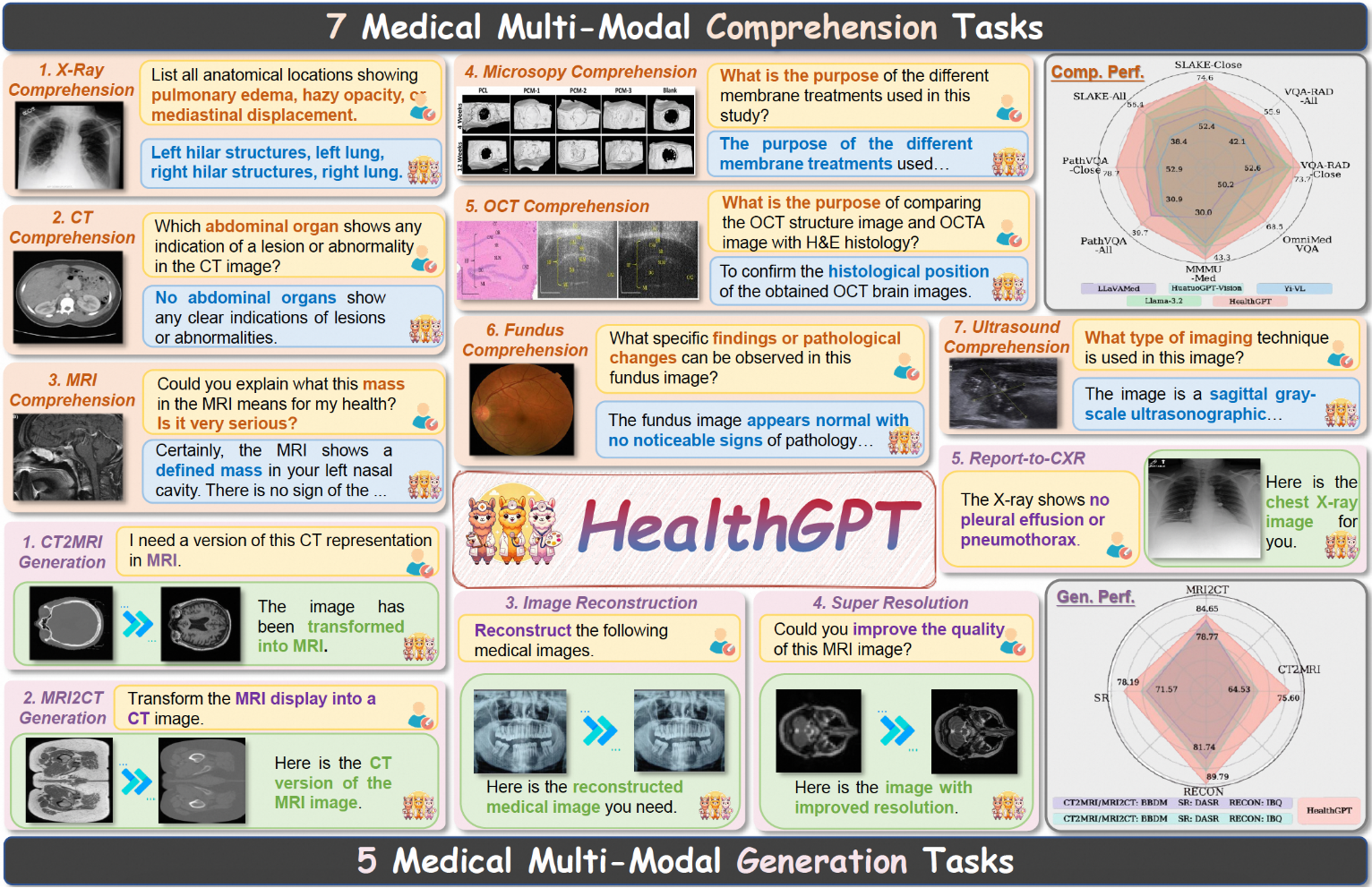
종합 소개 HealthGPT는 이기종 지식 적응을 통해 통합된 의료 시각적 이해 및 생성 기능을 달성하는 것을 목표로 하는 고급 의료 그랜드 비주얼 언어 모델입니다. 이 프로젝트의 목표는 의료 시각적 이해 및 생성 기능을 통합된 자동 회귀 프레임워크에 통합하여 의료 그래프를 크게 개선하는 것입니다.
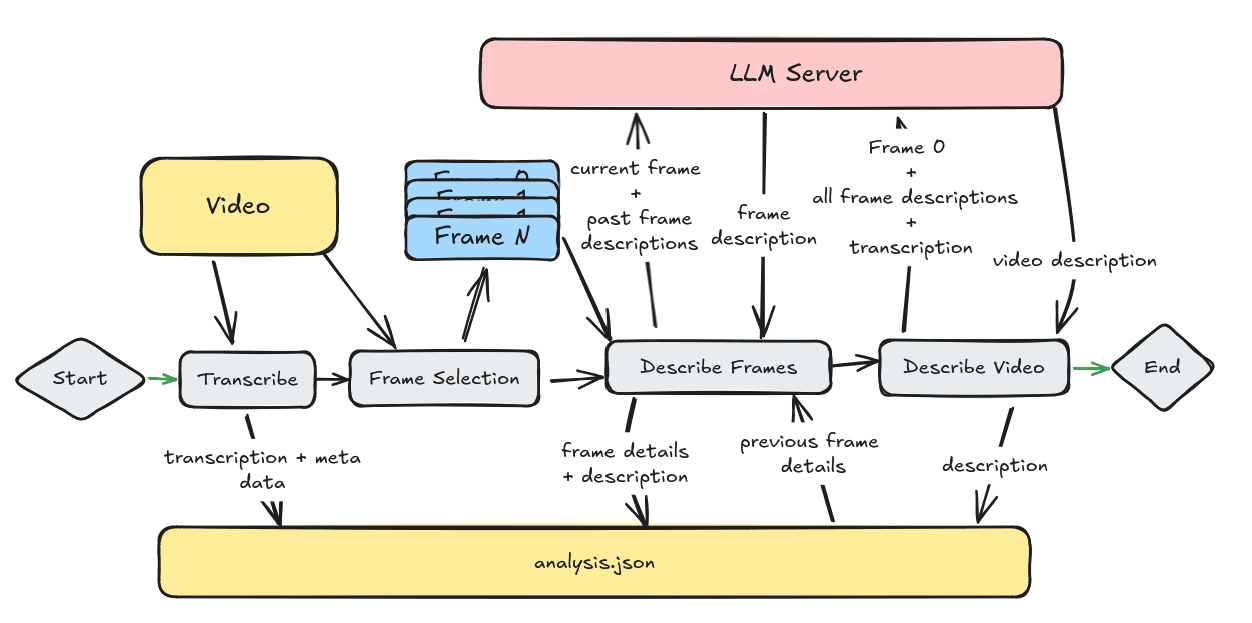
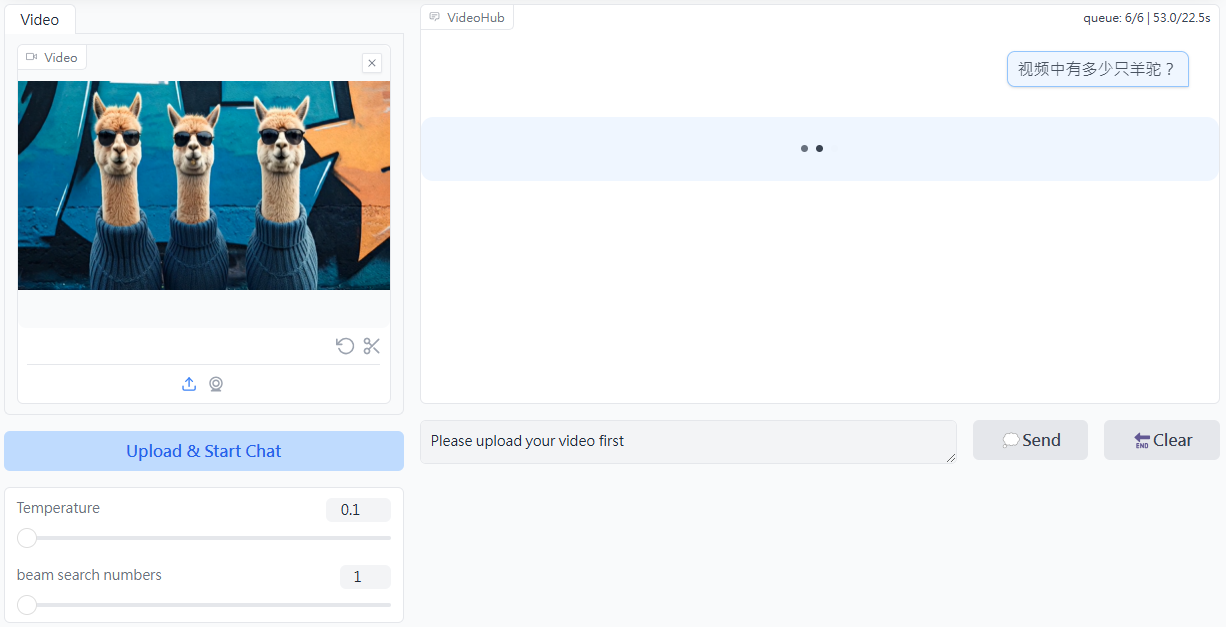
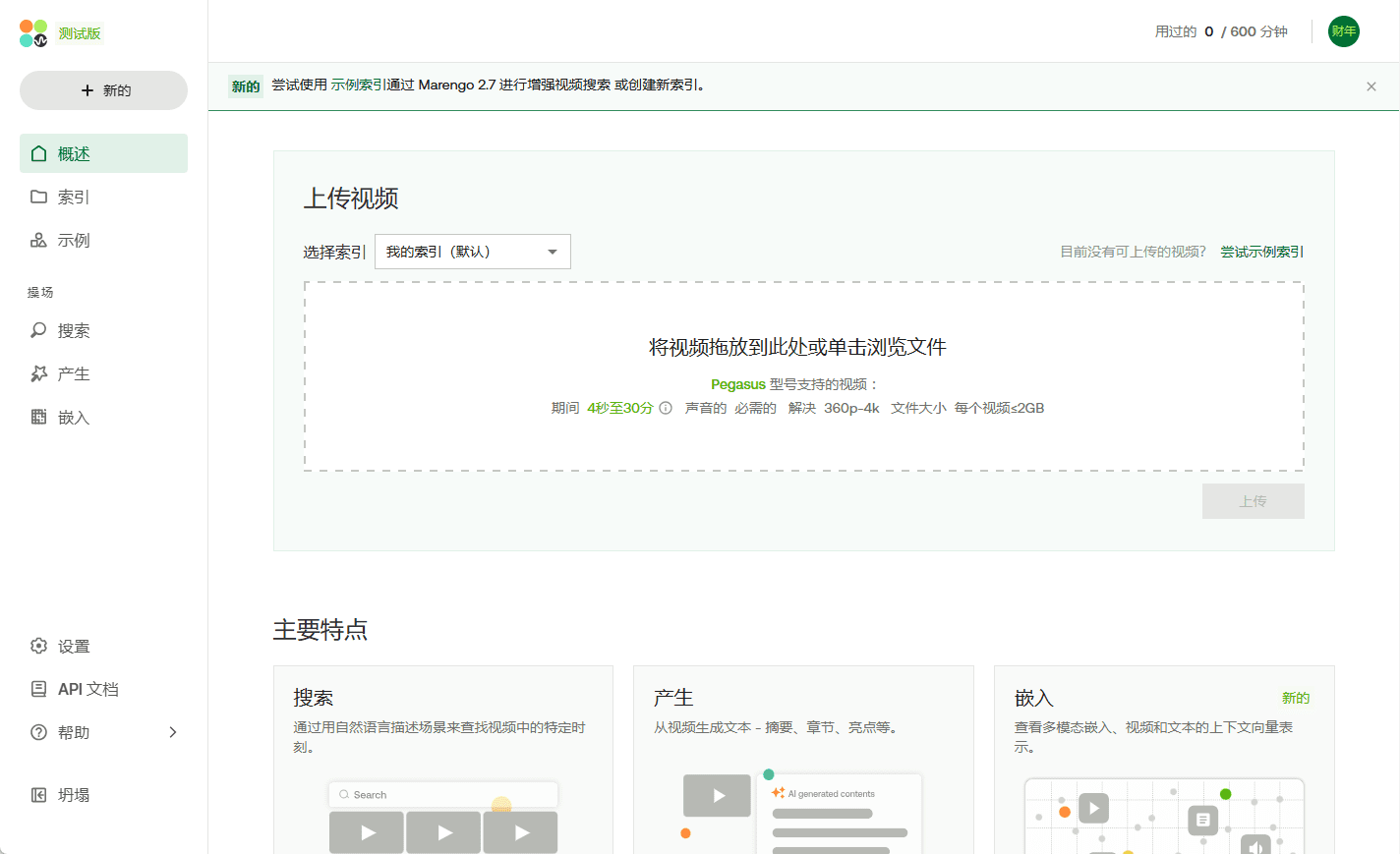
회사 소개 Twelve Labs는 동영상 이해에 중점을 둔 멀티모달 AI 회사로, 고급 AI 기술을 통해 사용자가 대량의 동영상 콘텐츠를 이해하고 처리할 수 있도록 돕는 데 전념하고 있습니다. 핵심 기술로는 동영상 검색, 생성, 임베딩이 있으며, 동영상에서 동작, 사물 등 주요 특징을 추출할 수 있습니다.