

450달러라는 가격표는 언뜻 들으면 큰 금액처럼 보이지 않을 수 있습니다. 하지만 이것이 32억 개의 추론 모델을 훈련하는 데 드는 전체 비용이라면 어떨까요?
예, 2025년이 다가오면서 추론 모델 개발이 더욱 쉬워지고 있으며, 비용도 이전에는 상상할 수 없었던 수준으로 빠르게 감소하고 있습니다.
최근 버클리 캘리포니아 대학교 스카이 컴퓨팅 연구소의 노바스카이 연구팀은 스카이-T1-32B-프리뷰를 출시했는데, 연구팀은 "스카이-T1-32B-프리뷰는 훈련 비용이 450달러 미만으로 고수준 추론 능력을 경제적이고 효율적으로 복제할 수 있음을 시사한다"고 설명했습니다.

- 프로젝트 홈페이지: https://novasky-ai.github.io/posts/sky-t1/
- 오픈 소스 주소: https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
공식 정보에 따르면, 이 추론 모델은 여러 주요 벤치마크에서 이전 버전의 OpenAI o1과 일치했습니다.

중요한 점은 Sky-T1이 최초의 진정한 오픈 소스 추론 모델인 것처럼 보이는데, 팀이 훈련 데이터 세트와 함께 누구나 처음부터 이를 복제할 수 있도록 필요한 훈련 코드를 공개했기 때문입니다.
사람들은 "데이터, 코드, 모델 가중치가 얼마나 놀라운 기여를 했는지 알 수 있습니다."라고 감탄했습니다.
얼마 전까지만 해도 동등한 성능의 모델을 학습시키는 데 드는 비용은 수백만 달러에 달했습니다. 합성 학습 데이터 또는 다른 모델에서 생성된 학습 데이터를 사용하면 비용을 크게 절감할 수 있습니다.
이전에 인공지능 회사인 Writer는 거의 전적으로 합성 데이터로 학습한 팔미라 X 004를 출시했는데, 개발 비용이 70만 달러에 불과했습니다.
이 프로그램을 3,000달러(슈퍼컴퓨터로서는 저렴한 가격)에 최대 2,000억 개의 파라미터를 가진 모델을 실행할 수 있는 Nvidia Project Digits AI 슈퍼컴퓨터에서 실행한다고 상상해 보세요. 가까운 미래에는 1조 개 미만의 파라미터를 가진 모델을 개인이 로컬에서 실행할 수 있게 될 것입니다.
2025년 대형 모델의 기술 발전이 가속화되고 있으며, 이는 매우 강력한 느낌입니다.
모델 개요
추론 o1 및 쌍둥이자리 플래시 사고와 같은 2.0 모델은 내부적으로 긴 사고의 사슬을 생성하여 복잡한 작업을 해결하고 다른 진전을 이루었습니다. 하지만 기술적 세부 사항과 모델 가중치가 제공되지 않아 학계와 오픈 소스 커뮤니티의 참여를 가로막는 장벽이 되고 있습니다.
이를 위해 수학 분야에서는 Still-2 및 Journey와 같은 개방형 가중치 추론 모델을 훈련하는 데 주목할 만한 성과가 있었으며, 캘리포니아 버클리 대학의 NovaSky 팀은 기본 모델과 명령 조정 모델의 추론 기능을 개발하기 위해 다양한 기술을 연구하고 있습니다.
이 작업인 Sky-T1-32B-Preview에서 팀은 수학적 측면뿐만 아니라 동일한 모델의 코딩 측면에서도 경쟁력 있는 추론 성능을 달성했습니다.

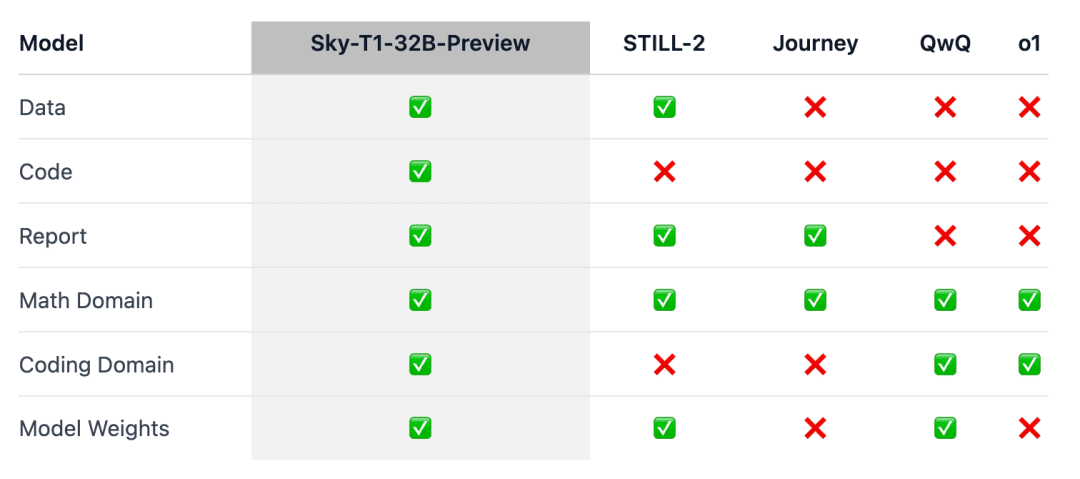
이 작업이 '더 많은 커뮤니티에 도움이 되도록' 하기 위해 팀은 모든 세부 사항(예: 데이터, 코드, 모델 가중치)을 오픈소스화하여 커뮤니티에서 쉽게 복제하고 개선할 수 있도록 했습니다:
- 인프라: 단일 리포지토리에서 데이터 구축, 모델 학습 및 평가를 수행할 수 있습니다;
- 데이터: Sky-T1-32B-Preview 훈련에 사용된 17K 데이터;
- 기술 세부 정보: 기술 보고서 및 wandb 로그;
- 모델 가중치: 32B 모델 가중치.
기술 세부 정보
데이터 대조 프로세스
훈련 데이터를 생성하기 위해 팀은 o1-preview와 비슷한 추론 기능을 갖춘 오픈 소스 모델인 QwQ-32B-Preview를 사용했습니다. 팀은 추론이 필요한 다양한 도메인을 포괄하도록 데이터 조합을 구성하고 데이터의 품질을 개선하기 위해 거부 샘플링 절차를 사용했습니다.
그런 다음 팀은 Still-2에서 영감을 받아 데이터 품질을 개선하고 구문 분석을 간소화하기 위해 GPT-4o-mini를 사용하여 QwQ 추적을 구조화된 버전으로 재작성했습니다.
연구진은 구문 분석의 단순성이 추론 모델에 특히 유용하다는 사실을 발견했습니다. 추론 모델은 특정 형식으로 응답하도록 훈련되어 있으며, 그 결과는 종종 구문 분석하기 어렵습니다. 예를 들어, 앱 데이터 세트의 경우, 형식을 다시 지정하지 않으면 팀이 코드가 마지막 코드 블록에 작성되었다고 가정할 수밖에 없었고, QwQ는 약 25%의 정확도만 달성할 수 있었습니다. 그러나 때로는 코드가 중간에 작성될 수 있으며, 포맷을 다시 지정한 후에는 정확도가 90% 이상으로 증가합니다.
샘플 거부. 데이터 세트와 함께 제공된 솔루션에 따라, QwQ 샘플이 부정확한 경우 팀은 해당 샘플을 폐기합니다. 수학 문제의 경우, 팀은 기준값 솔루션과 정확히 일치하는지 확인합니다. 코딩 문제의 경우, 팀은 데이터 세트에 제공된 단위 테스트를 수행합니다. 팀의 최종 데이터는 앱과 TACO의 코딩 데이터 5천 개와 AIME, MATH, NuminaMATH 데이터 세트의 올림피아드 하위 집합의 수학 데이터 1만 개로 구성됩니다. 또한, STILL-2의 과학 및 퍼즐 데이터 1,000개도 보유했습니다.
기차
팀은 훈련 데이터를 사용하여 추론 기능이 없는 오픈 소스 모델인 Qwen2.5-32B-Instruct를 미세 조정했습니다. 모델은 3개의 에포크, 1e-5의 학습률, 96의 배치 크기를 사용하여 훈련되었습니다. 모델 훈련은 8개의 H100에서 19시간 만에 완료되었으며, 딥스피드 제로-3 오프로드를 사용했습니다(람다 클라우드에 따르면 가격은 약 450달러). 팀은 훈련에 Llama-Factory를 사용했습니다.
평가 결과
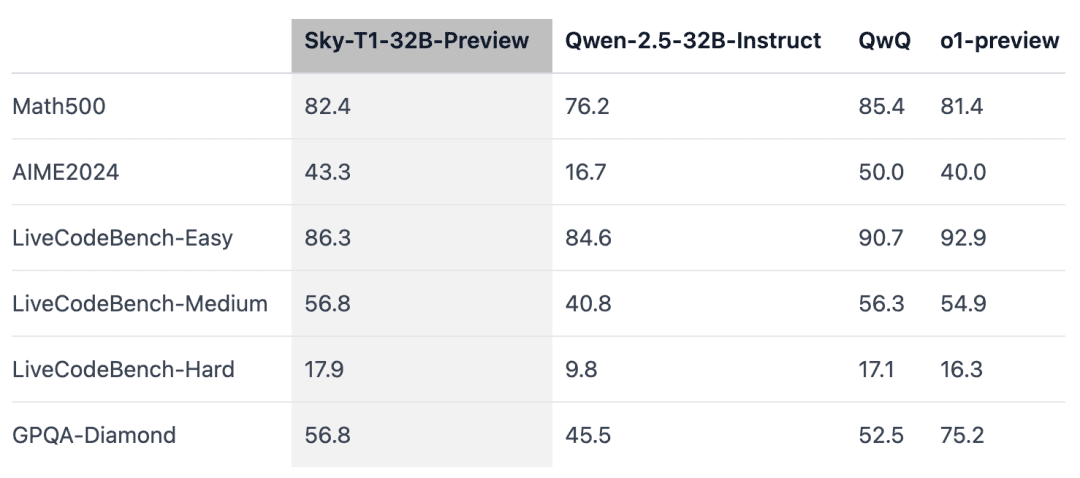
Sky-T1은 '대회 수준의' 수학 문제인 MATH500에서 이전 버전의 o1을 능가했으며, 코딩 평가인 LiveCodeBench의 퍼즐 세트에서도 o1의 프리뷰 버전을 앞질렀습니다. 그러나 Sky-T1은 박사 졸업생이 알아야 할 물리학, 생물학, 화학 관련 문제가 포함된 GPQA-Diamond의 o1 프리뷰 버전에는 미치지 못했습니다.
그러나 OpenAI의 o1 GA 릴리스는 o1 프리뷰 버전보다 더 강력하며, OpenAI는 앞으로 몇 주 내에 더 나은 성능의 추론 모델인 o3를 출시할 예정입니다.
주목해야 할 새로운 발견
모델 크기가 중요합니다.처음에는 더 작은 모델(7B 및 14B)로 훈련을 시도했지만 거의 개선되지 않았습니다. 예를 들어, 앱 데이터 세트에서 Qwen2.5-14B-Coder-Instruct를 훈련하면 LiveCodeBench에서 성능이 42.6%에서 46.3%로 약간 향상되었지만, 더 작은 모델(32B 미만)의 결과를 수동으로 검토한 결과 중복 콘텐츠가 자주 생성되는 것을 발견했습니다. 효과가 제한된다는 사실을 발견했습니다.
데이터 통합은 중요합니다.연구팀은 처음에 Numina 데이터 세트(STILL-2에서 제공)의 3~4천 개의 수학 문제를 사용하여 32B 모델을 훈련시켰고, AIME24의 정확도는 16.7%에서 43.3%로 크게 향상되었지만, 앱스 데이터 세트에서 생성된 프로그래밍 데이터를 훈련 과정에 통합하자 AIME24의 정확도는 36.7%로 떨어졌습니다. 이러한 하락은 수학과 프로그래밍 작업에 필요한 추론 방법이 다르기 때문일 수 있습니다.
프로그래밍 추론에는 일반적으로 테스트 입력을 시뮬레이션하거나 생성된 코드를 내부적으로 실행하는 등의 추가적인 논리적 단계가 포함되지만, 수학적 문제에 대한 추론은 보다 간단하고 구조화된 경향이 있습니다.이러한 차이를 해결하기 위해 연구팀은 NuminaMath 데이터 세트의 어려운 수학 문제와 TACO 데이터 세트의 복잡한 프로그래밍 작업으로 훈련 데이터를 강화했습니다. 이렇게 균형 잡힌 데이터 조합을 통해 모델은 두 영역 모두에서 뛰어난 성능을 발휘하여 AIME24에서 43.3%의 정확도를 회복하는 동시에 프로그래밍 기능도 개선할 수 있었습니다.
동시에 일부 연구자들은 회의적인 반응을 보이기도 합니다:


사람들은 이에 대해 어떻게 생각하나요? 댓글 섹션에서 자유롭게 토론해 주세요.
참조 링크: https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...