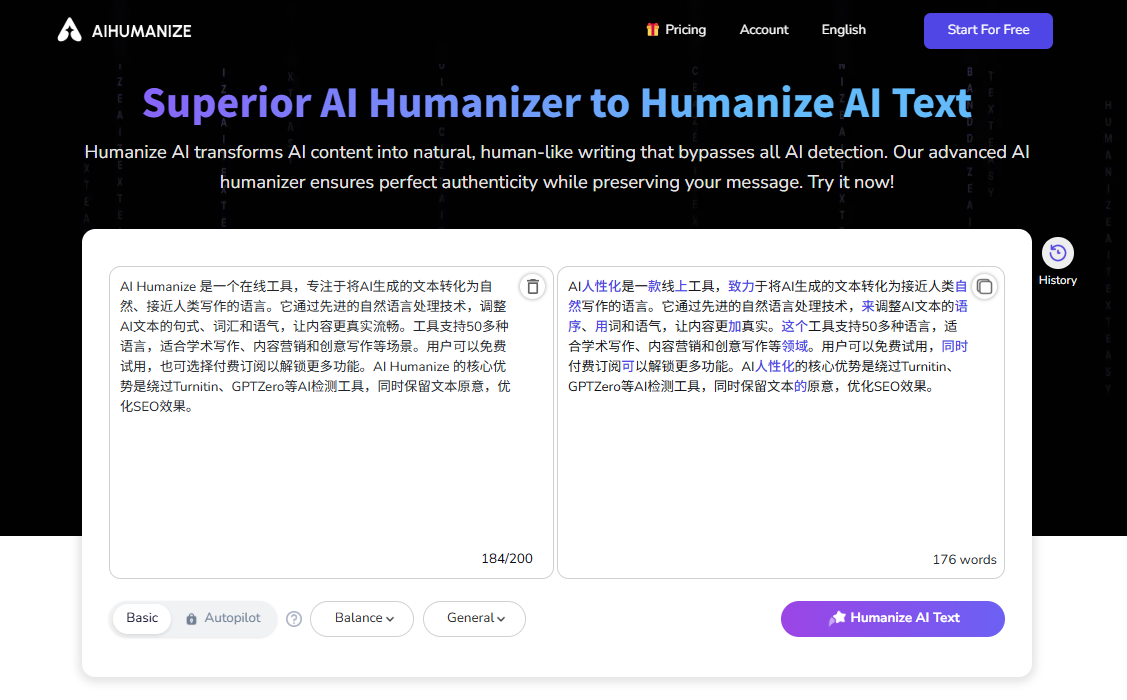

在人类文明的历史长河中,每一次信息获取和解析方式的飞跃,都深刻地推动着社会进步。从远古的象形文字,到便携的纸莎草,再到后来出现的印刷术以及当今的数字化浪潮,每一次技术革新都极大地拓展了人类知识的传播范围和应用深度,进而成为了孕育新一轮创新的沃土。
今天,我们正处在一个激动人心的时代转折点,拥有着前所未有的机遇去解锁蕴藏在海量数字化信息中的巨大潜力。 行业数据显示,现今全球约 90% 的机构数据仍然以文档形式存储,这其中蕴含着巨大的信息价值尚待挖掘。为了释放这些沉睡的数据资产,Mistral AI 重磅推出了 Mistral OCR, 这是一款 Optical Character Recognition (光学字符识别) API,它的出现,标志着文档理解技术迈上了一个新的台阶。
Mistral OCR 的核心优势
Mistral OCR 不仅仅是一个简单的 OCR 工具,它代表着对文档理解方式的彻底革新。相较于市场上的其他 OCR 模型,Mistral OCR 具备更强大的文档认知能力和更高的精度,能够深入理解文档的每一个组成部分——无论是图片、文字,还是表格、数学公式,Mistral OCR 都能轻松驾驭。用户只需上传图像或 PDF 文档,即可快速提取出结构化的内容,并以图文并茂的形式有序呈现。
概括来说,Mistral OCR 拥有以下几个关键优势:
- 顶尖的复杂文档理解力: 能够精准解析图文混合、包含复杂数学公式、表格以及 LaTeX 等高级格式的文档。
- 原生多语言和多模态支持: 生来具备处理多语言和多模态文档的能力,无需额外配置。
- 卓越的性能指标: 在多项权威基准测试中,Mistral OCR 的性能均名列前茅。
- 闪电般的处理速度: 在同类 OCR 产品中,Mistral OCR 的处理速度堪称一流。
- 创新的 "文档即 Prompt" 模式与结构化输出: 支持将整个文档作为 Prompt 指令,并能输出高度结构化的数据结果。
- 灵活可选的自托管方案: 针对对数据安全性有极致要求的企业,Mistral OCR 提供可选择的自托管部署方案。
凭借这些显著优势,Mistral OCR 成为了构建 RAG (Retrieval-Augmented Generation,检索增强生成) 系统的理想选择,尤其是在处理富含信息的多模态文档(如幻灯片、复杂的 PDF 文件等)时,其优势更加突出。目前,Mistral OCR 已经被 Mistral AI 旗下的明星产品 Le Chat 对话式 AI 平台采用,为数百万用户提供强大的文档理解能力。API 版本 mistral-ocr-latest 现已正式发布,定价极具竞争力,仅为每 1000 页 1 美元,若采用批量推理模式,成本效益将更加显著。开发者可以立即通过 Mistral AI 开发者平台 La Plateforme 体验 Mistral OCR 的强大功能。未来,Mistral OCR 还将通过 Mistral AI 的云服务和合作伙伴网络进行更广泛的部署,并支持企业本地化部署。
接下来,我们将深入剖析 Mistral OCR 的各项核心技术优势,并介绍如何通过 API 快速上手使用 Mistral OCR。
Mistral OCR 核心优势详解
复杂文档的深度理解
Mistral OCR 之所以能在复杂文档理解方面表现出类拔萃,得益于其背后先进的模型架构和训练策略。无论是面对图文交错排版的文档、包含大量专业数学公式的学术论文、结构精密的表格,还是采用 LaTeX 等复杂排版系统生成的文档,Mistral OCR 都能实现精准解析。即使是那些信息密度极高的科研论文,其中穿插着图表、图形、公式和图像等多种元素,Mistral OCR 依然能够深入理解文档的内在逻辑和信息。
为了让用户更直观地体验 Mistral OCR 的强大能力,Mistral AI 团队特别准备了一个演示案例。他们将一份典型的 PDF 文档输入 Mistral OCR,模型成功地从中抽取出所有的文本和图像信息,并将其高效地转换为 Markdown 格式的文件,完美保留了原文的结构和内容。感兴趣的开发者可以访问 Colab notebook 亲自体验这一过程。
为了更清晰地展示 Mistral OCR 在实际应用中的文档解析效果,Mistral AI 团队还精心准备了多组 PDF 文档及其对应的 OCR 结果对比。用户可以通过简单的滑动操作,在原始文档和 OCR 识别结果之间自由切换,直观地感受到 Mistral OCR 在处理各种复杂文档时所展现出的卓越性能。
表格 + 图形

OCR 结果

数学公式

OCR 结果

印地语

OCR 结果

普通文档

OCR 结果

阿拉伯语

OCR 结果

性能基准测试的卓越表现
为了全面评估 Mistral OCR 的性能水平,Mistral AI 团队进行了一系列严苛的基准测试。测试结果清晰地表明,Mistral OCR 在多项关键指标上均显著超越了市场上其他领先的 OCR 模型。尤其值得关注的是,Mistral OCR 在从文档中准确提取嵌入图像的能力方面表现突出,而参与对比的其他大型语言模型 (LLM) 目前尚不具备这一功能。为了确保评估的公平性,Mistral AI 团队还特别构建了一个内部 “纯文本” 测试集,用于对各模型进行同台竞技。该测试集涵盖了各种类型的出版物论文以及来源于互联网的 PDF 文档,力求全面、客观地反映各模型的真实性能。
以下是详细的基准测试结果数据:
| 模型 | 总体性能 | 数学公式识别 | 多语种支持 | 扫描文档识别 | 表格识别 |
|---|---|---|---|---|---|
| Google Document AI | 83.42 | 80.29 | 86.42 | 92.77 | 78.16 |
| Azure OCR | 89.52 | 85.72 | 87.52 | 94.65 | 89.52 |
| Gemini-1.5-Flash-002 | 90.23 | 89.11 | 86.76 | 94.87 | 90.48 |
| Gemini-1.5-Pro-002 | 89.92 | 88.48 | 86.33 | 96.15 | 89.71 |
| Gemini-2.0-Flash-001 | 88.69 | 84.18 | 85.80 | 95.11 | 91.46 |
| GPT-4o-2024-11-20 | 89.77 | 87.55 | 86.00 | 94.58 | 91.70 |
| Mistral OCR 2503 | 94.89 | 94.29 | 89.55 | 98.96 | 96.12 |
从上述数据可以清晰地看出,Mistral OCR 在各项关键性能指标上均取得了显著的领先优势,尤其是在总体性能和表格识别能力方面,其优势地位尤为突出。
原生多语种处理能力
自 Mistral AI 创立之初,就将服务全球用户作为重要的发展目标。因此,构建强大的多语言处理能力一直是 Mistral AI 产品研发的核心战略之一。Mistral OCR 在这方面实现了新的突破,它能够无缝解析、精准理解和高效转录数千种不同的文字、字体和语言,全面覆盖全球各大洲的语言文化。这种卓越的多语言适应性,对于那些业务遍布全球、需要处理来自不同语言区域文档的跨国企业,以及专注于特定语言市场、服务 местный 用户的本地化企业而言,都具有至关重要的战略意义。
下表展示了 Mistral OCR 在多语言模糊匹配生成任务中的基准测试结果:
| 模型 | 模糊匹配生成准确率 |
|---|---|
| Google-Document-AI | 95.88% |
| Gemini-2.0-Flash-001 | 96.53% |
| Azure OCR | 97.31% |
| Mistral OCR 2503 | 99.02% |
测试数据表明,Mistral OCR 在多语言模糊匹配生成方面同样表现出色,其性能指标超越了其他主流 OCR 产品,再次印证了其强大的多语言处理能力。
为了更精细地评估 Mistral OCR 在不同语种下的性能表现,Mistral AI 团队还进行了更细致的分语种基准测试,测试结果如下:
| 语言 | Azure OCR | Google Doc AI | Gemini-2.0-Flash-001 | Mistral OCR 2503 |
|---|---|---|---|---|
| 俄语 (ru) | 97.35% | 95.56% | 96.58% | 99.09% |
| 法语 (fr) | 97.50% | 96.36 | 97.06% | 99.20% |
| 印地语 (hi) | 96.45% | 95.65 | 94.99% | 97.55% |
| 中文 (zh) | 91.40% | 90.89% | 91.85% | 97.11% |
| 葡萄牙语 (pt) | 97.96% | 96.24 | 97.25% | 99.42% |
| 德语 (de) | 98.39% | 97.09% | 97.19 | 99.51% |
| 西班牙语 (es) | 98.54% | 97.52 | 97.75 | 99.54% |
| 土耳其语 (tr) | 95.91% | 93.85 | 94.66% | 97.00% |
| 乌克兰语 (uk) | 97.81% | 96.24 | 96.70% | 99.29% |
| 意大利语 (it) | 98.31% | 97.69 | 97.68 | 99.42% |
| 罗马尼亚语 (ro) | 96.45% | 95.14 | 95.88% | 98.79% |
从分语种测试结果来看,Mistral OCR 在各种语言的识别准确率上均表现出色,尤其在中文识别方面,Mistral OCR 的优势尤为明显。
极速文档处理能力
Mistral OCR 在追求卓越性能的同时,还兼顾了轻量化设计,这使得它在处理速度上远超同类产品。在标准单节点配置下,Mistral OCR 的处理速度高达每分钟 2000 页文档。如此惊人的文档处理速度,即使在需要处理海量文档的高负载应用场景中,也能确保系统高效运转,并支持系统持续进行学习和性能优化。
"文档即 Prompt" 与结构化输出
Mistral OCR 的另一项创新功能是 "文档即 Prompt" 模式。 这一功能允许用户直接将整个文档作为指令 (Prompt) 输入模型,从而实现更强大、更精准的信息提取。用户可以指示 Mistral OCR 从文档中提取特定的信息,并按照预定义的格式(如 JSON)输出结构化数据。这种结构化的输出结果,可以方便地与下游应用和工作流进行集成,例如,用户可以将提取出的数据直接用于函数调用或构建智能 Agent。Mistral AI 团队同样提供了一个 notebook 示例 ,帮助用户快速上手体验 "文档即 Prompt" 功能。
灵活的自托管部署选项
考虑到部分企业和组织对数据隐私和安全性有着极其严格的要求,Mistral OCR 特别提供了自托管部署选项。选择自托管部署方案的用户,可以将 Mistral OCR 完全部署在企业自身的基础设施之上,从而确保所有敏感数据和机密信息始终在企业自身安全可控的环境中处理,满足最严苛的监管合规和数据安全标准。对于有自托管部署需求的企业,可以随时 联系 Mistral AI 获取更多信息。
快速上手 Mistral OCR API
Mistral OCR API 的使用非常简便, Mistral AI 提供了 Python 和 Typescript 等多种语言的 SDK 以及 curl 请求示例,方便开发者快速集成。
文档 OCR 处理器
Mistral OCR 的核心功能由 文档 OCR 处理器 驱动,它基于 Mistral AI 最新的 OCR 模型 mistral-ocr-latest 构建,能够从 PDF 文档中精准提取文本和结构化内容。
主要特性:
- 结构化内容提取: 在提取文本内容的同时,完整保留文档的原有结构和层次关系。
- 格式化信息保留: 能够准确识别并保留文档中的各种格式化信息,如标题、段落、列表和表格等。
- Markdown 格式输出: 返回结果以简洁易用的 Markdown 格式呈现,方便用户进行二次解析和渲染。
- 复杂布局处理: 轻松应对各种复杂文档布局,包括多栏文本和混合内容排版。
- 高精度、规模化处理: 在保证高识别精度的前提下,支持大规模文档的批量处理。
- 广泛的文档格式支持: 支持 PDF、图像以及用户上传的文档等多种输入格式。
文档 OCR 处理器不仅返回提取出的文本内容,还包含关于文档结构的元数据,这使得开发者能够更方便地以编程方式处理识别后的文档内容。
PDF 文档 OCR
以下代码示例展示了如何使用 Mistral OCR API 处理 PDF 文档:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"document_url",
"document_url":"https://arxiv.org/pdf/2201.04234"
},
include_image_base64=True
)
上传 PDF 文档进行 OCR
Mistral OCR API 也支持用户上传 PDF 文件进行 OCR 处理。
文件上传
首先,需要将 PDF 文件上传到 Mistral AI 的文件服务:
from mistralai import Mistral
import os
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
uploaded_pdf = client.files.upload(
file={
"file_name":"uploaded_file.pdf",
"content":open("uploaded_file.pdf","rb"),
},
purpose="ocr"
)
文件检索
上传成功后,可以检索已上传的文件信息:
client.files.retrieve(file_id=uploaded_pdf.id)
id='00edaf84-95b0-45db-8f83-f71138491f23' object='file' size_bytes=3749788 created_at=1741023462 filename='uploaded_file.pdf' purpose='ocr' sample_type='ocr_input' source='upload' deleted=False num_lines=None
获取签名 URL
为了安全访问上传的文件,可以获取文件的签名 URL:
signed_url = client.files.get_signed_url(file_id=uploaded_pdf.id)
获取 OCR 结果
最后,使用签名 URL 作为文档地址,即可获取上传 PDF 文件的 OCR 处理结果:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"document_url",
"document_url": signed_url.url,
}
)
图像 OCR
Mistral OCR API 同样支持直接对图像进行 OCR 处理。
URL 图像 OCR
可以通过图像 URL 直接进行 OCR 识别:
import os
from mistralai import Mistral
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"image_url",
"image_url":"https://media-cldnry.s-nbcnews.com/image/upload/t_fit-560w,f_avif,q_auto:eco,dpr_2/rockcms/2023-11/short-quotes-swl-231117-02-33d404.jpg"
}
)
Base64 编码图像 OCR
或者,也可以将图像Base64 编码后传递给 API 进行 OCR 识别:
import base64
import requests
import os
from mistralai import Mistral
defencode_image(image_path):
"""Encode the image to base64."""
try:
withopen(image_path,"rb")as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except FileNotFoundError:
print(f"Error: The file {image_path} was not found.")
returnNone
except Exception as e:# Added general exception handling
print(f"Error: {e}")
returnNone
# Path to your image
image_path ="path_to_your_image.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
ocr_response = client.ocr.process(
model="mistral-ocr-latest",
document={
"type":"image_url",
"image_url":f"data:image/jpeg;base64,{base64_image}"
}
)
文档理解功能
Mistral OCR 的 文档理解 功能,是将强大的 OCR 技术与大型语言模型 (LLM) 深度融合的创新应用。它赋予了用户与文档内容进行自然语言交互的能力,用户可以通过自然语言提问,从文档中高效地提取信息和洞察。
文档理解的工作流程主要包含两个步骤:
- 文档处理: 首先,通过 OCR 技术提取文档中的文本、结构和格式信息,将非结构化的文档转换为机器可读的格式。
- 语言模型理解: 随后,大型语言模型对提取出的文档内容进行深度分析和理解。用户可以使用自然语言提出问题或信息需求,模型能够理解文档的上下文和内在关联,并基于文档内容给出精准的答案。
文档理解的关键能力:
- 基于文档内容的问答: 能够回答关于文档特定内容的自然语言问题。
- 信息抽取与摘要: 从文档中提取关键信息并生成简洁的摘要。
- 文档分析与洞察: 对文档内容进行深入分析,挖掘潜在的洞察和知识。
- 多文档查询与比较: 支持跨多篇文档进行信息查询和内容比较。
- 上下文感知回复: 能够结合文档的完整上下文信息,给出更准确、更相关的回复。
文档理解的典型应用场景:
- 科研论文和技术文档分析: 快速分析和理解大量的科研论文和技术文档。
- 商业文档信息提取: 高效提取商业合同、报告等文档中的关键信息。
- 法律文档和合同处理: 辅助处理和分析复杂的法律文档和合同条款。
- 构建文档问答应用: 开发智能文档问答系统,提升信息检索效率。
- 自动化文档工作流: 自动化处理各种基于文档的工作流程,如文档审核、信息录入等。
以下代码示例展示了如何使用自然语言与 PDF 文档进行交互,并提问文档的最后一句是什么:
import os
from mistralai import Mistral
# Retrieve the API key from environment variables
api_key = os.environ["MISTRAL_API_KEY"]
# Specify model
model ="mistral-small-latest"
# Initialize the Mistral client
client = Mistral(api_key=api_key)
# Define the messages for the chat
messages =[
{
"role":"user",
"content":[
{
"type":"text",
"text":"what is the last sentence in the document"
},
{
"type":"document_url",
"document_url":"https://arxiv.org/pdf/1805.04770"
}
]
}
]
# Get the chat response
chat_response = client.chat.complete(
model=model,
messages=messages
)
# Print the content of the response
print(chat_response.choices[0].message.content)
# Output:
# The last sentence in the document is:\n\n\"Zaremba, W., Sutskever, I., and Vinyals, O. Recurrent neural network regularization. arXiv:1409.2329, 2014.
应用案例
Mistral OCR 强大的文档理解能力,正在各行各业的实际应用中释放出巨大的价值,帮助企业和组织将海量文档数据转化为可执行的知识和解决方案。目前,Mistral OCR 已经在以下几个关键领域取得了显著的应用成果:
科研数字化转型: 众多顶尖科研机构已经开始尝试利用 Mistral OCR 将大量的科学论文和学术期刊转换为 AI 友好的数据格式,使其能够无缝接入各种下游智能分析引擎。这极大地促进了科研协作效率的提升,并显著加速了科研工作流程。
文化遗产的数字化保护与传承: 许多文化遗产保护组织和非营利机构正在积极采用 Mistral OCR 技术,对珍贵的历史文献和文物资料进行数字化处理,实现文化遗产的永久保存和更广泛的传播与共享。
客户服务的智能化升级: 客户服务部门也在积极探索 Mistral OCR 的应用,尝试将繁杂的产品文档和用户手册转化为结构化的、可索引的知识库,从而大幅缩短客户响应时间,显著提升客户服务质量和用户满意度。
各行业文献的 AI 赋能: Mistral OCR 正在帮助各行各业的企业,将大量的技术文档、工程图纸、 강의笔记、演示文稿、监管备案文件等转化为可索引、可检索的 AI 友好格式,深度挖掘文档中蕴藏的知识和情报,全面提升组织生产力。
立即体验 Mistral OCR 的强大功能
现在就可以立即体验 Mistral OCR 的强大功能!用户可以通过访问 Le Chat 平台,免费体验 Mistral OCR 的文档理解能力。如需体验 API 版本,请访问 La Plateforme。 Mistral AI 团队非常期待收到用户的宝贵反馈,并将持续对 Mistral OCR 模型进行优化和迭代,不断提升其性能。作为战略合作计划的一部分,Mistral AI 还为部分用户提供 本地部署 方案。
更多资源
如需了解更多关于 Mistral OCR 的使用方法和高级技巧,请参考以下资源:
- Tool Use and Document Understanding Cookbook: https://colab.research.google.com/github/mistralai/cookbook/blob/main/mistral/ocr/document_understanding.ipynb
- Batch OCR Cookbook: https://colab.research.google.com/github/mistralai/cookbook/blob/main/mistral/ocr/batch_ocr.ipynb
- Structured OCR Cookbook: https://colab.research.google.com/github/mistralai/cookbook/blob/main/mistral/ocr/structured_ocr.ipynb
这些 Cookbooks 提供了详细的代码示例和实践指南,可以帮助开发者更深入地理解和应用 Mistral OCR 的各项功能。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...