


공식 도출, 논리 체인 구성, 추상적 사고 등을 포함하는 수학적 능력은 오랫동안 인공지능(AI), 특히 대규모 언어 모델(LLM)의 능력을 테스트하는 핵심 영역으로 여겨져 왔습니다. 계산 능력을 테스트할 뿐만 아니라 복잡한 문제를 추론하고, 이해하고, 해결하는 모델의 능력을 심층적으로 탐구할 수 있기 때문입니다.
그러나 최근 취리히 연방공대(ETH Zurich) 연구팀의 연구 결과에 따르면, 미국 수학 올림피아드 수준의 문제와 같은 어려운 수학 경시대회 문제에 직면했을 때 상위권 대규모 언어 모델(LLM)도 일반적으로 낮은 점수를 받는 것으로 나타나 엄격한 수학적 추론 측면에서 현재 LLM의 진정한 능력에 대한 논의가 시작되고 있습니다.
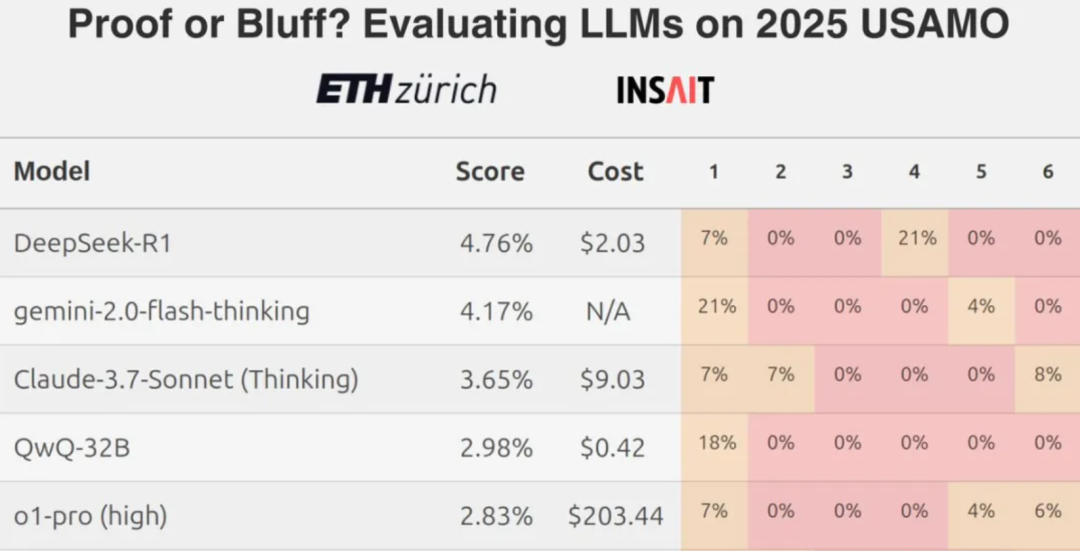
이러한 맥락에서 자연스러운 질문은 중국어로 공식화된 수학 문제를 다룰 때 이러한 모델이 얼마나 잘 수행하느냐는 것입니다. 이 리뷰에서는 알리바바 글로벌 수학 경시대회와 중국 수학 올림피아드 문제를 사용하여 국내외에서 주류 또는 떠오르는 대규모 언어 모델 총 7개를 선정하여 수학적 능력을 나란히 비교했습니다.
테스트에 참여한 모델은 다음과 같습니다:
- 국내 모델:
DeepSeek R1및Hunyuan T1및Tongyi Qwen-32B(원문)通义QwQ-32B),YiXin-Distill-Qwen-72B - 국제 모델링:
Grok 3 beta및Gemini 2.0 Flash Thinking및o3-mini
전반적인 성능 평가
평가는 난이도가 높은 10개의 문항으로 구성되며, 총 13문항이 채점됩니다. 채점 기준은 완전 정답은 1점, 부분 정답은 0.5점, 오류는 무점수입니다.
이 테스트에서 각 모델의 전반적인 정확도는 다음과 같습니다:

자세한 점수 분포는 모델 간의 성능 차이를 보여줍니다:
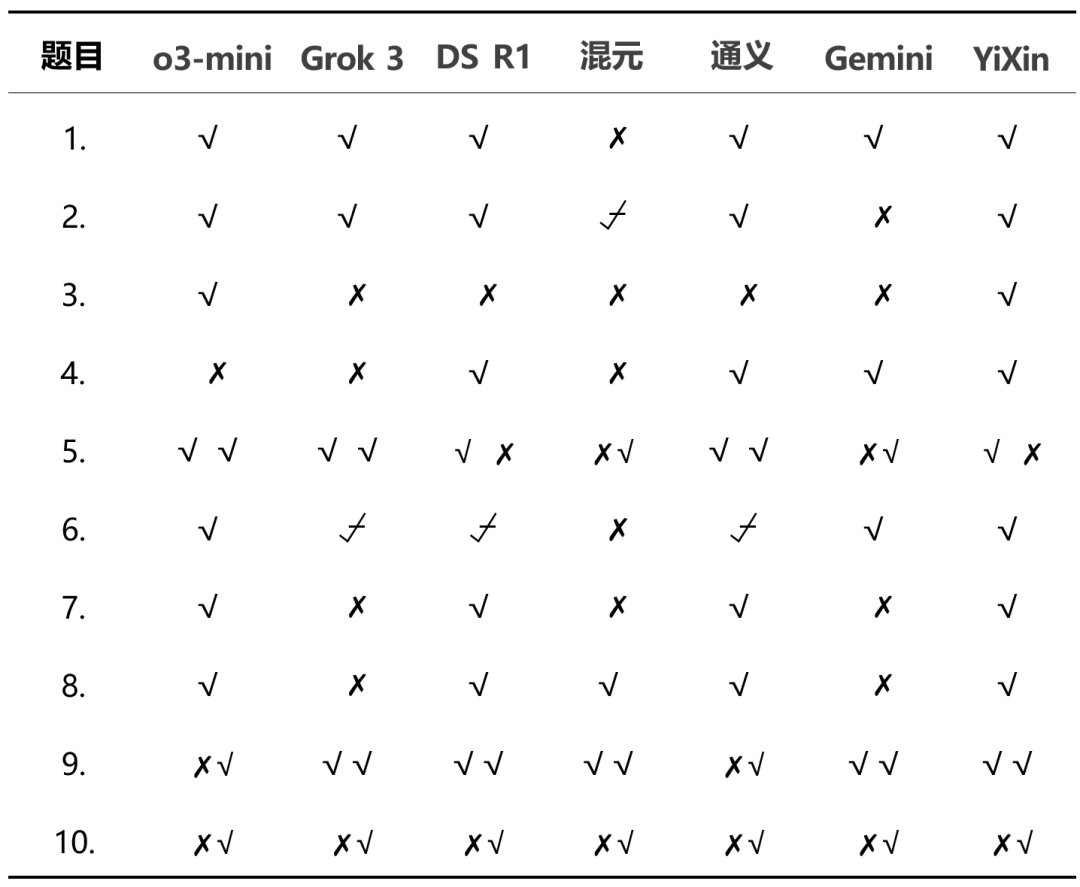
전체 결과에서.o3-mini 노래로 응답 YiXin-Distill-Qwen-72B 이 테스트에서 우수한 성적을 거두며 강력한 수학적 문제 해결 능력을 보여주었습니다. 다른 모델들의 성능은 다양했습니다.
일부 시험 문제에 대한 구체적인 정답은 다음에 나와 있습니다.
측정 세부 정보
1라운드: 변화의 문제
질문: 할아버지가 60달러를 가지고 20달러 상당의 야채를 사러 슈퍼마켓에 간다면 계산원이 할아버지에게 거스름돈을 어떻게 줄 수 있을까요?
분석: 생활 시나리오에 대한 모델의 이해와 기본적인 돈 계산 능력을 평가하는 기본적인 산술 응용 문제입니다.
결과:o3-mini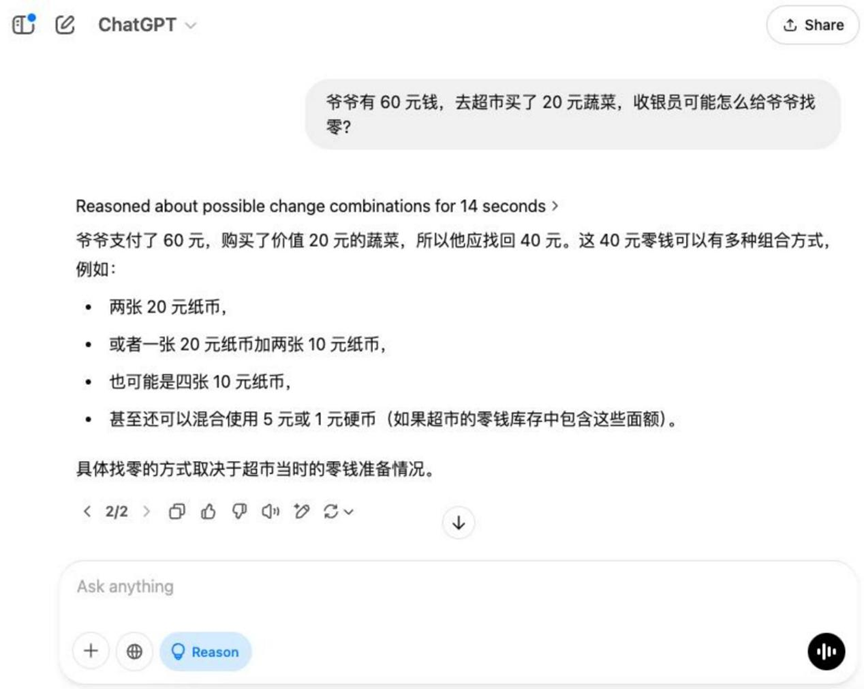
Grok 3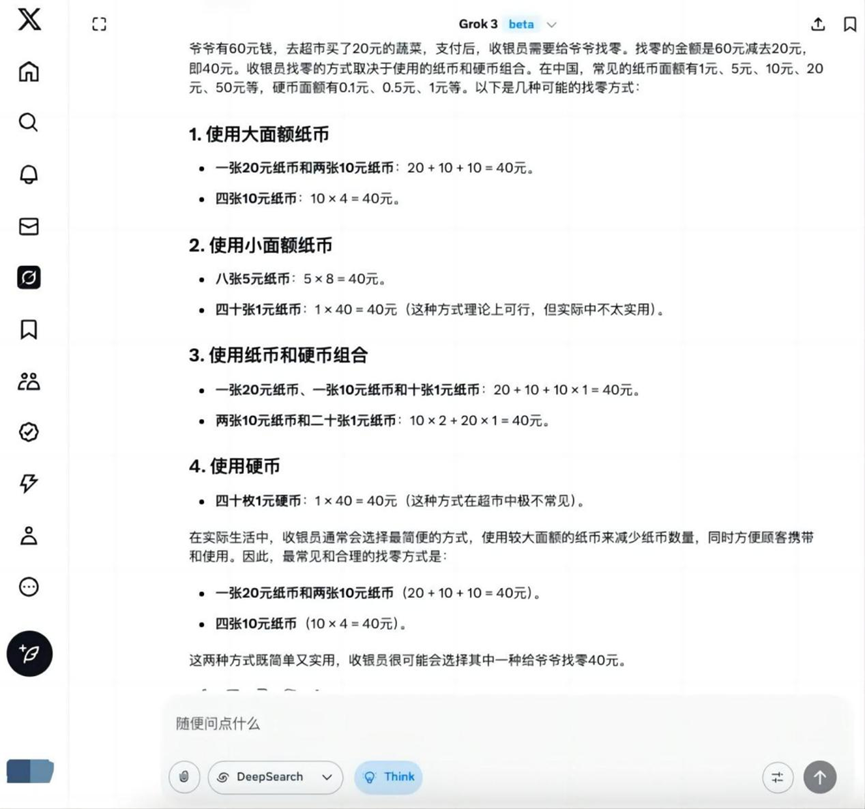
Hunyuan T1
Gemini 2.0 Flash Thinking
YiXin-Distill-Qwen-72B
이 기본 주제에서는 다음과 더불어 Hunyuan T1 그 외의 나머지 모델은 0을 구하는 데 올바른 해를 제공합니다.
2라운드: 도보 거리 계산 및 방법론적 판단
질문: 샤오밍과 샤오화는 매일 걸어서 학교에 다닙니다. 밍은 분당 48미터, 화는 분당 55미터를 걷습니다. 샤오밍의 집은 학교에서 384미터 떨어져 있습니다. 샤오화는 집에서 학교까지 가는 데 밍보다 4분 더 걸립니다. 샤오화의 집과 학교의 거리는 얼마나 되나요? 다음 중 올바르지 않은 방법은 무엇이며 그 이유는 무엇인가요?
방법 1: 55 × 4 = 220(미터), 384 + 220 = 604(미터)
방법 2: 384 / 48 = 8(분), 55 × (8 + 4) = 660(미터)
분석: 이 문제는 여행 문제 계산과 논리적 판단을 결합하여 정답을 계산할 수 있을 뿐만 아니라 주어진 해결책의 옳고 그름을 분석할 수 있어야 하며, 다단계 추론과 논리적 분별력을 테스트합니다.
결과:DeepSeek R1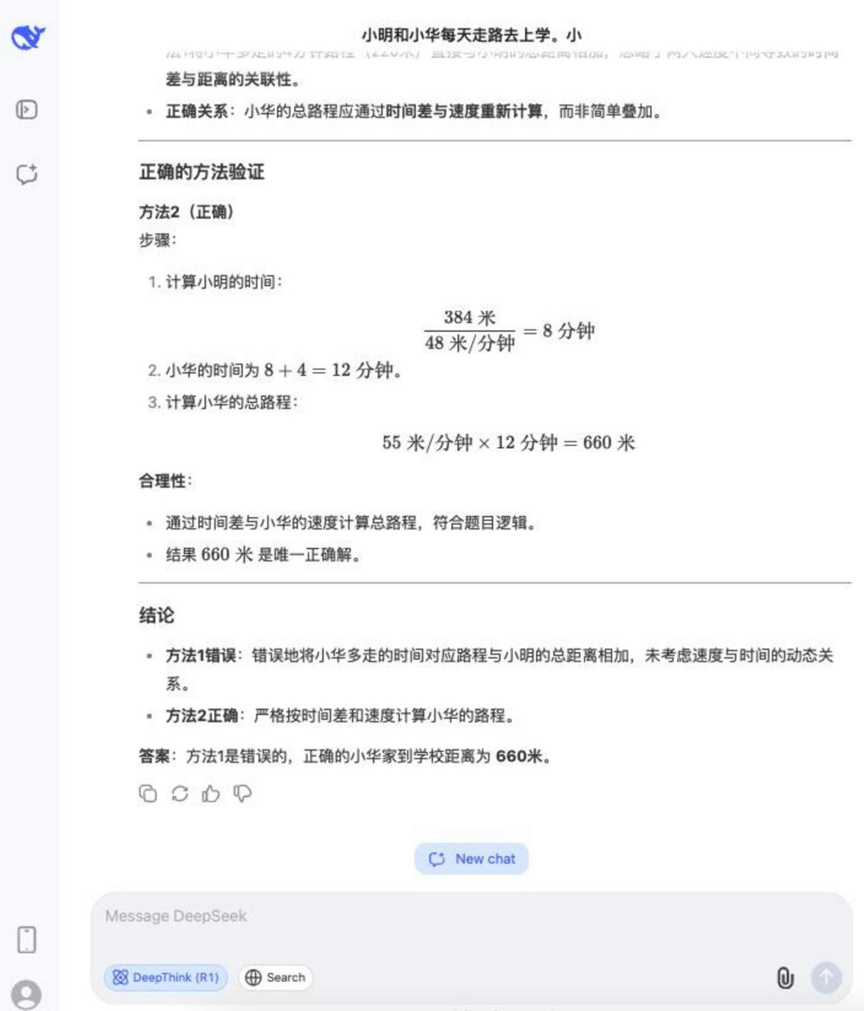
Tongyi Qwen-32B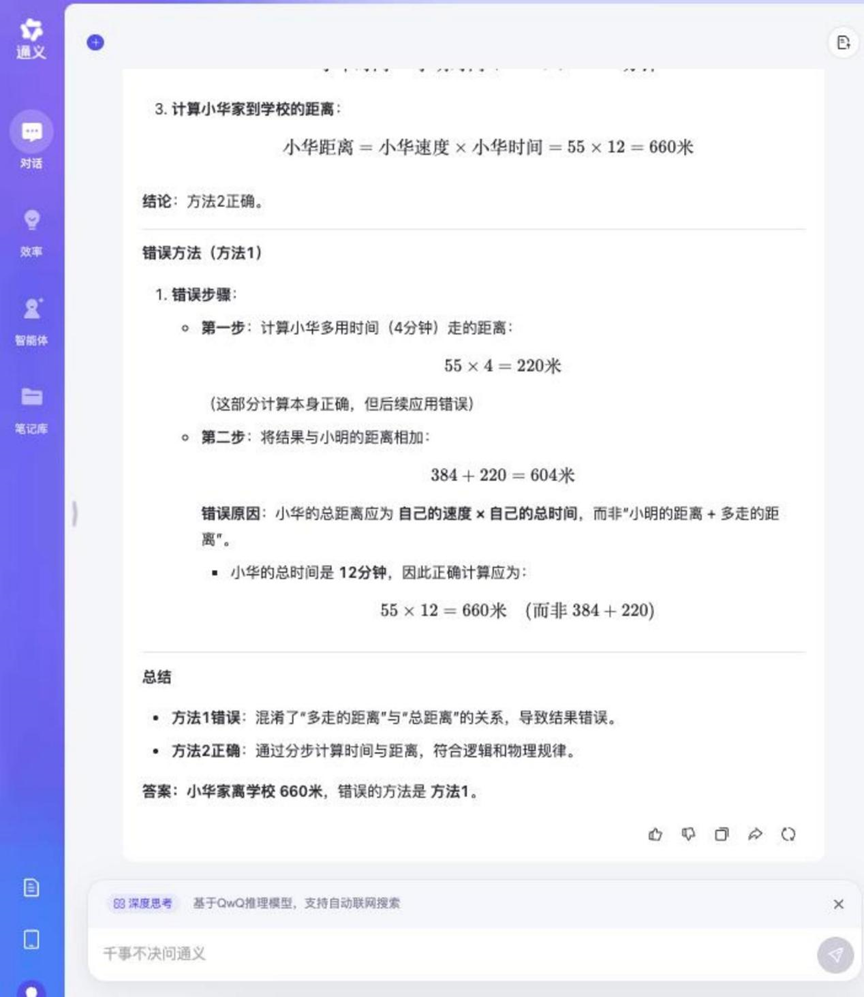
YiXin-Distill-Qwen-72B
이 문제에 대한 추론 과정은 비교적 길었지만, 테스트에 참여한 대부분의 모델이 정답을 맞추고 잘못된 방법을 알아낼 수 있었습니다.
3라운드: 기하학적 오클루전 문제(보이지 않는 타워)
질문: 한 도시에는 A, B, C, D, E, F 지점에 6개의 탑이 있습니다. 여러 학생이 여행 그룹을 구성하여 도시로 자유 여행을 떠납니다. 얼마 후, 각 학생들은 A, B, C, D 지점에 위치한 4개의 탑만 볼 수 있고 E와 F 지점에 위치한 탑은 볼 수 없다는 것을 알게 됩니다. 학생과 탑의 위치는 같은 평면상의 점으로 간주되며 이 점들은 서로 일치하지 않으며 점 A, B, C, D, E, F 중 3개가 공통선을 공유하지 않는다는 것을 알고 있습니다. 탑을 볼 수 없는 유일한 가능성은 다른 탑에 의해 시야가 가려진 경우입니다. 예를 들어, 한 학생이 A와 B가 함께 있는 점 P에 있고 A가 선분 PB에 있는 경우, 이 학생은 B에 있는 탑을 볼 수 없습니다. 이 여행 그룹에 포함될 수 있는 최대 학생 수는 몇 명입니까? 가. 3명 나. 4명 다. 6명 라. 12명
분석: 이는 가시성, 오클루전 및 포인트 세트 구성 문제와 관련된 복잡한 기하학적 및 논리적 추론 문제로, 모델에서 높은 수준의 공간적 상상력과 논리적 추론이 필요합니다.
결과:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B
문제의 난이도가 크게 높아졌습니다. 이번 테스트에서는 다음과 같은 문제만 출제됩니다. o3-mini 노래로 응답 YiXin-Distill-Qwen-72B 를 성공적으로 풀었지만 다른 모델들은 정답을 제시하지 못했습니다.
4라운드: 확률 문제(호랑이와 호랑이)
질문: 춘절 기간 동안 한 우유 회사에서 춘절 블라인드 박스 활동을 시작했습니다. 각 우유 상자에는 "호랑이" "성" "성"" 웨이" 세 가지 패턴 중 하나가 들어 있습니다. "타이거", "셩", "웨이" 두 개를 모으면 "타이거 타이거 셩 웨이" 가족 초상화를 만들 수 있습니다. 이 활동은 시작되자마자 넷플릭스 히트작이 되어 많은 사람들의 참여를 이끌어냈습니다. 알려진 조건은 다음과 같습니다: 빨간색 패킷의 패턴은 독립적으로 무작위로 분포되어 있으며 서로 구별할 수 없습니다. '타이거', '셩', '웨이'의 세 가지 패턴이 나타날 확률은 1/3입니다. Q: '타이거 타이거 셩 웨이'의 전체 세트를 수집하려면 어떻게 해야 하나요? 질문: "타이거, 타이거, 마이티" 가족 사진 세트를 모두 수집하려면 평균적으로 몇 개의 우유 팩을 구매해야 하나요?
분석: 이 문제는 확률 이론과 기대치 계산을 사용해야 하는 전형적인 수집가 문제(쿠폰 수집가 문제 변형)로, 확률 모델을 다루고 수학적 기대치 계산을 수행하는 능력을 평가합니다.
결과:DeepSeek R1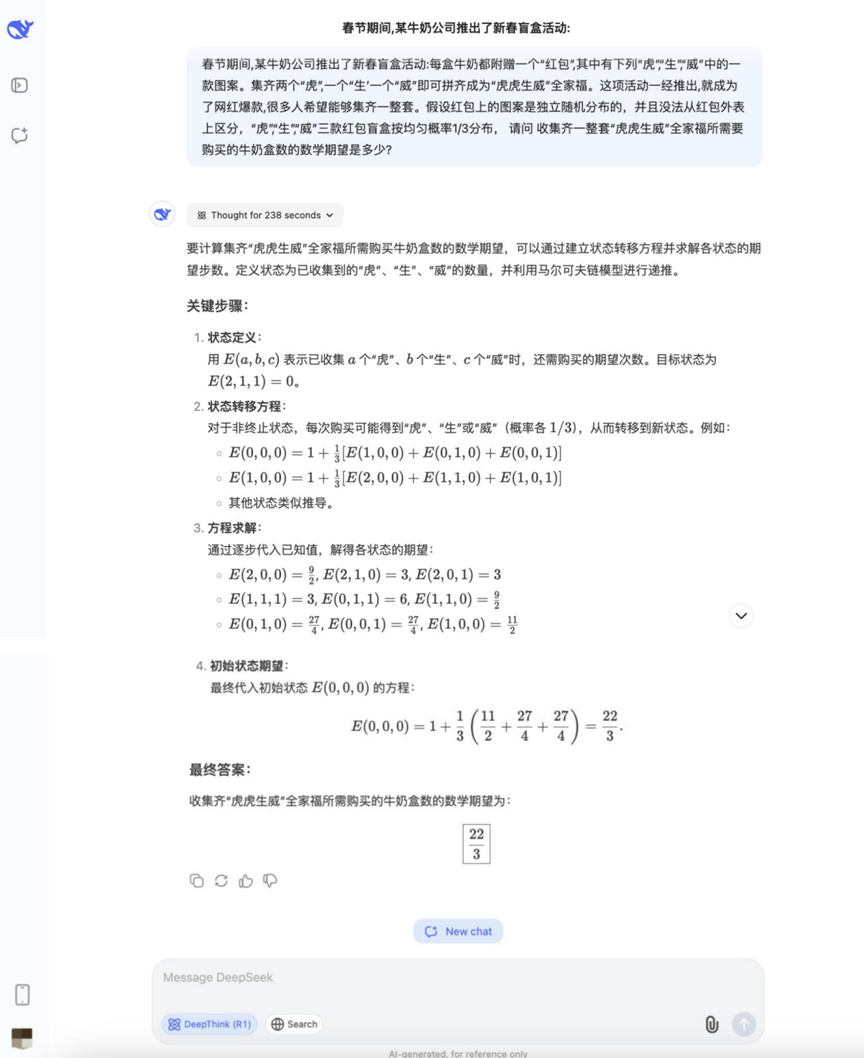
Hunyuan T1
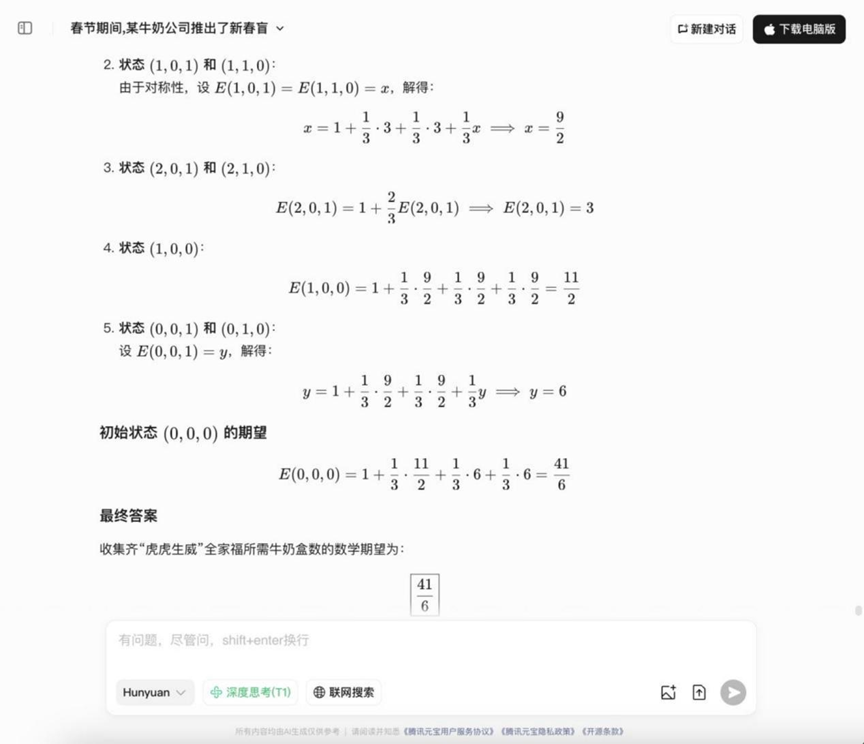
YiXin-Distill-Qwen-72B
이 라운드의 확률 문제에 대한 답은 다양해지기 시작했고, 일부 모델은 아이디어를 정확하게 나열하고 계산할 수 있었습니다.
5라운드: 기하학 및 경로 계획(파이터 게임)
문제 설명 그림:
분석: 기하학, 좌표계 또는 격자계, 최단 경로/최적 전략이 결합된 문제이며, 모델이 그래픽 정보를 이해하고 공간 추론 및 계획을 수행해야 할 수 있습니다.
결과:o3-mini: 해결 성공
YiXin-Distill-Qwen-72B: 부분적으로 맞습니다.

이 테스트에서는 더 높은 수준의 모델 통합이 필요하며, 테스트한 모델의 약 절반이 완전히 올바르게 처리되었습니다.
6라운드: 정수론 증명 문제(최소 비인자 찾기)
문제 설명 그림:
분석: 엄격한 논리적 추론과 수 이론 개념에 대한 깊은 이해가 필요한 증명 문제의 영역으로 넘어가면, 이 문제는 모델의 추상적 추론 능력을 직접적으로 테스트합니다.
결과:o3-mini
YiXin-Distill-Qwen-72B

국내 모델링에서는YiXin-Distill-Qwen-72B 이번 증명 문제 라운드에서 더 나은 성적을 거두었습니다. 증명 문제는 모델에게 훨씬 더 까다로운 문제였습니다.
7라운드: 함수 및 매핑 문제(단위 원에 매핑하기)
문제 설명 그림:
분석: 이 문제는 고등 수학의 함수, 매핑 및 단위 원의 개념을 다루며 추상적인 수학적 정의를 이해하고 적용하는 능력을 평가합니다.
결과:o3-mini
YiXin-Distill-Qwen-72B
약 절반의 모델이 추상적 매핑과 관련된 이 문제를 올바르게 처리할 수 있었습니다.
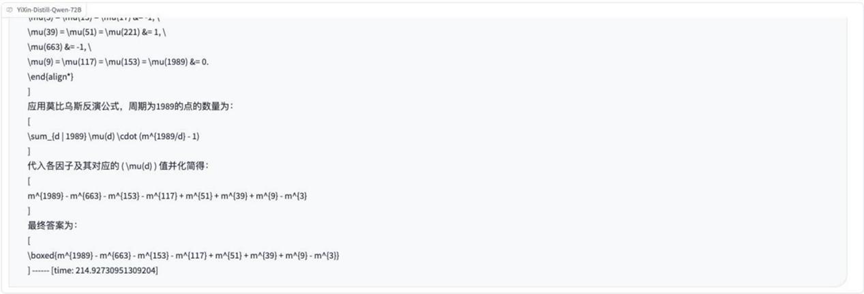
8라운드: 조합 최적화 문제(최대 삼각형)
질문: 공간에는 1989개의 점이 있으며, 그 중 세 개는 선을 공유하지 않습니다. 이 점들은 각각 다른 수의 점을 가진 30개의 그룹으로 나뉩니다. 세 개의 다른 그룹에서 한 점을 꼭지점으로 삼아 삼각형을 만들 수 있습니다. 질문: 형성되는 삼각형의 수를 최대화하기 위해 각 그룹의 점 수를 어떻게 분배할 수 있나요?
분석: 이것은 조합수학의 최적화 문제로, 조합 계산의 원리를 이해하고 최적의 할당 전략을 찾기 위해 보다 복잡한 수학적 모델링과 최적화 아이디어를 포함하는 모델을 필요로 합니다.
결과:o3-mini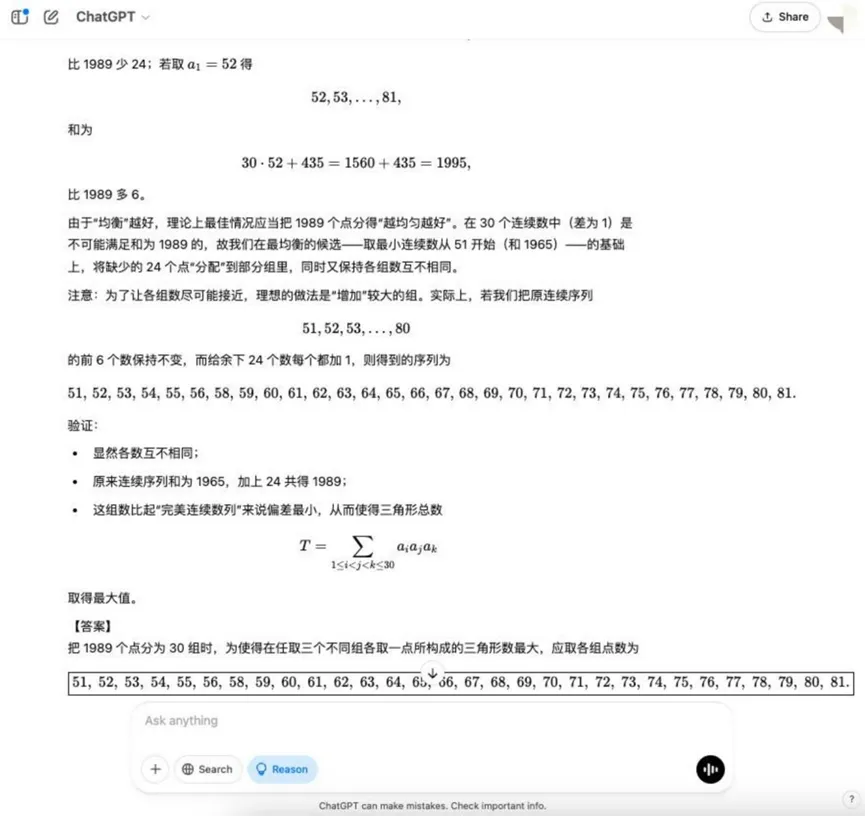
YiXin-Distill-Qwen-72B

조합 최적화 문제는 난이도를 더욱 높이고 모델의 수학적 전략과 계산 능력에 대한 요구가 더 높습니다.
9라운드: 수 이론 문제(인수분해)
문제 설명 그림:
분석: 다시 말하지만, 수 이론적 개념이 관련되어 있으며, 계승 및 적분과 같은 관계에 대한 모델의 이해와 적용을 검토하여 건설적인 증명이나 계산이 필요할 수 있습니다.
결과:o3-mini: 부분적으로 맞습니다.
YiXin-Distill-Qwen-72B: 맞습니다.

YiXin-Distill-Qwen-72B 이 계산 주제에 대한 견고한 성능.
10라운드: 기하학 문제(등면적 포인트)
문제 설명 그림:
분석: 마지막 문제는 면적 계산, 점의 궤적 또는 존재 증명과 관련된 기하학적 문제로, 모델의 기하학적 직관, 대수 연산 및 논리적 추론을 테스트합니다.
결과:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B

최종 기하학 문제에서도 복잡한 기하학 문제를 처리하는 능력에서 모델 간에 차이를 보였습니다.
관찰 및 분석
여러 대규모 언어 모델에 대한 이 중국어 수학 능력 테스트를 기반으로 다음과 같은 관찰을 할 수 있습니다:
- 모델 기반 수학 실력이 크게 향상됩니다: 이전 모델에 비해 현재 세대의 LLM은 기하학, 확률, 일부 개방형 응용 문제 등 다단계 추론이 필요한 수학적 문제를 처리하는 데 있어 상당한 향상을 보였습니다. 이는 모델 크기의 증가, 풍부한 학습 데이터, '사고 사슬'과 같은 추론 향상 기법의 사용으로 인한 것으로 볼 수 있습니다.
- 문제 해결 스타일에는 차이가 있습니다: 모델마다 솔루션 프로세스의 세부 수준 측면에서 다르게 작동합니다.
o3-mini,Grok 3 beta,Tongyi Qwen-32B출력은 비교적 간결하고 추론 단계도 간단합니다.DeepSeek R1,Hunyuan T1,YiXin-Distill-Qwen-72B때로는 반성 및 수정 단계를 포함하여 더 자세한 사고 과정을 보여주는 경향이 더 '장황'하지만, 이는 추론의 논리를 추적하는 데 도움이 될 수 있습니다.Gemini 2.0 Flash Thinking의 문제 해결 과정은 길 뿐만 아니라 주로 영어 출력을 사용하므로 중국어 수학 말뭉치에 대한 학습이 상대적으로 부족할 수 있습니다.
- 입력 오류에 대한 견고성: 테스트 결과, 문제 설명에 사소한 표기 오류나 표현상의 불규칙성이 있더라도 일부 모델은 문제의 의미를 정확하게 이해하고 답할 수 있어 어느 정도 견고함을 보여주었습니다. 그러나 이것이 모델이 항상 오류를 무시할 수 있다는 의미는 아니며, 중요한 정보의 오류는 여전히 정답 실패로 이어질 수 있습니다.
- 향후 개선 사항: 전문화 및 도구 통합: 분명한 진전에도 불구하고 복잡한 수학 문제, 특히 엄격한 증명이 필요한 어려운 대회 문제와 시나리오를 다룰 때 현재 LLM의 정확도는 여전히 개선의 여지가 있습니다. 향후 개선 경로에는 다음이 포함될 수 있습니다:
- 외부 컴퓨팅 엔진 통합: 정확한 계산과 기호 연산에서 LLM의 단점은 Wolfram Alpha와 같은 기호 계산 도구를 호출하여 보완할 수 있습니다.
- 도메인 전용 미세 조정: 수학적 논리, 수학의 특정 분야(예: 대수학, 기하학, 확률 이론)를 위해 고품질의 미세 조정된 데이터 세트를 구축하고, 전문가의 추론과 깊이 있는 지식을 위한 모델을 강화합니다.
- 대화형 학습 및 복습: 사용자가 솔루션 프로세스를 안내하고, 실수를 지적하며, 모델이 솔루션 전략을 동적으로 조정할 수 있는 메커니즘을 개발하세요.
- 사용자를 위한 권장 사항:
- 학생: LLM은 기본적인 질문에 대한 해답과 답을 빠르게 확인하여 학습을 돕는 데 사용할 수 있습니다. 그러나 복잡하거나 창의적인 문제의 경우 모델이 '심각한 넌센스'(즉, 자신 있게 오답을 제시하는 것)를 유발할 수 있으므로 주의해야 합니다.
- 교육자: AI 보조 교수법을 사용할 때는 학생들이 피상적인 답을 얻기 위해 모델에 의존하지 않도록 학생들의 심층적인 이해와 독립적인 사고 능력을 테스트할 수 있는 질문을 설계해야 합니다.
- 개발자: 수학 문제 해결에 LLM을 적용할 때는 프롬프트 엔지니어링을 최적화하여 문제 경계와 솔루션 요구 사항을 명확히 하여 모호한 이해로 인한 모델의 비효율적인 추론이나 '브레인스토밍'을 줄여야 합니다.
결론적으로, 수학에서 대규모 언어 모델의 적용은 점차 탐색 단계에서 실용화 단계로 나아가고 있습니다. 앞으로의 모델 개발 방향은 인간 사고의 유연성을 시뮬레이션하는 것과 수학적 논리의 엄밀성을 보장하는 것 사이에서 더 나은 균형을 찾는 것이 될 것입니다.
참고:
이 리뷰에서 더 나은 성능 YiXin-Distill-Qwen-72B 모델 정보는 다음과 같습니다:
- 표준 버전: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B
- AWQ 정량적 에디션: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B-AWQ
- 로컬 배포 리소스 요구 사항: 72B 표준 에디션에는 약 8개의 NVIDIA 4090급 그래픽 카드가 필요하며, AWQ 정량적 에디션은 같은 등급의 카드 2개에서 실행할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...