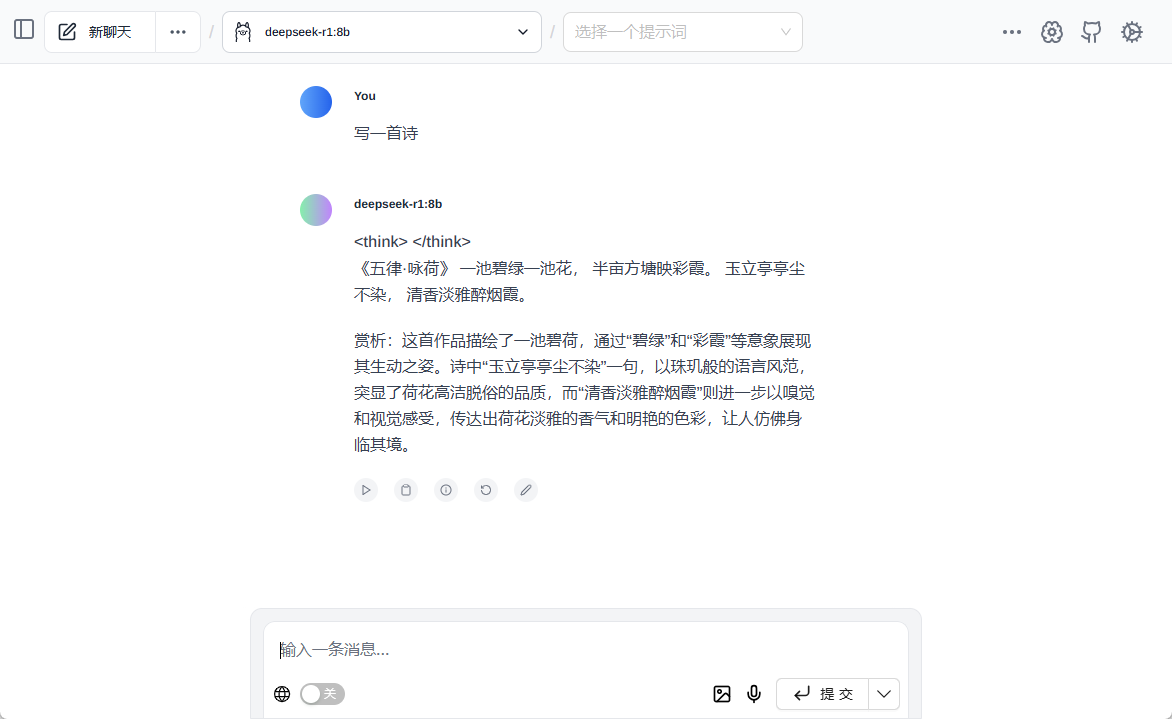

综合介绍
Ovis(Open VISion)是由阿里巴巴国际数字商业集团的 AIDC-AI 团队开发的一款开源多模态大语言模型(MLLM),托管于 GitHub。该模型采用创新的结构嵌入对齐技术,将视觉和文本数据高效融合,支持图像、文本、视频等多模态输入,并生成对应的输出内容。截至 2025 年 3 月,Ovis 已推出 Ovis2 系列(1B 至 34B 参数规模),提供卓越的小模型性能、增强的推理能力以及对高分辨率图像和视频的处理能力。项目面向开发者与研究人员,提供详细文档和代码,强调开源协作,已在社区中获得广泛关注。

功能列表
- 多模态输入支持:处理图像、文本、视频等多种输入类型。
- 视觉文本对齐:生成与图像或视频内容精准匹配的文本描述。
- 高分辨率图像处理:优化支持高分辨率图像,保留细节。
- 视频与多图分析:支持视频帧序列和多张图像的连续处理。
- 增强推理能力:通过指令调优和 DPO 训练提升逻辑推理水平。
- 多语言 OCR 支持:识别并处理多语言图像文本。
- 多种模型选择:提供 1B 至 34B 参数的模型,适配不同硬件。
- 量化版本支持:如 GPTQ-Int4 模型,降低运行门槛。
- Gradio 界面集成:提供直观的网页交互界面。
使用帮助
安装流程
Ovis 的安装依赖特定的 Python 环境和库,以下是详细步骤:
- 环境准备
- 确保安装 Git 和 Anaconda。
- 克隆 Ovis 仓库:
git clone git@github.com:AIDC-AI/Ovis.git - 创建并激活虚拟环境:
conda create -n ovis python=3.10 -y conda activate ovis
- 依赖安装
- 进入项目目录:
cd Ovis - 安装依赖(基于
requirements.txt):pip install -r requirements.txt - 安装 Ovis 包:
pip install -e . - (可选)安装加速库(如 Flash Attention):
pip install flash-attn==2.7.0.post2 --no-build-isolation
- 进入项目目录:
- 环境验证
- 检查 PyTorch 版本(推荐 2.4.0):
python -c "import torch; print(torch.__version__)"
- 检查 PyTorch 版本(推荐 2.4.0):
如何使用 Ovis
Ovis 支持命令行推理和 Gradio 界面操作,以下是详细指南:
命令行推理
- 准备模型和输入
- 从 Hugging Face 下载模型(如 Ovis2-8B):
git clone https://huggingface.co/AIDC-AI/Ovis2-8B - 准备输入文件,例如图片
example.jpg和提示 “描述这张图片”。
- 从 Hugging Face 下载模型(如 Ovis2-8B):
- 运行推理
- 创建脚本
run_ovis.py:import torch from PIL import Image from transformers import AutoModelForCausalLM # 加载模型 model = AutoModelForCausalLM.from_pretrained( "AIDC-AI/Ovis2-8B", torch_dtype=torch.bfloat16, multimodal_max_length=32768, trust_remote_code=True ).cuda() # 获取 tokenizer text_tokenizer = model.get_text_tokenizer() visual_tokenizer = model.get_visual_tokenizer() # 处理输入 image = Image.open("example.jpg") text = "描述这张图片" query = f"<image>\n{text}" prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image]) attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id) # 生成输出 with torch.inference_mode(): output_ids = model.generate( input_ids.unsqueeze(0).cuda(), pixel_values=[pixel_values.cuda()], attention_mask=attention_mask.unsqueeze(0).cuda(), max_new_tokens=1024 ) output = text_tokenizer.decode(output_ids[0], skip_special_tokens=True) print("输出结果:", output) - 执行脚本:
python run_ovis.py
- 创建脚本
- 查看结果
- 输出示例: “图片中是一只狗站在草地上,背景是蓝天”。
Gradio 界面操作
- 启动服务
- 在 Ovis 目录运行:
python ovis/serve/server.py --model_path AIDC-AI/Ovis2-8B --port 8000 - 等待加载,访问
http://127.0.0.1:8000。
- 在 Ovis 目录运行:
- 界面操作
- 上传图片到界面。
- 输入提示,如 “这张图片里有什么?”。
- 点击提交,查看生成结果。
特色功能操作详解
高分辨率图像处理
- 操作步骤:上传高分辨率图片,模型自动分割处理(最大分区数 9)。
- 场景:适用于艺术品分析、地图解读等任务。
- 硬件建议:16GB 以上显存,确保流畅运行。
视频与多图分析
- 操作步骤:
- 准备视频帧或多张图片,如
[Image.open("frame1.jpg"), Image.open("frame2.jpg")]。 - 修改推理代码中的
pixel_values参数为多图列表。
- 准备视频帧或多张图片,如
- 场景:分析视频片段或连续图像序列。
- 输出示例: “第一帧是街道,第二帧是行人”。
多语言 OCR 支持
- 操作步骤:上传含多语言文字的图片,输入提示 “提取图片中的文字”。
- 场景:扫描文档、翻译图片文字。
- 结果示例:提取中英文混合文字并生成描述。
增强推理能力
- 操作步骤:输入复杂问题,如 “图片中有几个人?请逐步说明”。
- 场景:教育、数据分析任务。
- 输出示例: “图片中有两个人,第一步观察左侧有一个人,第二步观察右侧有第二个人”。
注意事项
- 硬件要求:Ovis2-1B 需 4GB 显存,Ovis2-34B 建议多 GPU(48GB+)。
- 模型兼容性:支持主流 LLM(如 Qwen2.5)和 ViT(如 aimv2)。
- 社区反馈:问题可提交至 GitHub Issues。
Ovis2 图片反推提示词一键安装包
基于Ovis2-4B和Ovis2-2B 这2个大模型制作。
夸克:https://pan.quark.cn/s/23095bb34e7c
百度:https://pan.baidu.com/s/12fWAbshwKY8OYcCcv_5Pkg?pwd=2727
解压密码自行在jian27查找。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...