
综合介绍
MediaCrawler是一个专为开发者设计的社交媒体内容爬虫工具。通过提供一个强大的爬虫功能,它能够快速地从小红书、抖音、快手、B站、微博等社交平台抓取视频、图片、评论、点赞、转发等数据。这个工具使用了Playwright作桥梁,保留登录后的浏览器环境,通过执行JS表达式获取加密参数,从而简化了复杂的逆向工程难度。
仅限专业人员使用,请注意采集数据需要在授权范围内进行。
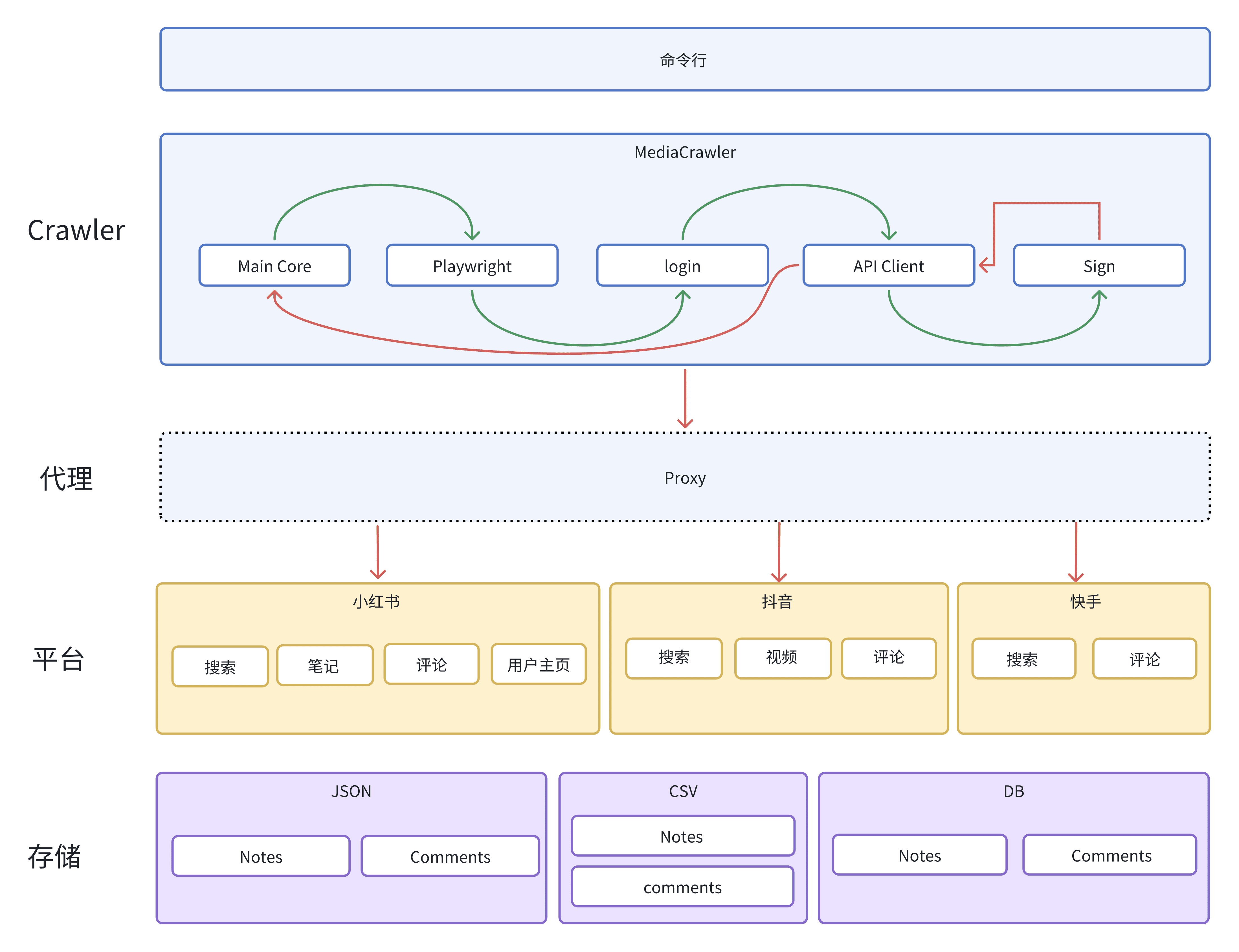
功能列表
支持小红书、抖音、快手、B站、微博等平台
提供Cookie登录、二维码登录、手机号登录等多种方式
支持关键词搜索和指定视频/帖子ID爬取功能
登录状态缓存和IP代理池支持
提供滑块验证码解决方案(部分平台)
| 平台 | 关键词搜索 | 指定帖子ID爬取 | 二级评论 | 指定创作者主页 | 登录态缓存 | IP代理池 | 生成评论词云图 |
|---|---|---|---|---|---|---|---|
| 小红书 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 抖音 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 快手 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| B 站 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 微博 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 贴吧 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
使用帮助
创建并激活Python虚拟环境
安装依赖库:使用 `pip install -r requirements.txt` 命令
安装Playwright浏览器驱动:使用 `playwright install` 命令
运行爬虫程序:使用如 `python main.py --platform xhs --lt qrcode --type search` 的命令行参数
使用 `python main.py --help` 查看其他平台的爬虫使用示例
查询项目代码结构和更多问题解答于GitHub仓库资料
学习资料
https://relakkes.feishu.cn/wiki/JUgBwdhIeiSbAwkFCLkciHdAnhh
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...