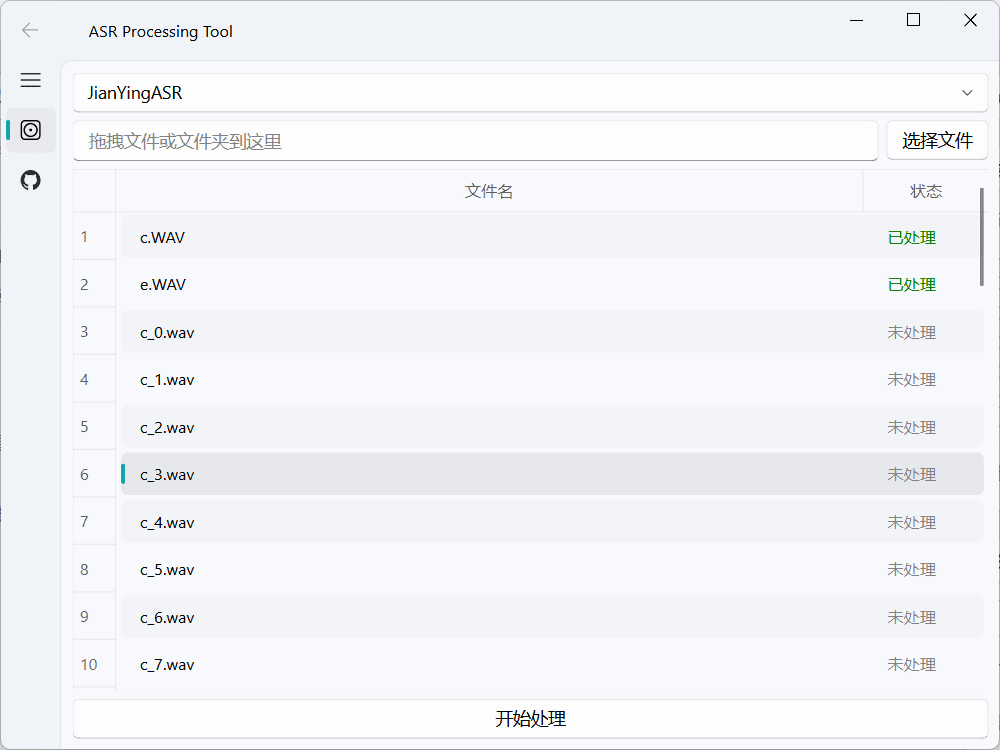

综合介绍
Easy-Voice-Toolkit 是一个基于开源语音项目的多功能工具箱,提供语音识别、语音转录、语音转换、数据集创建和模型训练等多种自动化音频工具。用户可以根据需要选择性地使用这些工具,或按顺序使用它们,将原始音频文件逐步转换为理想的语音模型。该工具箱支持本地部署,用户可以下载轻量级安装包或便携式包进行使用。

功能列表
- 音频处理

- 语音识别

- 语音转录

- 数据集制作(SRT 转换 & WAV 分割)

- 模型训练

- 语音合成

使用帮助
安装流程:
本地部署 - 用户安装:
- 下载轻量安装包或即用型便携包。
- 解压缩下载的文件。
- 运行
.exe文件或其快捷方式。
本地部署 - 开发者设置环境:
- 确保已安装 Python 3.8 或更高版本。
- 克隆项目仓库:
git clone https://github.com/Spr-Aachen/Easy-Voice-Toolkit.git - 切换到项目目录:
cd Easy-Voice-Toolkit - 安装依赖项:
pip install -r requirements.txt - 安装 GUI 依赖项:
pip install pyside6 QEasyWidgets pywin32==300 psutil pynvml darkdetect PyGithub - 运行程序:
python Run.py
功能操作流程:
- 音频处理:导入音频文件,选择所需的处理工具(如降噪、剪辑等),应用处理并保存结果。
- 语音识别:导入音频文件,选择语音识别模型,运行识别并导出文本结果。
- 语音转录:导入音频文件,选择转录工具,运行转录并导出字幕文件(如 SRT)。
- 数据集制作:导入音频文件,选择数据集制作工具,进行 SRT 转换或 WAV 分割,生成训练数据集。
- 模型训练:导入训练数据集,选择模型训练工具,配置训练参数,运行训练并保存模型。
- 语音转换:导入音频文件,选择语音转换工具,配置转换参数,运行转换并保存结果。
注意事项
- 目前 UI 界面仅支持 Windows 系统。
- 下载和使用过程中请确保网络连接稳定。
- 如果遇到问题,请参考项目仓库中的使用说明和常见问题解答。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...