
《大模型基础》深入剖析大语言模型(LLMs)的核心技术与实践路径。从语言模型的基础理论入手,系统讲解基于统计、循环神经网络(RNN)和Transformer架构的模型设计原理,重点探讨大语言模型的三大主流架构(Encoder-only、Encoder-Decoder、Decoder-only)及代表性模型(如BERT、T5、GPT系列)。书中深入讲解Prompt工程、参数高效微调、模型编辑和检索增强生成等关键技术,结合丰富案例,展示在不同场景下的应用实践,为读者提供全面深入的学习和实践指导,助力读者掌握大语言模型技术的应用与优化。

语言模型基础
- 基于统计方法的语言模型:深入剖析n-gram模型及其背后的统计学原理,包括马尔可夫假设和极大似然估计。
- 基于RNN的语言模型:详细讲解循环神经网络(RNN)的结构特点、训练中常见的梯度消失与爆炸问题,及在语言建模中的实际应用。
- 基于Transformer的语言模型:全面解析Transformer架构的核心组件,如自注意力机制、前馈神经网络(FFN)、层归一化和残差连接,及在语言模型中的高效应用。
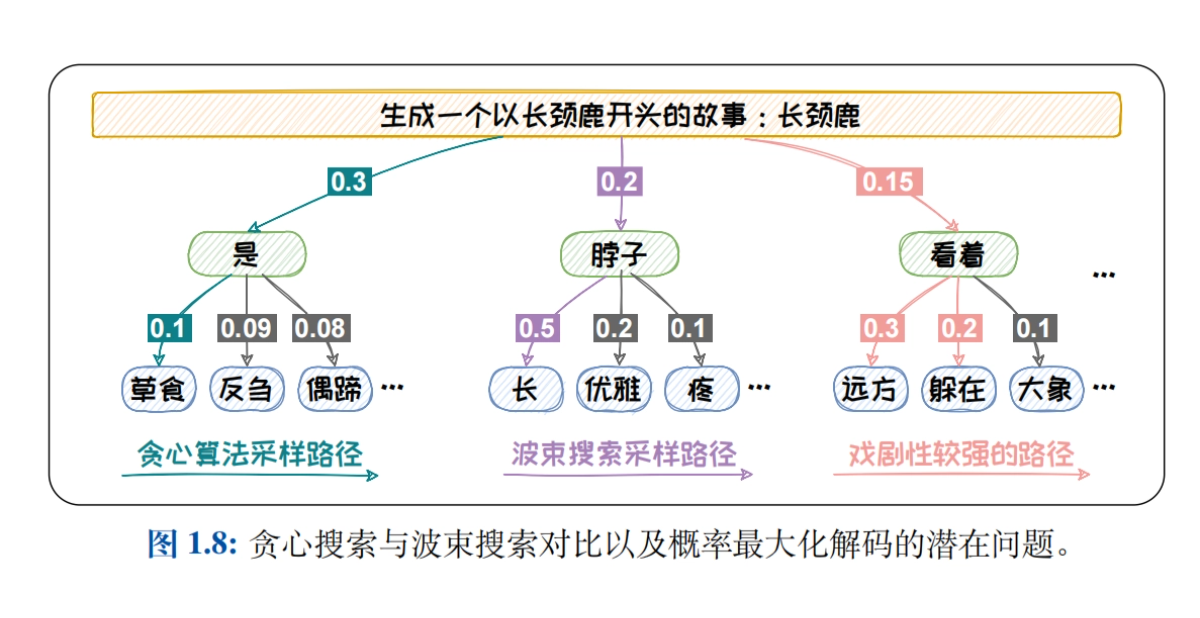
- 语言模型的采样方法:系统介绍贪心搜索、波束搜索、Top-K采样、Top-P采样和Temperature机制等解码策略,探讨不同策略对生成文本质量的影响。
- 语言模型的评测:详细介绍内在评测指标(如困惑度)和外在评测指标(如BLEU、ROUGE、BERTScore、G-EVAL),分析各指标在评估语言模型性能时的优势与局限。
大语言模型架构
- 大数据 + 大模型 → 新智能:深入分析模型规模与数据规模对模型能力的影响,详细解读Scaling Laws(如Kaplan-McCandlish法则和Chinchilla法则),探讨如何通过优化模型与数据规模提升模型性能。
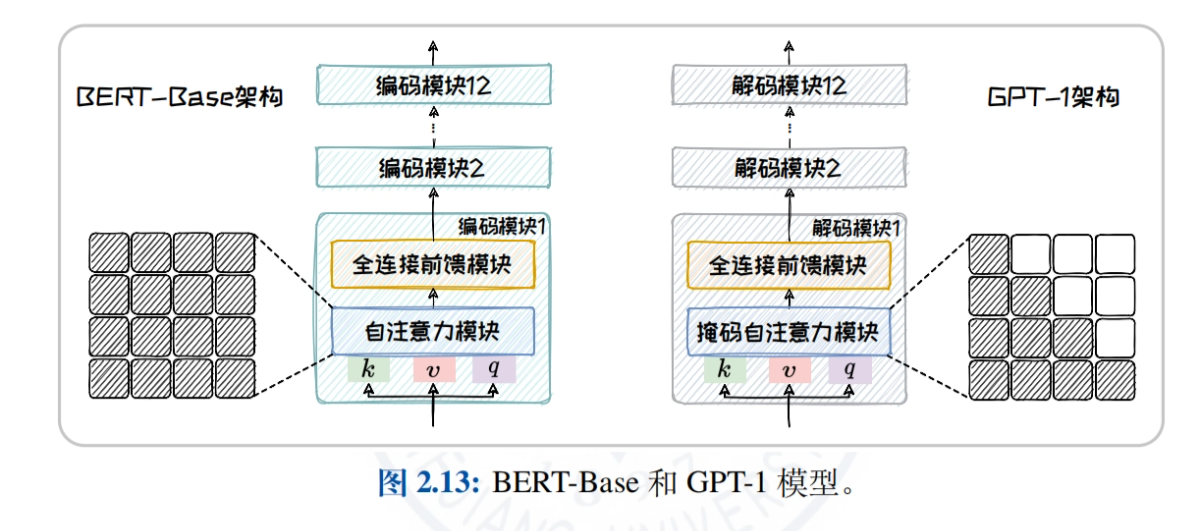
- 大语言模型架构概览:对比分析Encoder-only、Encoder-Decoder、Decoder-only三种主流架构的注意力机制和适用任务,帮助读者理解不同架构的特点与优势。
- Encoder-only架构:以BERT为例,深入讲解其模型结构、预训练任务(如MLM、NSP)及衍生模型(如RoBERTa、ALBERT、ELECTRA),探讨模型在自然语言理解任务中的应用。
- Encoder-Decoder架构:以T5和BART为例,介绍统一文本生成框架和多样化的预训练任务,分析模型在机器翻译、文本摘要等任务中的表现。
- Decoder-only架构:详细介绍GPT系列(从GPT-1到GPT-4)和LLaMA系列(LLaMA1/2/3)的发展历程与特点,探讨模型在开放域文本生成任务中的优势。
- 非Transformer架构:介绍状态空间模型(SSM)如RWKV、Mamba,及测试时训练(TTT)范式,探讨非主流架构在特定场景下的应用潜力。
Prompt工程
- Prompt工程简介:定义Prompt和Prompt工程,详细讲解分词与向量化过程(Tokenization、Embedding),探讨如何通过精心设计的Prompt引导模型生成高质量的文本。
- 上下文学习(In-Context Learning, ICL):介绍零样本、单样本、少样本学习的概念,探讨示例选择策略(如相似性和多样性),分析如何通过上下文学习提升模型的任务适应能力。
- 思维链(Chain-of-Thought, CoT):讲解CoT的三种模式:按部就班(如CoT、Zero-Shot CoT、Auto-CoT)、三思后行(如ToT、GoT)和集思广益(如Self-Consistency),探讨如何通过思维链提升模型的推理能力。
- Prompt技巧:介绍规范Prompt编写、合理归纳提问、适时使用CoT、善用心理暗示(如角色扮演、情景代入)等技巧,帮助读者提升Prompt设计的水平。
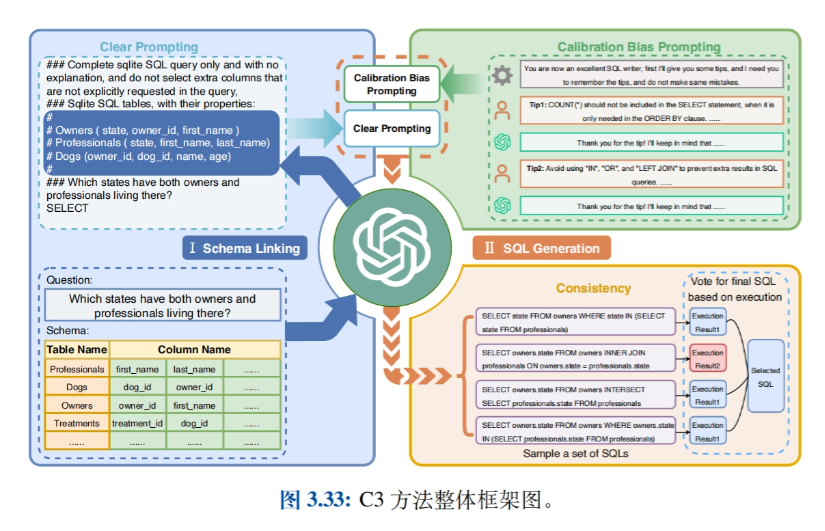
- 相关应用:介绍基于大模型的智能体(Agent)、数据合成、Text-to-SQL、GPTS等应用,探讨Prompt工程在不同领域的实际应用案例。
参数高效微调
- 参数高效微调简介:介绍下游任务适配的两种主流方法——上下文学习和指令微调,引出参数高效微调(PEFT)技术,详细阐述在降低成本和提高效率方面的显著优势。
- 参数附加方法:详细介绍通过在模型结构中附加新的、较小的可训练模块实现高效微调的方法,包括加在输入(如Prompt-tuning)、加在模型(如Prefix-tuning和Adapter-tuning)和加在输出(如Proxy-tuning)的实现与优势。
- 参数选择方法:介绍仅选择模型的一部分参数进行微调的方法,分为基于规则的方法(如BitFit)和基于学习的方法(如Child-tuning),探讨如何通过选择性更新参数减少计算负担、提升模型性能。
- 低秩适配方法:详细介绍通过低秩矩阵近似原始权重更新矩阵实现高效微调的方法,重点介绍LoRA及其变体(如ReLoRA、AdaLoRA和DoRA),讨论LoRA的参数效率和任务泛化能力。
- 实践与应用:介绍HF-PEFT框架的使用方法和相关技巧,展示PEFT技术在表格数据查询和表格数据分析中的应用案例,证明PEFT在提升大模型特定任务性能方面的有效性。
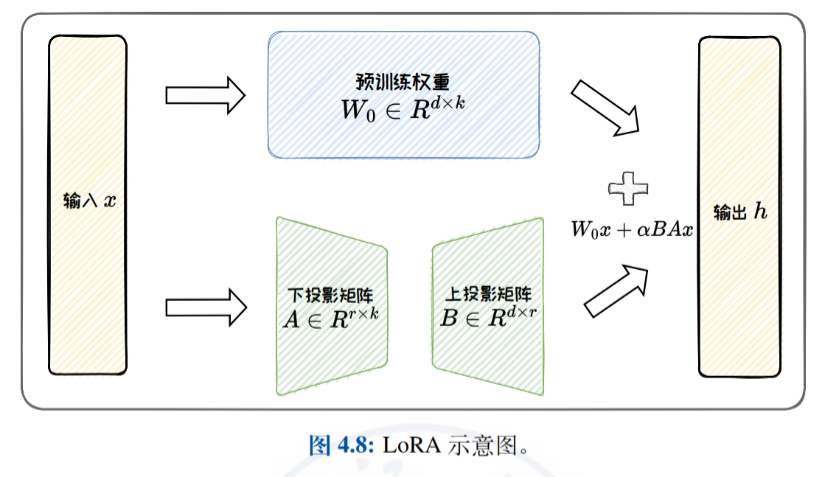
模型编辑
- 模型编辑简介:介绍模型编辑的思想、定义和性质,详细阐述模型编辑在纠正大语言模型中的偏见、毒性和知识错误等方面的重要性。
- 模型编辑经典方法:将模型编辑方法分为外部拓展法(如知识缓存法和附加参数法)和内部修改法(如元学习法和定位编辑法),介绍每类方法的代表性工作。
- 附加参数法:T-Patcher:详细介绍T-Patcher方法,通过在模型中附加特定参数实现对模型输出的精确控制,适用需要快速、精准修正模型特定知识点的场景。
- 定位编辑法:ROME:详细介绍ROME方法,通过定位和修改模型内部特定层或神经元实现对模型输出的精确控制,适用需要深度修改模型内部知识结构的场景。
- 模型编辑应用:介绍模型编辑在精准模型更新、保护被遗忘权和提升模型安全等方面的实际应用,展示模型编辑技术在不同场景中的应用潜能。
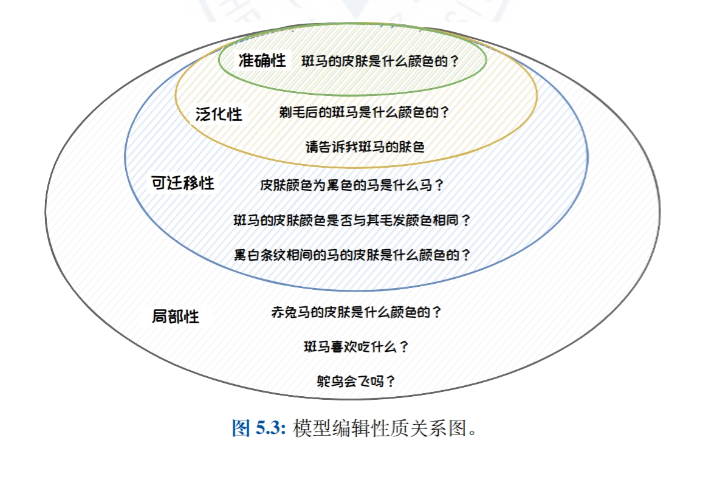
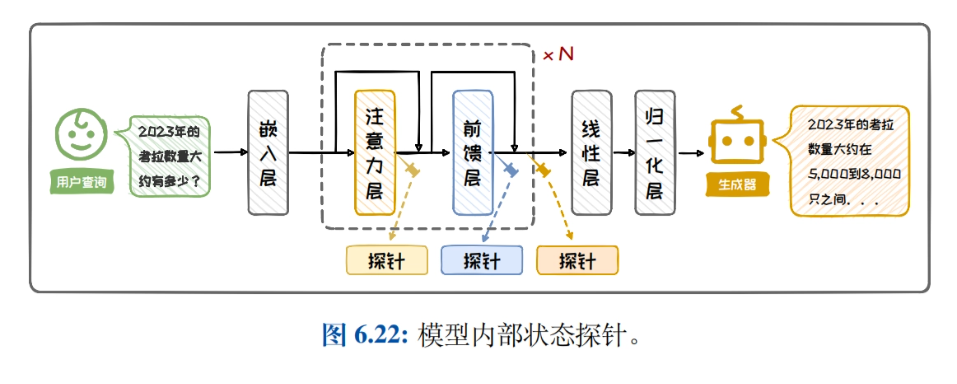
检索增强生成
- 检索增强生成简介:介绍检索增强生成的背景和组成,详细阐述在自然语言处理任务中通过结合检索和生成提升模型性能的重要性和应用场景。
- 检索增强生成架构:介绍RAG架构分类、黑盒增强架构和白盒增强架构,对比分析不同架构的特点和适用场景,帮助读者选择合适的架构。
- 知识检索:详细介绍知识库构建、查询增强、检索器和检索效率增强的方法,探讨如何通过检索结果重排提升检索效果,优化知识检索过程。
- 生成增强:介绍何时增强、何处增强、多次增强和降本增效的方法,讨论生成增强在不同任务中的应用策略,提升生成文本的质量和效率。
- 实践与应用:介绍搭建简单RAG系统的步骤,展示RAG在典型应用中的案例,帮助读者理解和应用检索增强生成技术,提升模型在实际任务中的表现。
资源资料下载地址
《大模型基础》报告下载地址: https://url23.ctfile.com/f/65258023-8434020435-605e6e?p=8894 (访问密码: 8894)
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...