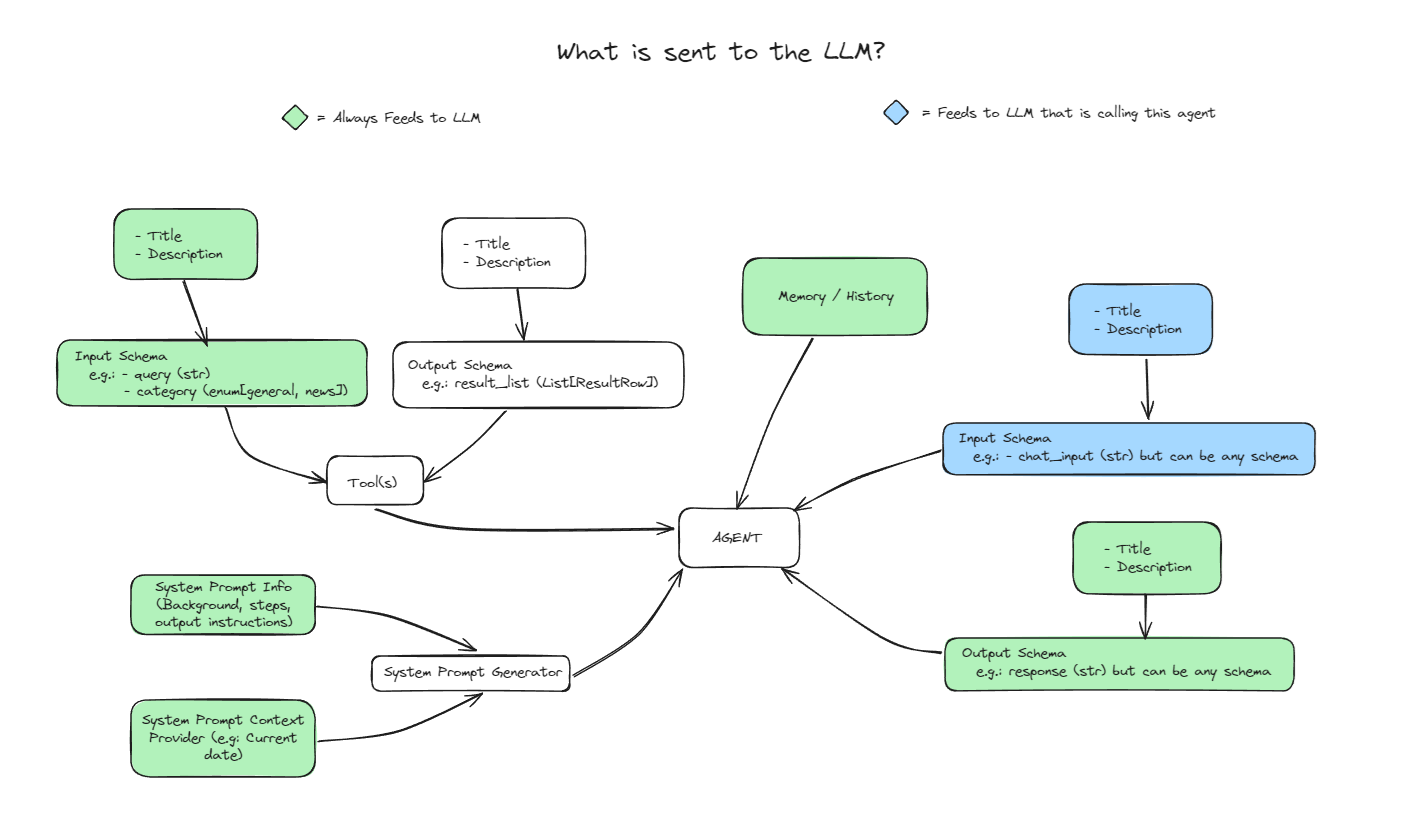
API de extracción de texto (text-extract-api): extracción visual de información textual, herramienta de extracción anónima de PDF
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 55K 00

Introducción general
La API de extracción de texto (text-extract-api) es una potente herramienta diseñada para extraer y analizar el contenido de diversos formatos de documento (por ejemplo, PDF, Word, PPTX, etc.). La API utiliza tecnología punta de reconocimiento óptico de caracteres (OCR) y modelos compatibles con Ollama para poder convertir cualquier documento o imagen en un formato estructurado JSON o Markdown. Entre sus principales características se incluyen la extracción de texto de alta precisión, la eliminación de información de identificación personal (PII), la compatibilidad con múltiples estrategias de almacenamiento y el procesamiento de tareas distribuidas. La API de extracción de texto está construida con FastAPI y utiliza Celery para el procesamiento asíncrono de tareas y Redis para almacenar en caché los resultados del OCR, a fin de garantizar una experiencia de procesamiento de documentos eficiente y fiable.
pdf-extract-api es una API de extracción y análisis sintáctico de documentos que soporta la anonimización de documentos utilizando tecnología OCR de última generación y modelos soportados por Ollama. Puede convertir cualquier documento o imagen en JSON estructurado o Markdown , soporta la extracción de alta precisión de datos tabulares , números y fórmulas matemáticas . Construida sobre FastAPI, la API utiliza Celery para el procesamiento asíncrono de tareas y Redis para almacenar en caché los resultados del OCR, garantizando un procesamiento de documentos eficiente y fiable.
:视觉提取文本信息,匿名化的PDF提取工具-1")

Lista de funciones
- OCR de alta precisión: utilice PyTorch, Marker, Llama3.2-vision y otras estrategias de OCR para lograr una extracción de texto de alta precisión.
- Conversión de documentos: soporte para PDF, Word, PPTX y otros documentos en formato Markdown o JSON.
- Eliminar PII: Identifica y elimina automáticamente la información de identificación personal de los documentos.
- Procesamiento distribuido: utilice Celery para el procesamiento distribuido de tareas con el fin de mejorar la eficacia del procesamiento.
- Mecanismo de almacenamiento en caché: Utiliza Redis para almacenar en caché los resultados de OCR para reducir el tiempo de procesamiento repetido.
- Estrategia de almacenamiento múltiple: admite el sistema de archivos local, Google Drive y otros métodos de almacenamiento.
- Herramientas CLI: Proporcionar herramientas de línea de comandos para facilitar a los usuarios el envío de tareas y el procesamiento de los resultados.
Utilizar la ayuda
Proceso de instalación
- Descarga e instala Ollama.
- Descargue e instale Docker.
- Clone el repositorio text-extract-api:
git clone https://github.com/CatchTheTornado/text-extract-api.git
- Vaya al directorio del proyecto e inicie el contenedor Docker:
cd text-extract-api
docker-compose up
Utilización
conversión de documentos
- Sube los documentos a convertir al directorio especificado.
- Utilice la herramienta CLI para enviar tareas de conversión:
python client/cli.py ocr_upload --file examples/example.pdf --prompt_file examples/example-to-json-prompt.txt
- El resultado de la conversión se guardará en formato JSON o Markdown en el directorio especificado.
Eliminación de IIP
- Cargar un documento que contenga IIP.
- Utilice la herramienta CLI para enviar tareas PII de eliminación:
python client/cli.py ocr_upload --file examples/example-pii.pdf --prompt_file examples/example-remove-pii.txt
- Se eliminarán todos los datos personales de los documentos procesados.
Flujo detallado de funcionamiento de las funciones
- OCR de alta precisiónOCR: Mediante la configuración de diferentes estrategias de OCR (por ejemplo, Marker, Llama3.2-vision, etc.), puede lograr una extracción de texto de alta precisión para varios documentos. Los usuarios pueden elegir la estrategia de OCR más adecuada según el tipo de documento.
- conversión de documentosSoporte para PDF, Word, PPTX y otros formatos del documento se convertirá a formato Markdown o JSON, para facilitar el posterior procesamiento y análisis de datos.
- Eliminación de IIP: Identifica y elimina automáticamente la información de identificación personal de los documentos para garantizar la privacidad y la seguridad de los datos.
- procesamiento distribuido: Procesamiento de tareas distribuidas mediante Celery para soportar tareas de procesamiento de documentos a gran escala y mejorar la eficiencia del procesamiento.
- mecanismo de almacenamiento en caché: Utiliza Redis para almacenar en caché los resultados de OCR con el fin de reducir el tiempo de procesamiento repetitivo y mejorar el tiempo de respuesta del sistema.
- Política de multialmacenamientoAdmite varios métodos de almacenamiento, como el sistema de archivos local, Google Drive, etc. Los usuarios pueden elegir la estrategia de almacenamiento adecuada según sus necesidades.
- Herramientas CLIHerramientas de línea de comandos : Se proporcionan herramientas de línea de comandos para que los usuarios puedan enviar tareas y procesar resultados con comandos sencillos para mayor comodidad.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...