

文档图像理解技术旨在让计算机能够像人类一样理解文档图像中的内容。它主要涉及对扫描或拍摄得到的文档图像(如纸质合同、书籍页面、发票等)进行分析、处理和理解,提取其中有价值的信息,如文字、表格、图表等,并对这些信息进行结构化处理。在当今数字化转型的浪潮中,文档图像理解技术广泛应用于企业、学术和日常生活,以提升文档处理效率与准确性。
此前,结合文心大模型,飞桨发布了PP-ChatOCRv3 大小模型融合方案,先采用OCR技术提取图像中的文本,再输入文心大模型进行分析问答,最终大幅提升了文本图像版面解析和信息抽取效果。该方案在文字和表格上的准确度很高,但对于文档中图像和图表理解能力需进一步提升。因此,为了更好满足用户对复杂多样的文档图像理解任务的需求,我们提出了新的方案PP-DocBee,基于多模态大模型实现端到端的文档图像理解。它可以高效地应用在各类场景的文档理解、文档问答等,尤其是对中文的文档类理解的场景,例如:财报、法律法规、论文、说明书、合同、研报等,表现非常优异。
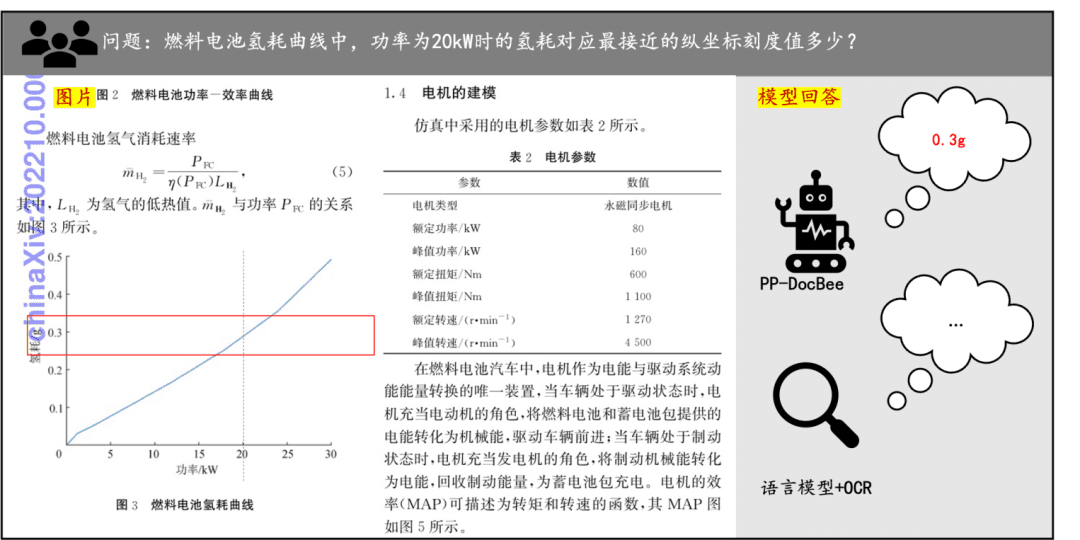
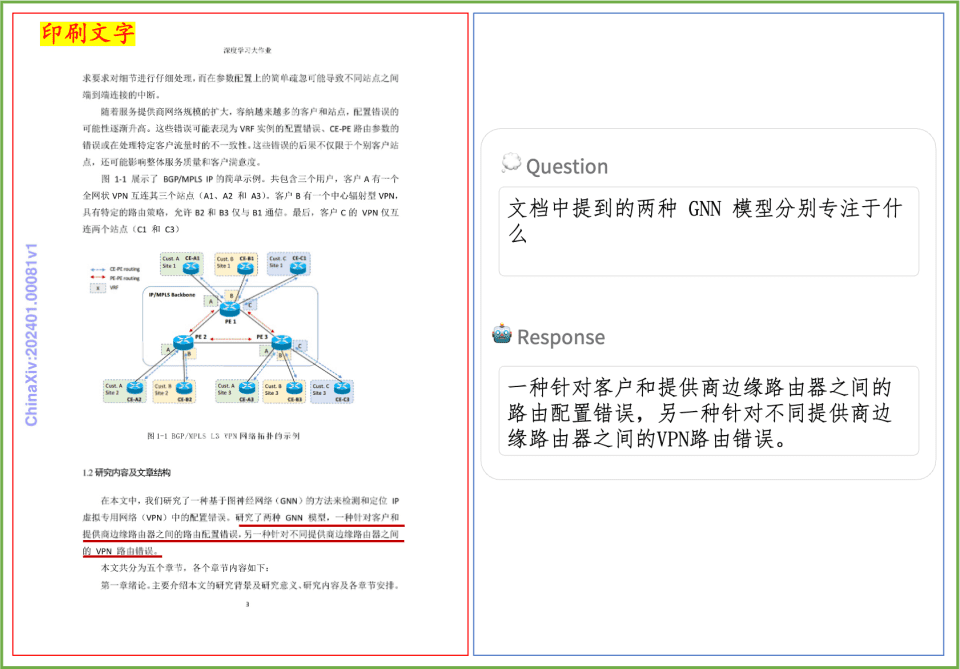
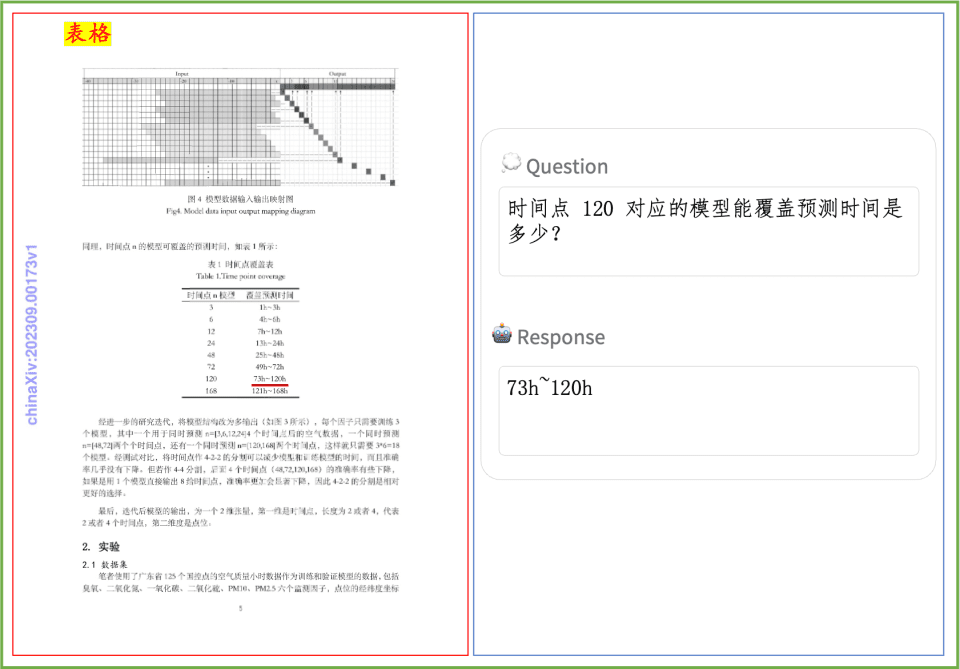
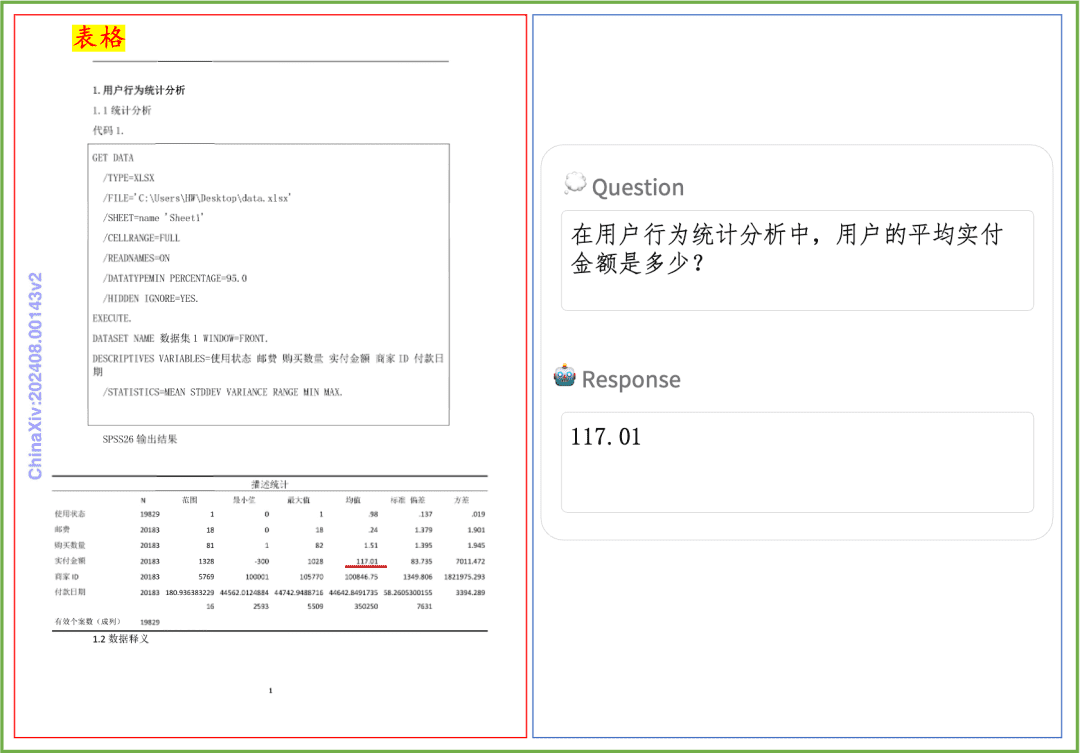
文档理解示例PP-DocBee在印刷文字、表格、图表等文档理解效果速览:


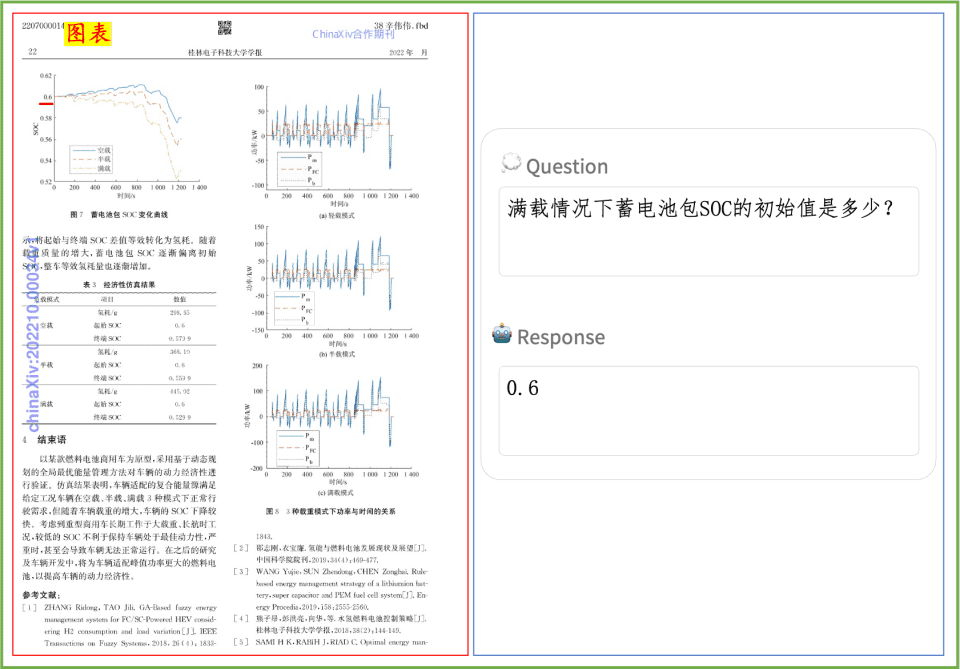
在学术界权威的几个英文文档理解评测榜单上,PP-DocBee基本都达到了同参数量级别模型的SOTA。
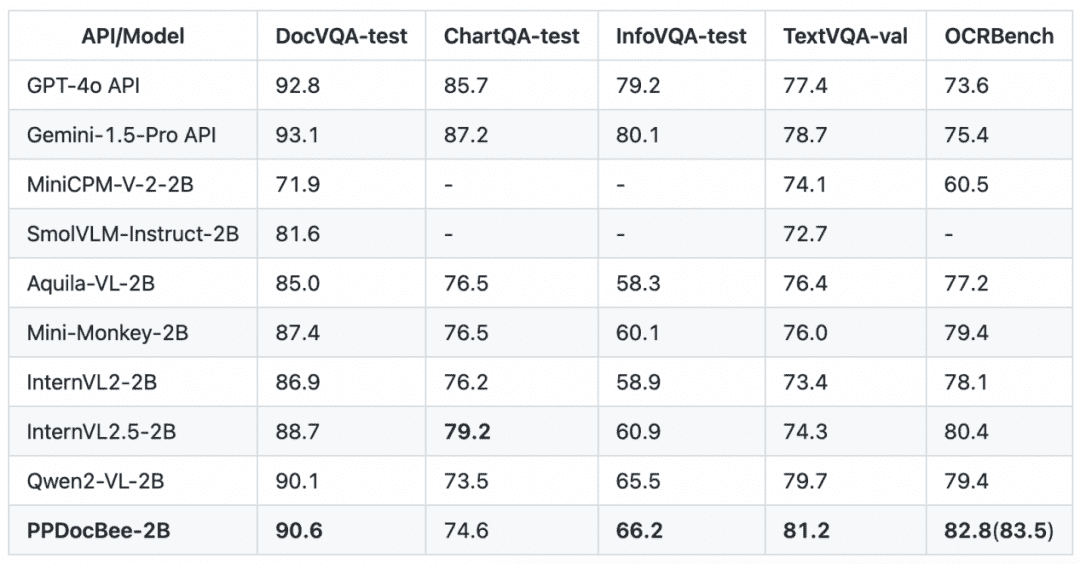
英文文档理解评测榜单竞品对比
注:OCRBench指标归一化到100分制,PPDocBee-2B的OCRBench指标中,82.8是端到端评估的分数,83.5是OCR后处理辅助评估的分数。在内部业务中文场景类的指标上,PP-DocBee也高于目前的热门开源和闭源模型。
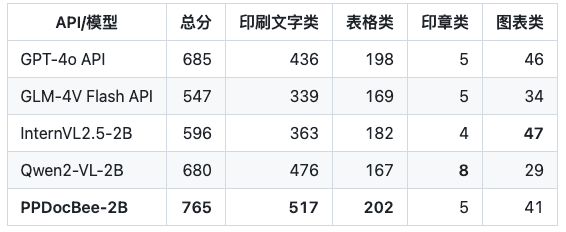
业务中文场景竞品对比
注:内部业务中文场景评估集包括了财报、法律法规、理工科论文、说明书、文科论文、合同、研报等场景,分为印刷文字类、表格类、印章类、图表类4大类。
为进一步提高PP-DocBee推理性能,我们通过算子融合优化,实现推理耗时降低51.5%,端到端总耗时降低41.9%,如下表所示:
| PP-DocBee | 平均端到端耗时(s) | 平均预处理耗时(s) | 平均推理耗时(s) |
| 默认版 | 1.60 | 0.29 | 1.30 |
| 高性能版 | 0.93 | 0.29 | 0.63 |
注:高性能版在相同输入token量情况下,输出token量和默认版基本一致。得益于飞桨高性能优化,PP-DocBee响应更加迅速,同时保持了回答的质量。该高性能推理版本,具体可以参考:https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee
同时,我们也提供了飞桨星河社区在线体验环境,可以通过飞桨星河社区应用中心(https://aistudio.baidu.com/application/detail/60135)快速体验 PP-DocBee 的功能。
此外,我们还提供了本地gradio部署、OpenAI服务部署,以及详细的使用指南,欢迎广大用户和兴趣爱好者前往项目主页查看:https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/examples/ppdocbee
PP-DocBee方案介绍
PP-DocBee模型结构如下图所示,采用ViT+MLP+LLM的架构。针对文档理解场景的优化思路包括了数据合成策略、数据预处理、训练方式以及OCR后处理辅助,最终使得模型既有通用的文档理解能力,又有较强的中文场景文档解析能力。

PP-DocBee模型结构
具体来看,PP-DocBee主要包括以下几个方面的改进:
1.数据合成策略
针对中文能力不足、场景数据欠缺等问题,我们设计了文档类数据智能生产方案,针对Doc、Table、Chart等三大类数据集分别设计了不同的数据生成链路,并采用了众多策略:OCR小模型与LLM大模型结合、基于渲染引擎生产图像数据、各文档类型定制的数据生产prompt模版等,使得问答质量更高,生成成本可控。具体如下图所示:
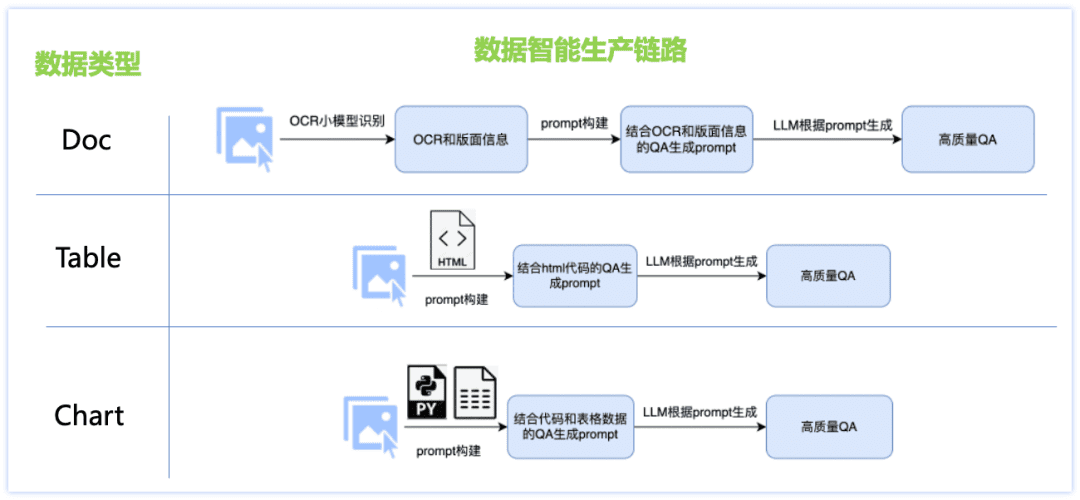
Doc类数据:
图片:收集和整理论文、财报、研报等pdf文件,结合pdf分析工具,生产海量单页文档图片数据;
问答:通过ocr小模型提取出详细的图片版面信息,从而弥补大模型视觉感知上的不足,同时利用大语言模型强大的文本理解能力修正ocr小模型个别字符识别不准确的问题,两者结合可以产生更高质量且类型可控的问答。
Table类数据:
图片:基于包含html文本信息的表格图片,通过大语言模型更改文本中的 数值、主题等信息,并通过表格渲染工具得到内容丰富的高质量表格图片;
问答:将表格图片对应的html格式的文本作为GT辅助信息,确保答案的精确性,设计微调prompt通过大语言模型生产高质量问答。
Chart类数据:
图片:基于众测的高质量图表源数据(图片-代码-table数据),通过大语言模型随机更改代码中图表的 数值、坐标轴、图例、主题等细粒度信息,得到内容多样的源代码,通过chart渲染工具(Matplotlib、Seaborn、Vega-Lite等)得到高质量的chart图片数据;
问答:将chart图片对应的代码和table数据作为GT辅助信息,确保答案的精确性,并针对不同类型图表设计对应类型问题,设计微调prompt通过大语言模型生产高质量问答。通过以上文档类数据智能生产方案我们得到了海量合成数据,并筛选出其中的部分数据作为PP-DocBee训练数据之一(数据分布如下图),有效提升了模型能力。
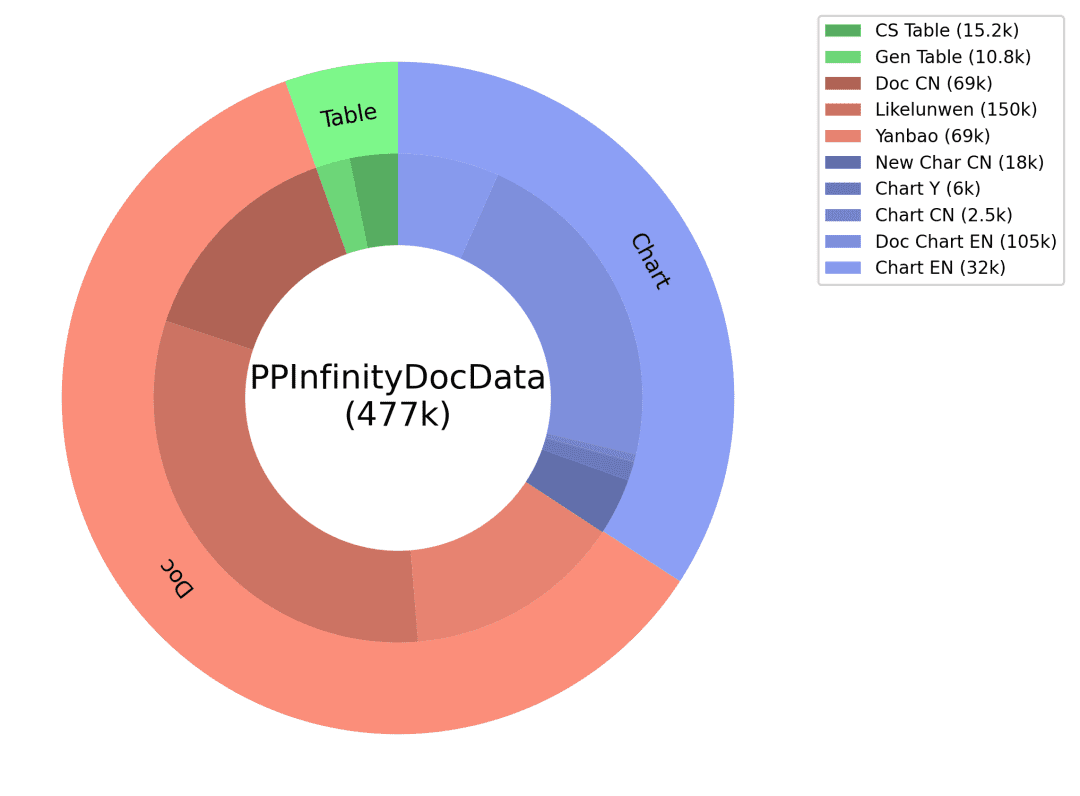
合成数据分布
2.数据预处理
包含两个策略,一是训练时设置更大的resize阈值,以增大数据集整体的分辨率分布;二是推理时对大部分常规图片设置等比例放大1.1~1.3倍,而对小分辨率的图片保持原有的数据预处理策略不变。这两个策略得到了更充足全面的视觉特征,从而提高了最终的理解能力。
3.训练方式
主要是混合了各种文档理解类数据,以及设置了数据配比机制。各种数据集包括了通用VQA类、OCR类、图表类、text-rich文档类、数学和复杂推理类、合成数据类、纯文本数据等;数据配比机制是对不同类和类间不同来源数据设置采样比例,是为了提高几类增益较大的数据的采样权重,以及平衡各类数据集的数量差异。
4.OCR后处理辅助
主要是通过OCR工具或模型提前得到OCR识别的文字结果,然后作为辅助先验信息提供在图片问答的问题中,再给PP-DocBee模型推理,可以在文字不多且清晰的图片上有一些效果提升。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...