
DiaMoE-TTS是什么
DiaMoE-TTS 是清华大学和巨人网络联合开源的多方言语音合成框架,基于国际音标(IPA),解决方言数据稀缺、正字法不一致和音系变化复杂等问题。通过统一的 IPA 前端标准化音素表示,消除跨方言差异,采用方言感知的 Mixture-of-Experts(MoE)架构,让不同专家网络专注于学习不同方言的特征,保留每种方言的独特音色和韵律。框架基于 F5-TTS 构建,引入低秩适配器(LoRA)和条件适配器,实现参数高效的方言迁移,仅需微调少量参数即可完成方言扩展。完全基于开源数据训练,无需昂贵的人工标注语音,降低了技术门槛。实验表明,DiaMoE-TTS 能生成自然且富有表现力的语音,在仅使用几小时数据的情况下,对未见方言和专业领域(如京剧)实现了零样本性能。DiaMoE-TTS 支持 11 种方言和普通话,可扩展到欧洲语言。
DiaMoE-TTS的功能特色
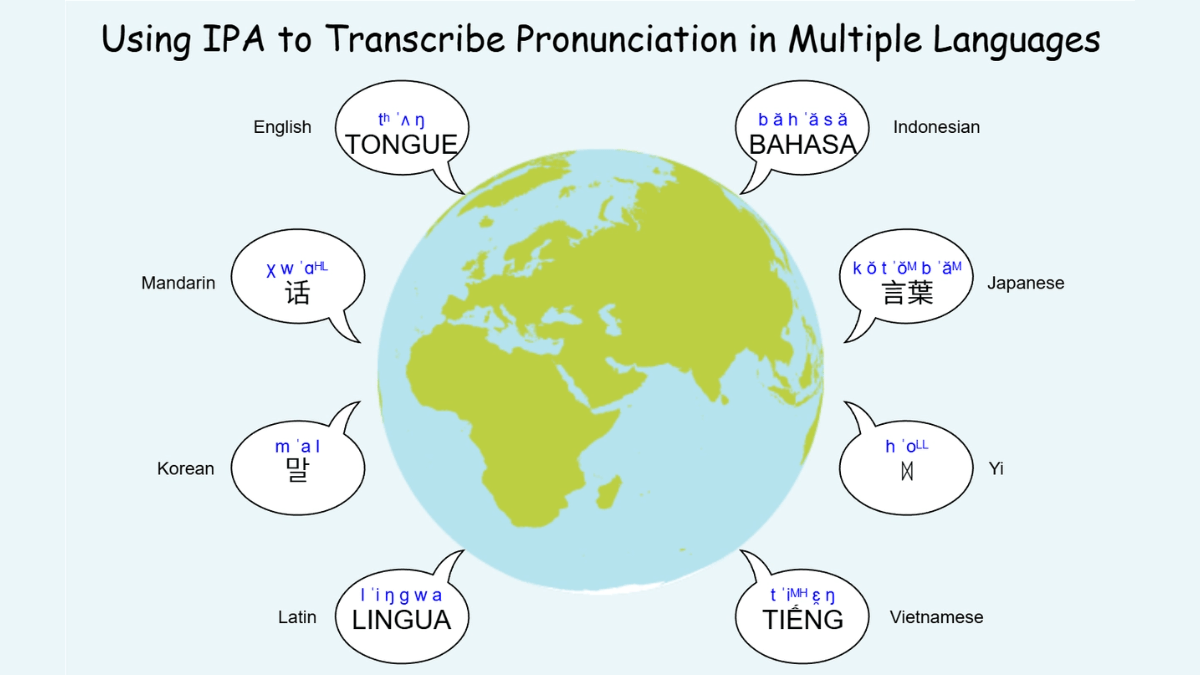
- 统一的 IPA 前端:采用国际音标(IPA)作为输入体系,构建高度可扩展的音素库存,支持多种方言及语言的音素标注,消除跨方言间的差异,保证建模的一致性与泛化能力。
- 方言感知 MoE 架构:引入方言感知的 Mixture-of-Experts 架构,不同专家网络专注于学习不同方言的特征,动态门控机制自动选择最合适的专家路由,保留每种方言的独特音色和韵律。
- 低资源方言适配:采用参数高效迁移策略,仅需微调少量参数即可完成方言扩展,主干与 MoE 模块保持冻结,避免对已有知识的遗忘,实现低资源方言的快速适配。
- 多阶段训练方法:包括 IPA 迁移初始化、多方言联合训练、方言专家强化和低资源快速适配等阶段,逐步提升模型性能并适应方言多样性。
- 开放数据驱动:完全基于开源 ASR 数据训练,无需昂贵的人工标注语音,降低了技术门槛,支持可扩展的、基于开放数据的语音合成。
- 高效泛化能力:在低资源方言上仍能实现高发音准确率,如客家话的发音准确率可达 91.7%,并可对未知方言和专业领域(如京剧)实现零样本性能测试。
- 丰富的应用场景:支持多种汉语方言以及普通话的语音合成,可扩展至欧洲语言,适用于方言保护、文化娱乐等领域,为方言的传承和文化产业发展提供技术支持。
- 完整的工具链:提供训练和推理脚本、预训练模型以及开源数据集的 IPA 前端,方便用户快速上手和应用,加速研究和开发进程。
DiaMoE-TTS的核心优势
- 数据驱动与开源:完全基于开源数据训练,无需昂贵的人工标注语音,降低了技术门槛和成本。
- 高效泛化能力:在低资源方言上仍能实现高发音准确率,对未见方言和专业领域(如京剧)可实现零样本性能测试。
- 方言保护与扩展:支持多种汉语方言及普通话,可扩展至欧洲语言,为方言保护和语言多样性提供有力支持。
- 快速适配与迁移:采用参数高效迁移策略,仅需微调少量参数即可完成方言扩展,快速适配新方言。
- 自然语音合成:生成的语音自然且富有表现力,实验结果表明其在语音质量和表达力上表现出色。
DiaMoE-TTS官网是什么
- GitHub仓库:https://github.com/GiantAILab/DiaMoE-TTS
- HuggingFace模型库:https://huggingface.co/RICHARD12369/DiaMoE_TTS
- arXiv技术论文:https://www.arxiv.org/pdf/2509.22727
DiaMoE-TTS的适用人群
- 方言研究者:为研究汉语方言及其他语言的语音特征、音系演变提供高效工具,助力语言学研究。
- 语音合成开发者:提供开源框架和预训练模型,方便开发者快速构建和优化多方言语音合成系统。
- 方言保护工作者:助力方言保护项目,通过语音合成技术记录和传承濒危方言,促进语言多样性。
- 文化娱乐从业者:在影视、广播、游戏等领域,可用于制作具有地方特色的语音内容,增强文化表现力。
- 教育工作者:可用于开发方言教学资源,帮助学生学习和了解不同方言,促进语言教育。
- 技术爱好者:对语音合成、人工智能技术感兴趣的个人,可通过开源代码和文档学习和探索。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...