

综合介绍
RAGFlow 是一个开源的检索增强生成(RAG)引擎,基于深度文档理解技术。它为各种规模的企业提供了一个高效的 RAG 工作流,结合了大型语言模型(LLM),能够提供基于复杂格式数据的真实问答能力。RAGFlow 支持多种数据源,包括文档、幻灯片、电子表格、文本、图像和结构化数据,确保从海量数据中提取有价值的信息。其主要特点包括模板化分块、减少幻觉的引用、兼容异构数据源等。

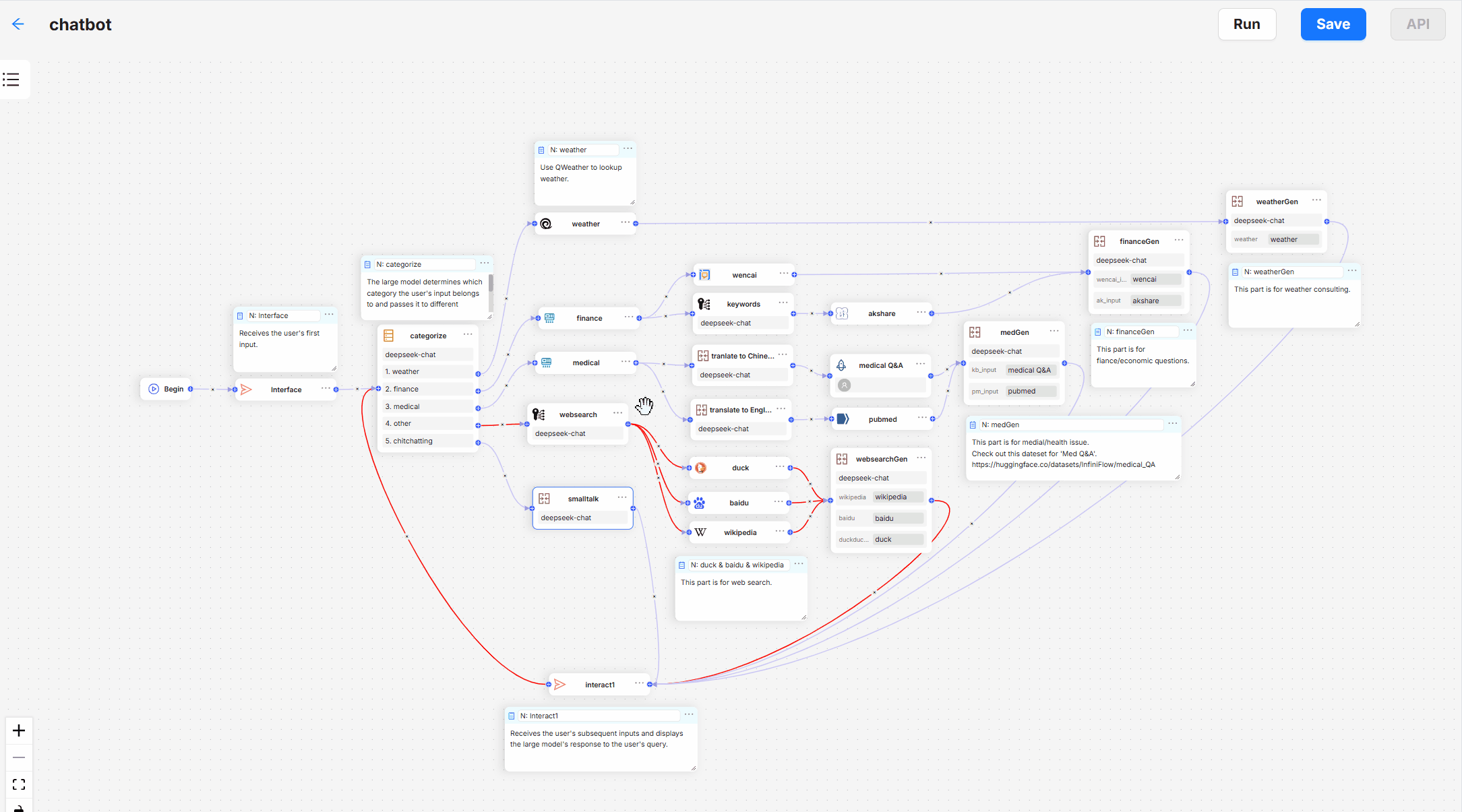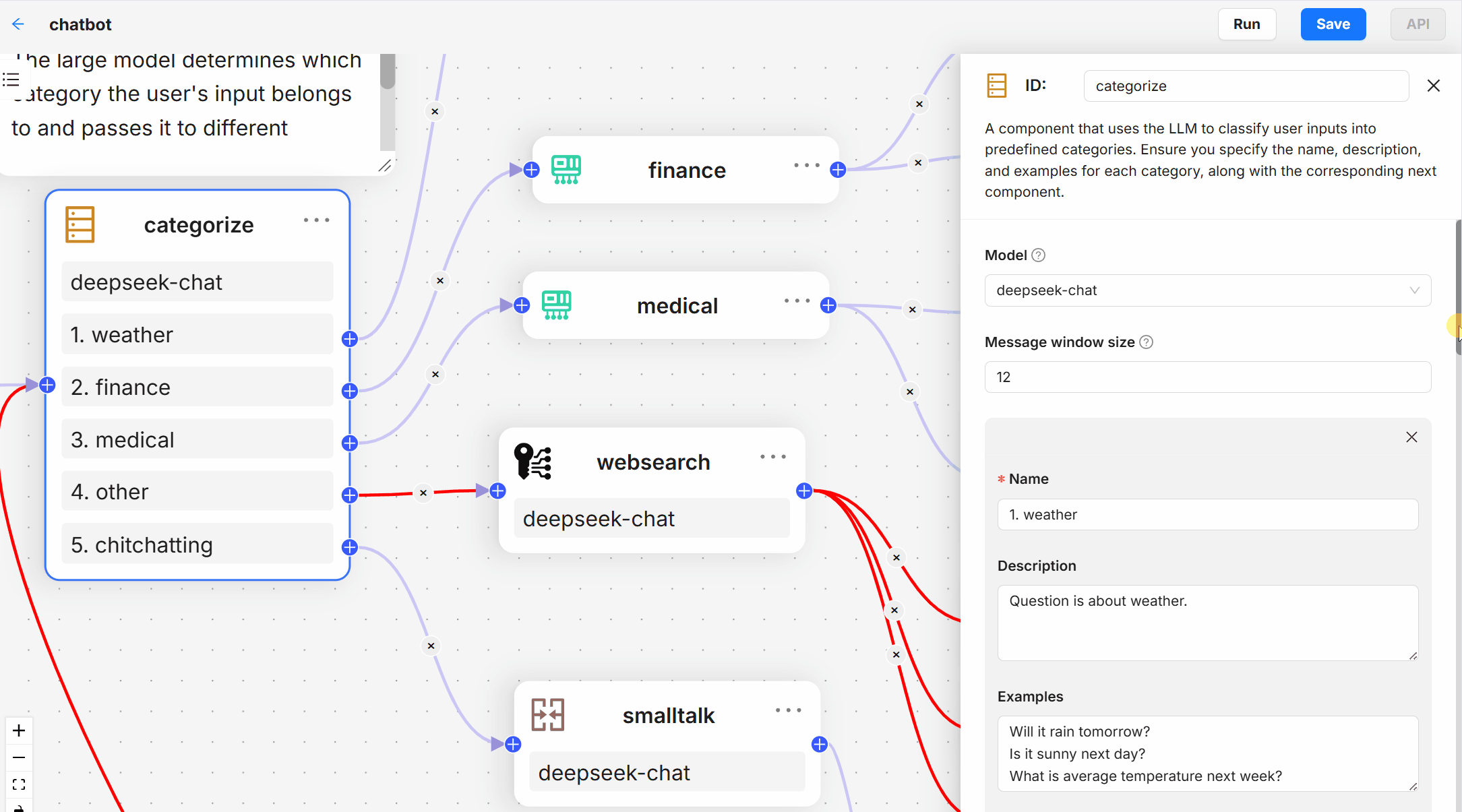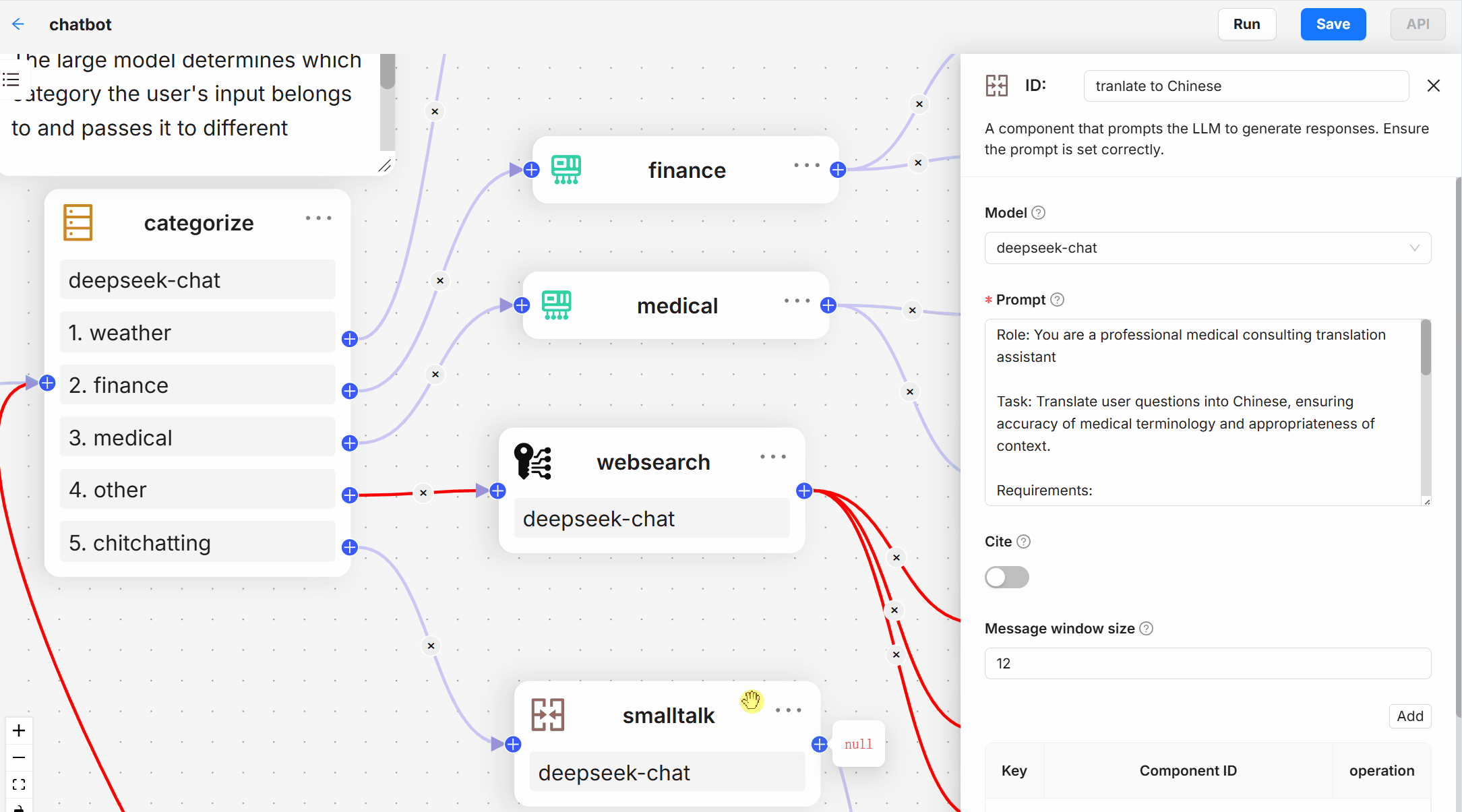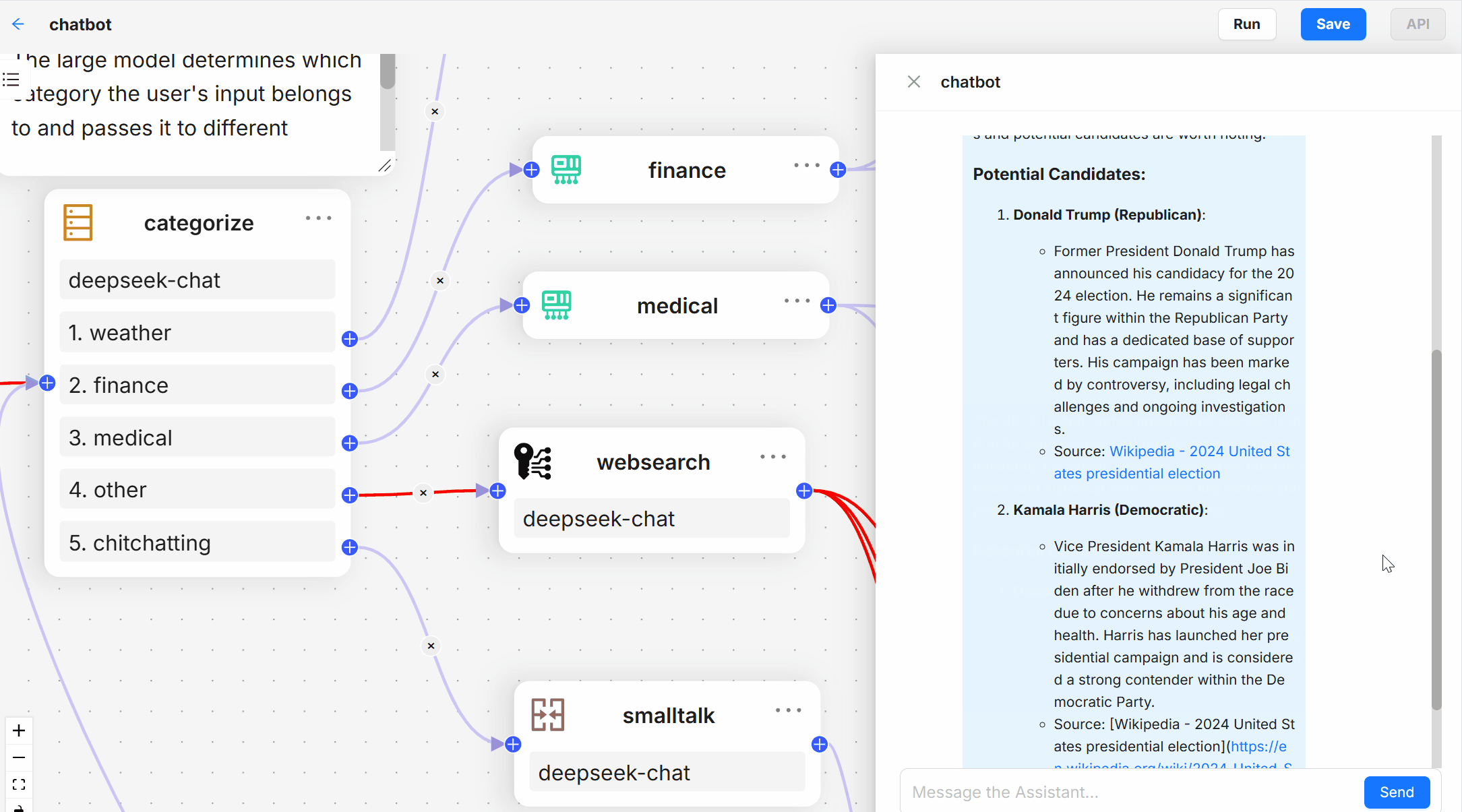
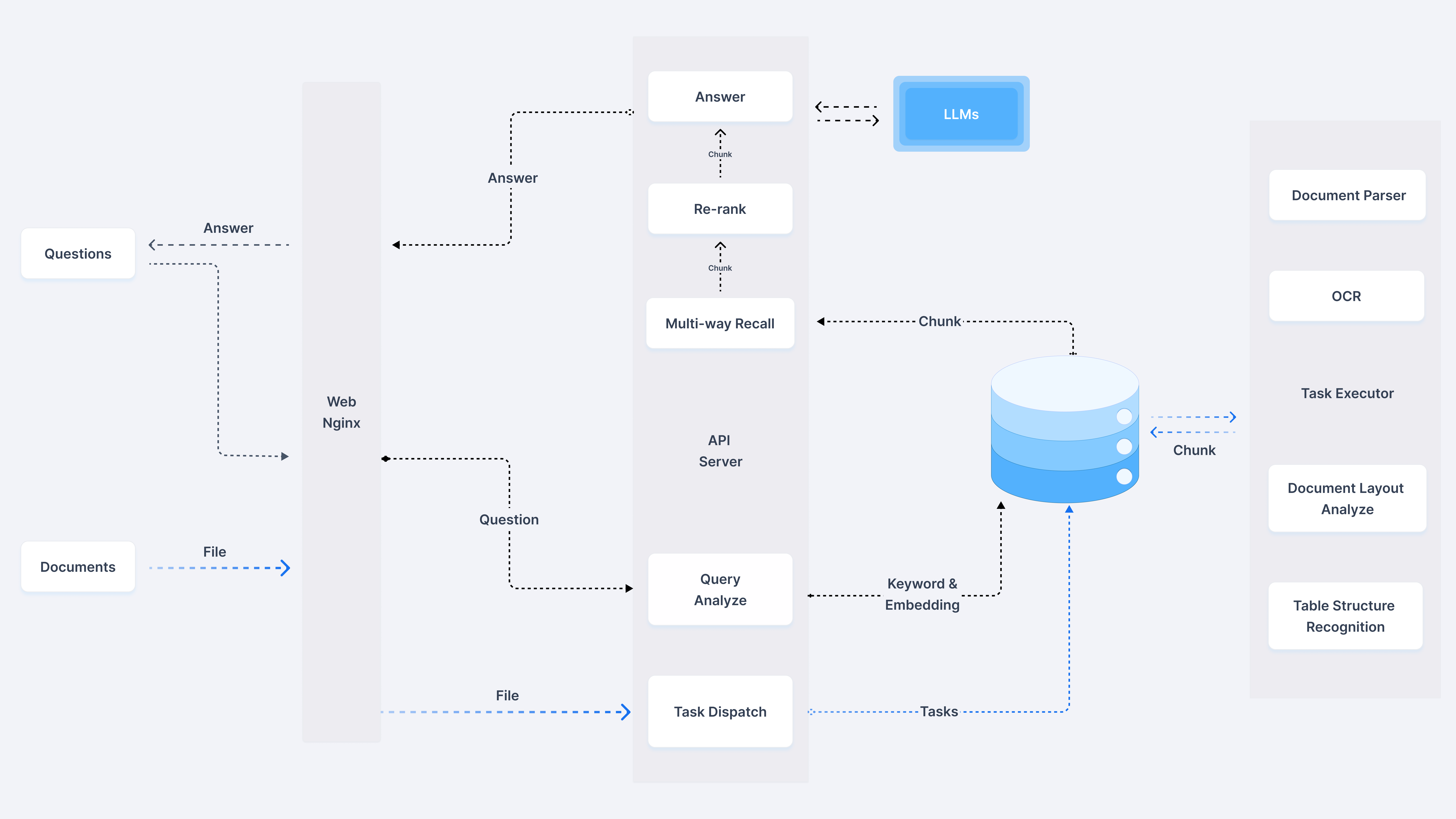
功能列表
- 深度文档理解:基于复杂格式的非结构化数据进行知识提取。
- 模板化分块:提供多种模板选项,智能且可解释。
- 引用可视化:支持文本分块可视化,便于人工干预,快速查看关键引用。
- 兼容多种数据源:支持Word、幻灯片、Excel、文本、图像、扫描件、结构化数据、网页等。
- 自动化RAG工作流:为个人和大型企业提供流畅的RAG编排,支持多种召回和重排序。
- 直观的API:便于与业务系统无缝集成。
使用帮助
安装流程
- 系统要求:
- CPU:至少4核
- 内存:至少16GB
- 硬盘:至少50GB
- Docker:版本24.0.0及以上
- Docker Compose:版本v2.26.1及以上
- 安装Docker:
- Windows、Mac或Linux用户可以参考Docker安装指南。
- 克隆RAGFlow仓库:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow
- 构建Docker镜像:
- 不包含嵌入模型的镜像:
docker build -t ragflow .- 包含嵌入模型的镜像:
docker build -f Dockerfile.deps -t ragflow . - 启动服务:
docker-compose up
使用指南
- 配置:
- 在
conf目录下修改配置文件,设置数据源路径、模型参数等。
- 在
- 启动服务:
- 使用上述命令启动服务后,可以通过API进行交互。
- 主要功能操作:
- 文档上传:将需要处理的文档上传至指定目录。
- 数据处理:系统会自动对文档进行分块、解析和知识提取。
- 问答系统:通过API发送问题,系统会基于文档内容生成答案,并提供引用。
- 示例操作:
- 上传一个Word文档:
bash
curl -F "file=@/path/to/document.docx" http://localhost:8000/upload - 提问:
bash
curl -X POST -H "Content-Type: application/json" -d '{"question": "文档的主要内容是什么?"}' http://localhost:8000/ask
- 上传一个Word文档:
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...