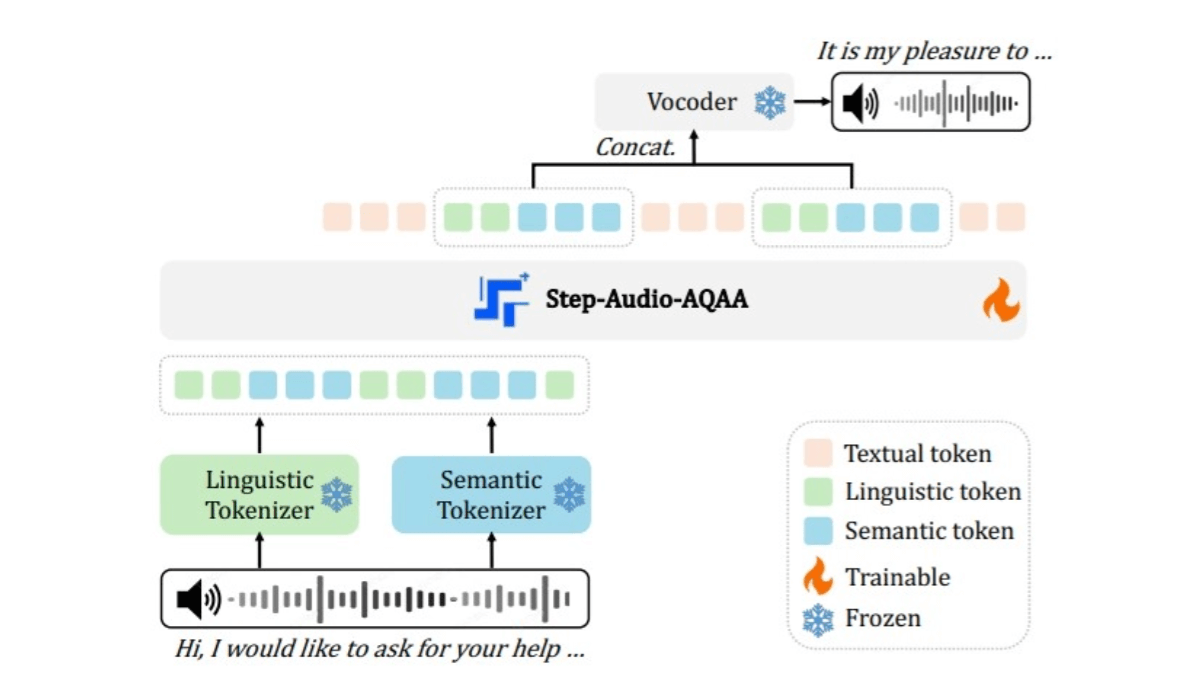
Qwen-TTS est un modèle de synthèse vocale avancé introduit par Ali Tongyi. Le modèle peut convertir efficacement un texte en une parole naturelle et fluide, en prenant en charge plusieurs langues et dialectes, tels que le mandarin, l'anglais, le dialecte de Pékin, etc., afin de répondre aux besoins de différentes régions et scènes. S'appuyant sur un corpus d'entraînement massif, le modèle produit une parole de haute qualité, rimant...










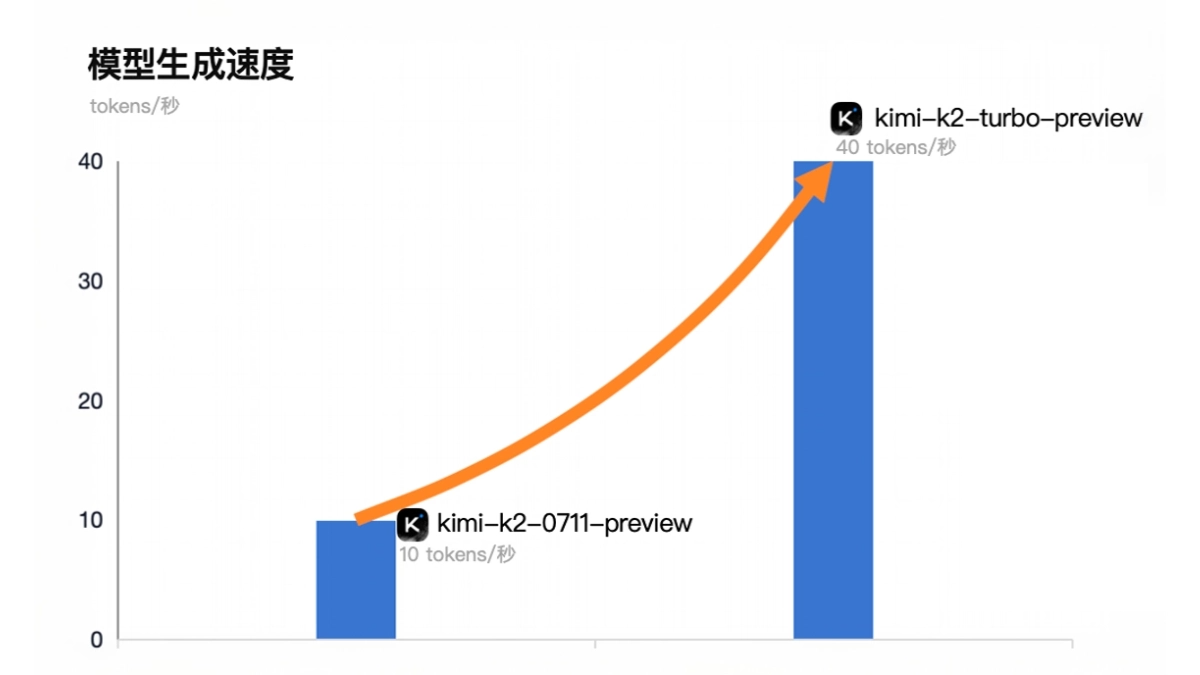
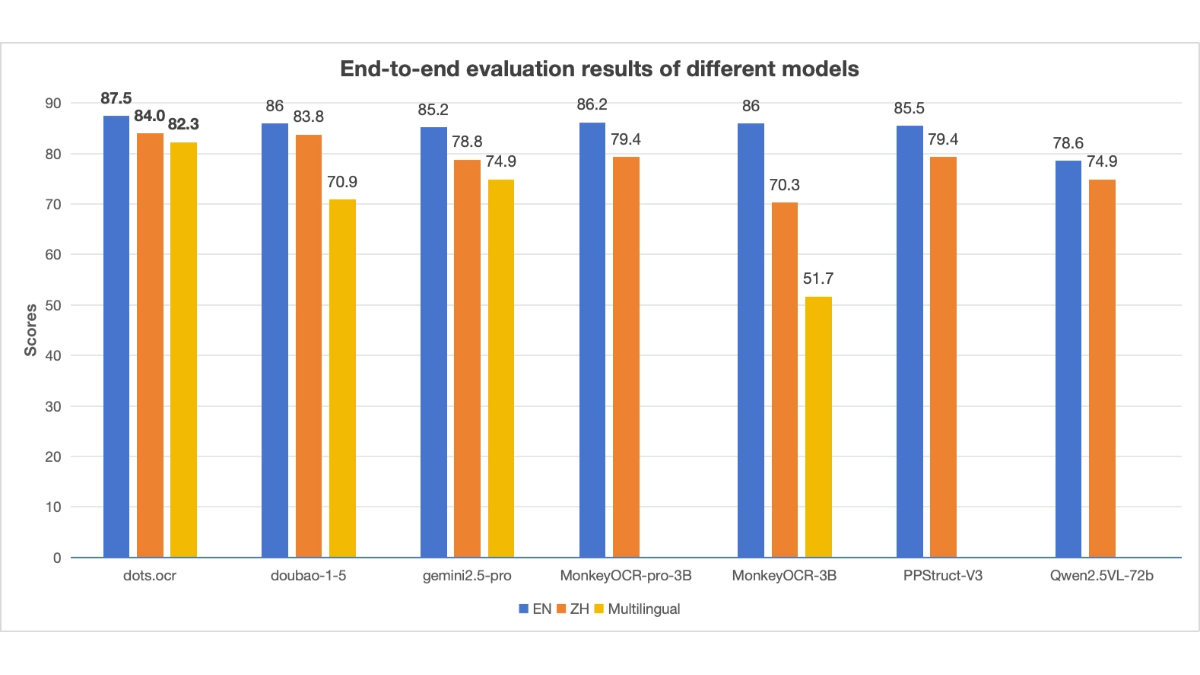
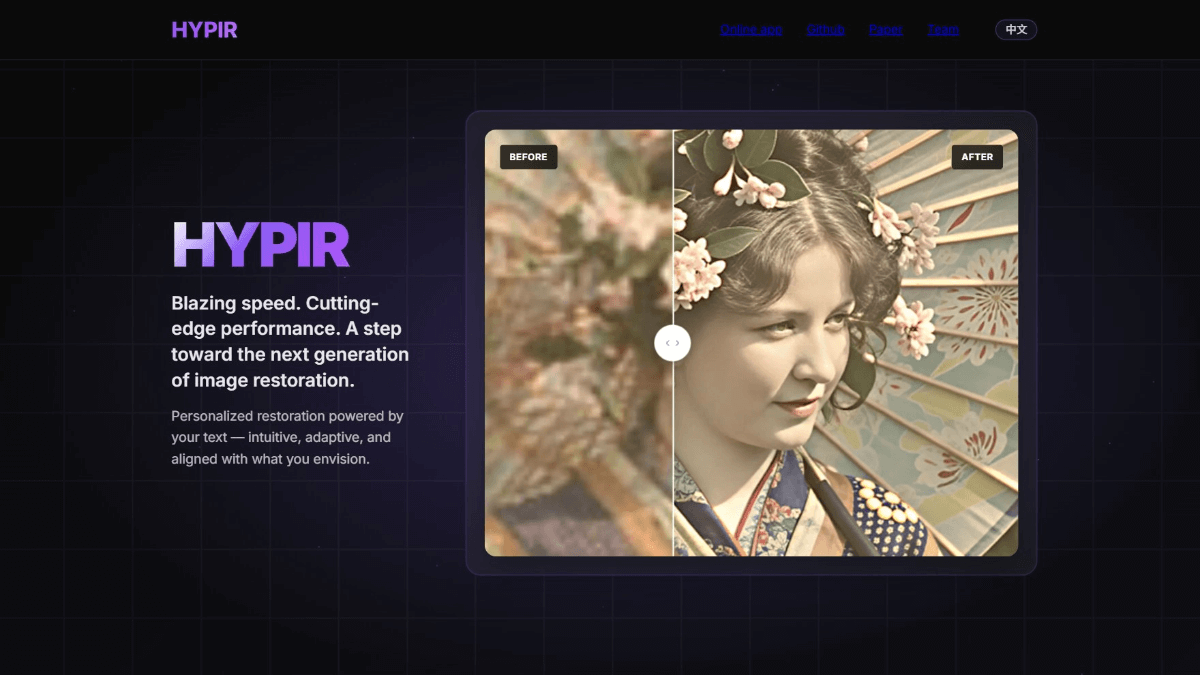
![FLUX.1 Krea [dev] - 黑森林和Krea AI联合推出的文生图模型](https://aisharenet.com/wp-content/uploads/2025/08/1754032748-1754032748-FLUX.1-Krea-dev-website-2.png)