

综合介绍
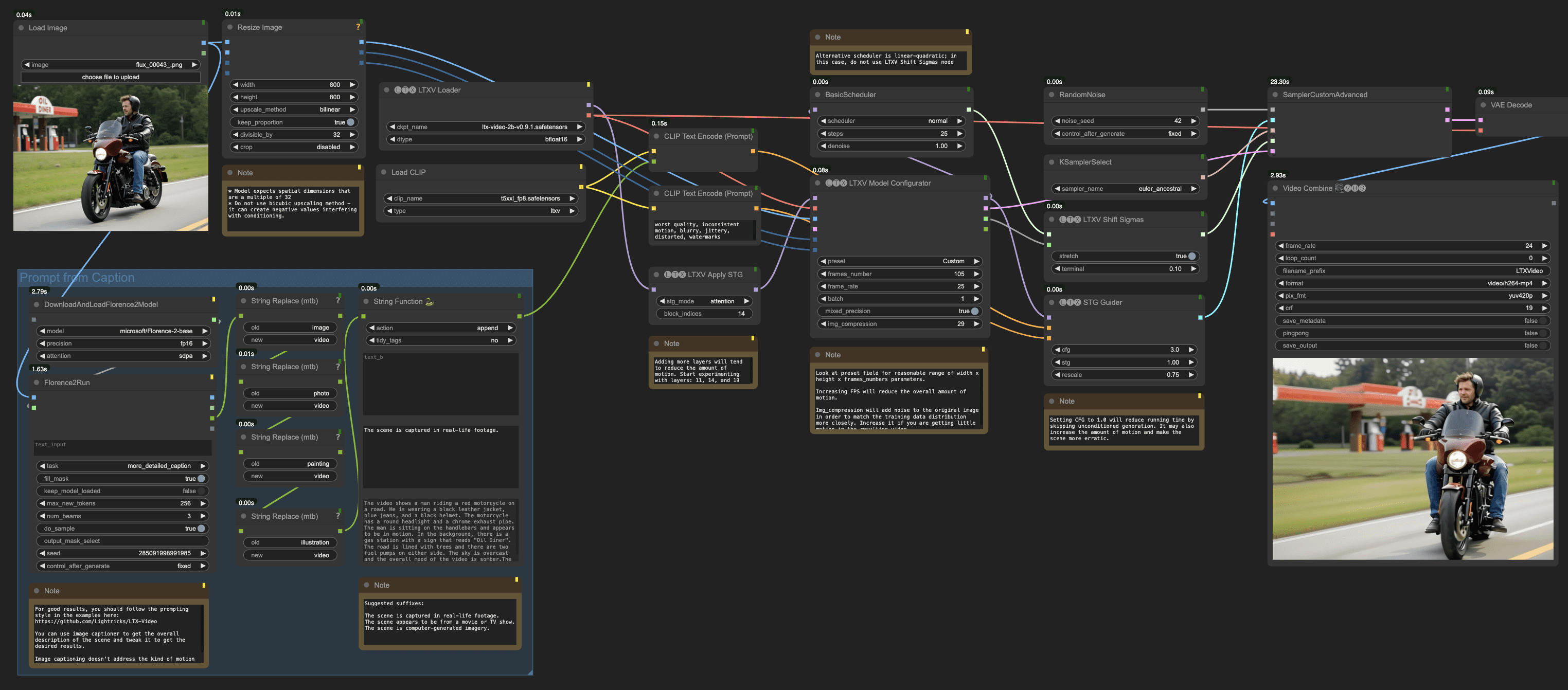
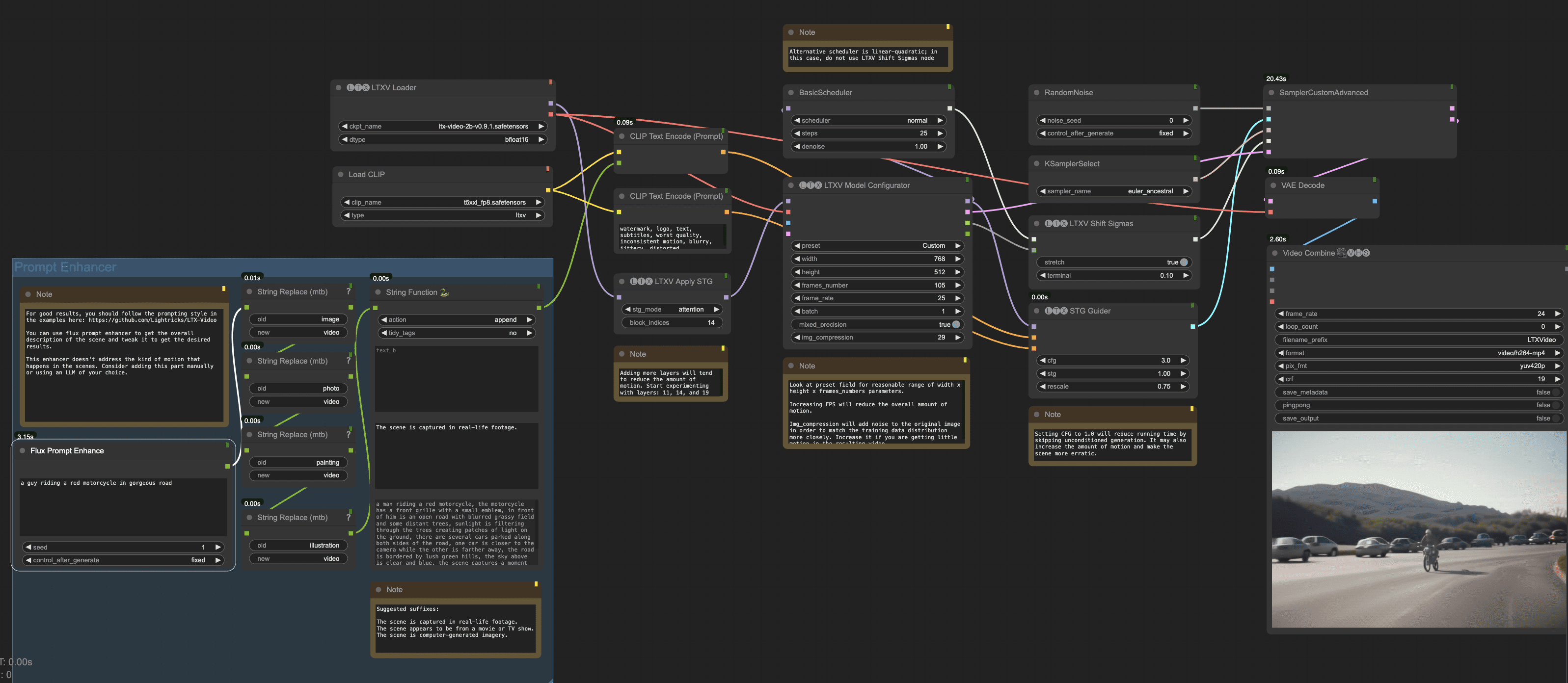
LTX-Video是由Lightricks开发的首个基于DiT(Diffusion Transformer)的实时视频生成模型。该模型能够在768x512分辨率下以24帧每秒的速度生成高质量视频,速度快于观看视频的时间。LTX-Video经过大规模多样化视频数据集的训练,能够生成具有真实感和多样化内容的高分辨率视频。该模型的设计旨在提供快速且高效的视频生成解决方案,适用于各种创意和专业应用场景。
LTXV有明显的缺点,不要输入简单的提示词,要对视频画面进行详细的描述,或对提示词扩展。

体验地址:https://huggingface.co/spaces/Lightricks/LTX-Video-Playground
功能列表
- 实时视频生成:在768x512分辨率下以24帧每秒的速度生成视频。
- 高质量输出:生成高分辨率、真实感强且内容多样的视频。
- 多种生成模式:支持文本到视频、图像到视频和视频到视频的生成模式。
- 优化性能:LTX-VideoQ8版本在NVIDIA ADA GPU上优化,性能提升高达3倍。
- 集成支持:支持与 ComfyUI 和Diffusers的集成,提供灵活的工作流程。
使用帮助
安装流程
- 安装ComfyUI:
- 下载并安装ComfyUI。
- 克隆LTX-Video仓库:
- 在ComfyUI安装目录的custom-nodes文件夹中克隆LTX-Video仓库。
- 运行以下命令安装所需的Python包:
bash
cd custom_nodes/ComfyUI-LTXVideo
pip install -r requirements.txt - 对于便携式ComfyUI安装,运行以下命令:
bash
.\python_embeded\python.exe -m pip install -r .\ComfyUI\custom_nodes\ComfyUI-LTXVideo\requirements.txt
- 下载模型:
- 从Hugging Face下载ltx-video-2b-v0.9.1.safetensors并放置在models/checkpoints文件夹中。
- 安装T5文本编码器,例如googlet5-v11-xxl_encoderonly,可以使用ComfyUI Model Manager进行安装。
使用指南
- 文本到视频生成:
- 在ComfyUI中选择LTX-Video节点。
- 输入文本描述,选择生成参数,点击生成按钮。
- 图像到视频生成:
- 在ComfyUI中选择LTX-Video节点。
- 上传图像文件,选择生成参数,点击生成按钮。
- 视频到视频生成:
- 在ComfyUI中选择LTX-Video节点。
- 上传视频文件,选择生成参数,点击生成按钮。
特色功能操作流程
- 高分辨率生成:
- 在生成参数中选择高分辨率选项,确保生成的视频质量达到预期。
- 多样化内容生成:
- 使用多样化的文本描述或图像输入,探索模型生成的多样化视频内容。
- 性能优化:
- 使用LTX-VideoQ8版本,在NVIDIA ADA GPU上体验更快的生成速度和更高的性能。
通过以上步骤,用户可以轻松上手使用LTX-Video进行高质量视频生成,满足各种创意和专业需求。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
Related posts



暂无评论...