
综合介绍
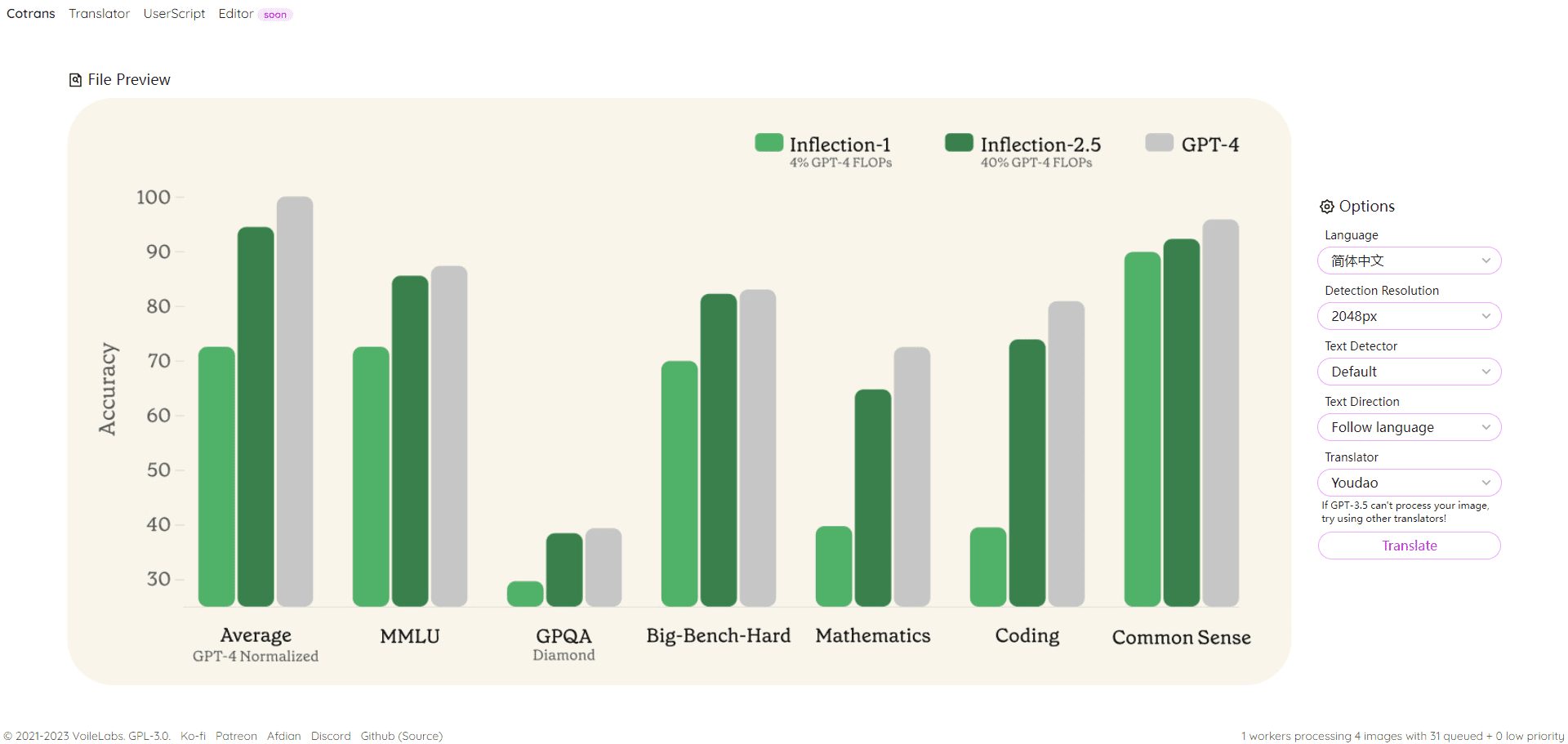
R1-Onevision 是一个由 Fancy-MLLM 团队开发的开源多模态大语言模型,专注于视觉与语言的深度结合,能够处理图像、文本等多模态输入,并在视觉推理、图像理解、数学解题等领域表现出色。基于 Qwen2.5-VL 模型优化,R1-Onevision 在多个基准测试中超越了同类模型如 Qwen2.5-VL-7B,甚至挑战了 GPT-4V 的能力。项目托管于 GitHub,提供模型权重、数据集及代码,适合开发者、研究人员用于学术探索或实际应用。2025年2月24日发布以来,受到广泛关注,尤其在视觉推理任务中表现抢眼。

功能列表
- 多模态推理:支持图像与文本结合的复杂推理任务,如数学题解答、科学问题分析。
- 图像理解:能够分析图片内容并生成详细描述或回答相关问题。
- 数据集支持:提供 R1-Onevision 数据集,包含自然场景、OCR、图表等多领域数据。
- 模型训练:使用开源 LLama-Factory 框架,支持全模型监督微调(SFT)。
- 高性能评估:在 Mathvision、Mathverse 等测试中展现优于同行的推理能力。
- 开源资源:提供模型权重和代码,方便二次开发或研究。
使用帮助
安装流程
R1-Onevision 是一个基于 GitHub 的开源项目,需要一定的编程基础和环境配置才能运行。以下是详细的安装与使用指南:
1. 环境准备
- 操作系统:推荐使用 Linux(如 Ubuntu)或 Windows(配合 WSL)。
- 硬件要求:建议配备 NVIDIA GPU(至少 16GB 显存,如 A100 或 RTX 3090),以支持模型推理和训练。
- 依赖软件:
- Python 3.8 或更高版本。
- PyTorch(推荐安装 GPU 版本,参考 PyTorch 官网)。
- Git(用于克隆代码仓库)。
2. 克隆仓库
打开终端,运行以下命令获取 R1-Onevision 项目代码:
git clone https://github.com/Fancy-MLLM/R1-Onevision.git
cd R1-Onevision
3. 安装依赖
项目依赖多个 Python 库,可通过以下命令安装:
pip install -r requirements.txt
若需要加速推理,推荐安装 Flash Attention:
pip install flash-attn --no-build-isolation
4. 下载模型权重
R1-Onevision 提供预训练模型,可从 Hugging Face 下载:
- 访问 Hugging Face 模型页面。
- 下载模型文件(如
R1-Onevision-7B)并解压至项目目录下的models文件夹(需手动创建)。
5. 配置环境
确保 CUDA 已正确安装并与 PyTorch 兼容,可运行以下代码验证:
import torch
print(torch.cuda.is_available()) # 输出 True 表示 GPU 可用
使用方法
基础推理:图像与文本分析
R1-Onevision 支持通过 Python 脚本运行推理任务。以下是加载模型并处理图像与文本的示例:
- 编写推理脚本:
在项目根目录下创建一个文件(如infer.py),输入以下代码:
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
import torch
from qwen_vl_utils import process_vision_info
# 加载模型和处理器
MODEL_ID = "models/R1-Onevision-7B" # 替换为模型实际路径
processor = AutoProcessor.from_pretrained(MODEL_ID, trust_remote_code=True)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
MODEL_ID, trust_remote_code=True, torch_dtype=torch.bfloat16
).to("cuda").eval()
# 输入图像和文本
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "path/to/your/image.jpg"}, # 替换为本地图像路径
{"type": "text", "text": "请描述这张图片的内容并回答:图中有几个人?"}
]
}
]
# 处理输入
inputs = processor(messages, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=512)
response = processor.decode(outputs[0], skip_special_tokens=True)
print(response)
- 运行脚本:
python infer.py
脚本将输出图像描述和回答。例如,若图片中有两人,模型可能返回:“图片显示一个公园场景,有两个人坐在长椅上。”
特色功能:数学推理
R1-Onevision 在数学视觉推理上表现突出。假设有一张包含数学题的图片(如“2x + 3 = 7,求 x”),可按以下步骤操作:
- 修改
messages中的文本为:“请解答这张图片中的数学题,并给出计算过程。” - 运行脚本,模型将返回类似以下结果:
图片中的题目是:2x + 3 = 7
解题过程:
1. 两边同时减去 3:2x + 3 - 3 = 7 - 3
2. 简化得:2x = 4
3. 两边同时除以 2:2x / 2 = 4 / 2
4. 得出:x = 2
最终答案:x = 2
数据集使用
R1-Onevision 提供专用数据集,可用于模型微调或测试:
- 下载数据集:Hugging Face 数据集页面。
- 数据包含图像和文本对,解压后可直接用于训练或验证。
模型微调
若需自定义模型,可使用 LLama-Factory 进行监督微调:
- 安装 LLama-Factory:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt
- 配置训练参数(参考项目文档),运行:
python train.py --model_name models/R1-Onevision-7B --dataset path/to/dataset
操作流程总结
- 图像分析:准备图像路径,编写脚本,运行获取结果。
- 数学推理:上传题目图片,输入问题,查看详细解答。
- 自定义开发:下载数据集和模型,调整参数进行训练。
使用时需注意 GPU 内存占用,推荐至少 16GB 显存以确保流畅运行。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...