
问题: 知识图谱很重要,DeepSeek 语言模型很火,它能用来快速构建知识图谱吗?我想试试 DeepSeek 的真本事,看它在提取信息、整合知识、凭空创建图谱方面怎么样。
方法: 我做了三个实验来测试 DeepSeek 的知识图谱构建能力:
- 单篇文章建图谱: 给 DeepSeek 一篇文章,看它能不能准确抓取信息,建成图谱。
- 多篇文章融合图谱: 给 DeepSeek 多篇文章,看它能不能把新知识加到已有的图谱里。
- 主题生成图谱: 只告诉 DeepSeek 图谱的主题,不给文章,看它能不能自己搞出一个图谱。
结果: 实验证明,DeepSeek 构建和融合知识图谱效果不错,但还有提升空间。
下面是实验的具体过程和结果,我用更简单的话说清楚。
一、单篇文章提取知识建图谱
目的: 测试 DeepSeek 从一篇文章里提取知识,构建知识图谱的能力。
过程: 我找了一篇关于 NebulaGraph 图数据库的文章,让 DeepSeek 读文章,提取关键信息,然后生成 NebulaGraph 数据库代码(nGQL)来创建知识图谱。
指令: “你能帮我生成知识图谱吗?我给你文章,你提取关键信息,用 nGQL 代码构建知识图谱。”
操作: 直接复制粘贴文章内容给 DeepSeek。
DeepSeek 生成的 nGQL 代码:
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
结果: DeepSeek 代码没啥问题,语法对,还把多条数据合成一条语句,效率高。代码放到 NebulaGraph 跑起来,图谱长这样:
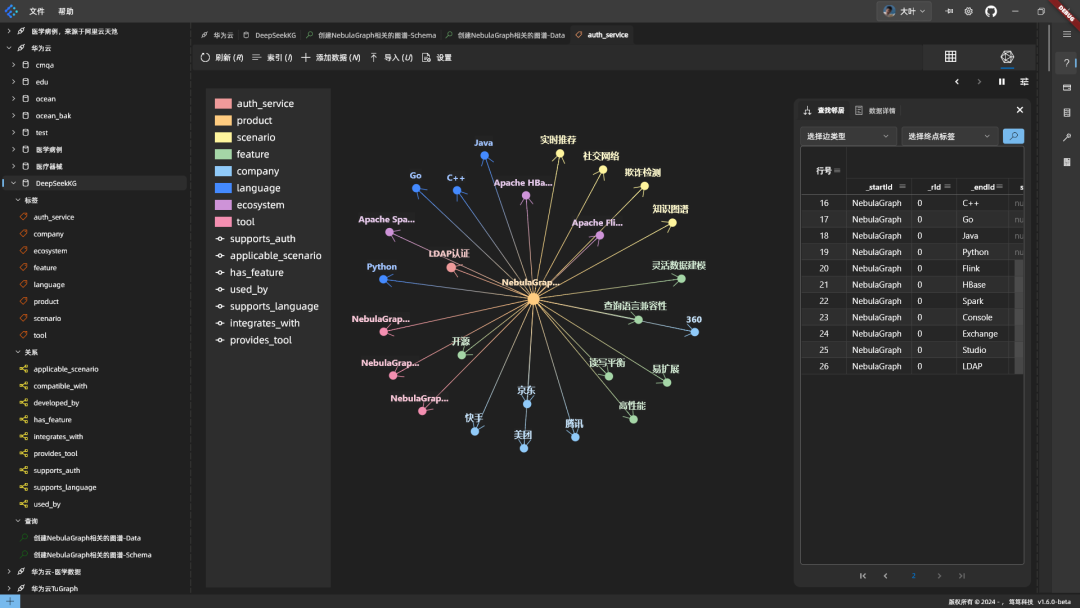
图谱以 NebulaGraph 为中心,展示了相关信息。
二、多篇文章融合知识
目的: 测试 DeepSeek 融合多篇文章知识,扩展已有图谱的能力。
过程: 先用一篇文章建了图谱,再给 DeepSeek 更多关于 NebulaGraph 的文章(来自百度百科),让它把新知识合并到现有图谱里。
指令: “接下来,给你另一篇文章。尽量用现在的表结构融合图谱。要改表结构就用 ALTER 命令。”
操作: 分别把 NebulaGraph 和 360 百科词条的摘要给了 DeepSeek。
DeepSeek 生成的 nGQL 代码 (NebulaGraph 词条):
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
DeepSeek 生成的 nGQL 代码 (360 词条):
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
结果: DeepSeek 能根据新文章,修改表结构(比如给 product 和 company 表加字段),也新增了关系类型。它按要求用 ALTER 命令改表结构。 小问题是注释用了 --,nGQL 不认,手动改成 # 就行了。
代码放到数据库执行,融合后的图谱效果:
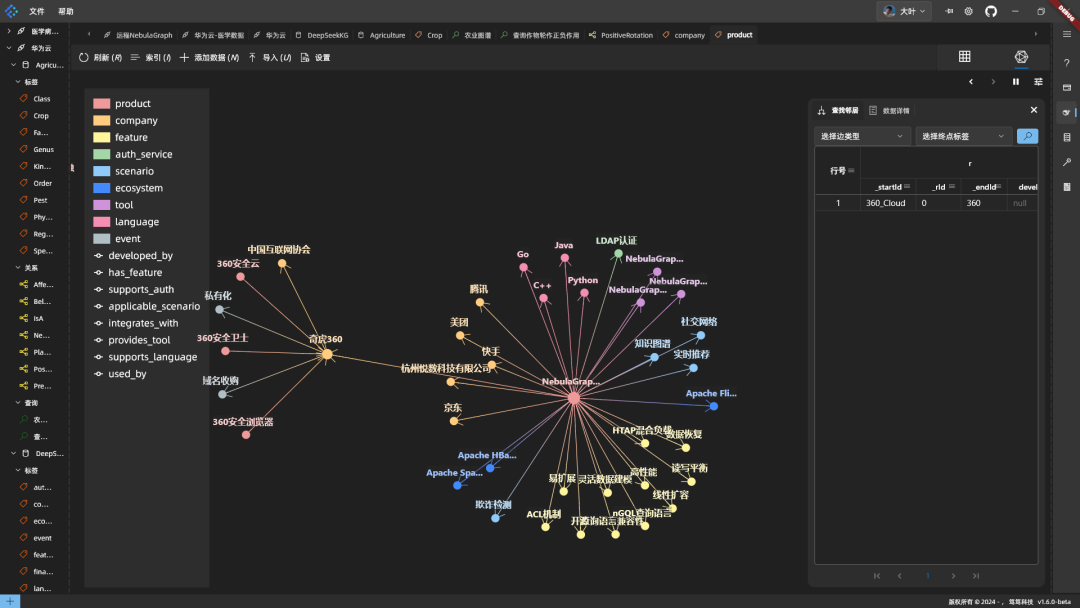
小结: DeepSeek 建图谱和融合知识不错。但服务器有时慢,NebulaGraph 改 schema 是异步的,要等一会儿生效。
三、主题生成:无中生有农业图谱
目的: 测试 DeepSeek 在没文章的情况下,根据主题生成知识图谱的能力。
过程: 新建对话,让 DeepSeek 按“农业”主题,直接生成图谱代码。没给文章,完全是“空手套白狼”。
指令: “我要建一个农业知识图谱。用 NebulaGraph 数据库,生成 nGQL 脚本。表名大驼峰,属性名小驼峰。Schema 名用 `` 包起来,避免冲突。至少生成 3000 个节点。”
DeepSeek 生成的 nGQL 代码 (部分):
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
问题和改进:
- 节点数限制: 开始要 3000 节点,DeepSeek 拒绝了,给了 Python 导入 CSV 代码。我不想用 Python,就减少了节点数。
- 注释问题又来: 代码注释又是 --,再次指出问题。
改进指令: “注释用 #,不用 Python 代码,3000 节点太多了。给我 50 个节点的 ngql 脚本就行。”
后续对话和指令: 为了完善图谱,我继续跟 DeepSeek 聊,让它补充数据,加强关联,按分类(界门纲目科属种)组织图谱,还让它生成作物轮种数据。
例如,我的指令:
- “补充数据,让数据关联更强”
- “把【界门纲目科属种】这些分类做成图谱”
- “找出现有作物的轮种禁忌和增益作物”
- “结合图谱作物组织数据,按之前的格式给 nGQL 脚本”
实验插曲: DeepSeek 有次 INSERT 语句用了 Cypher 语法,nGQL 不支持,指出来后它改过来了。
指令: “这个插入语句不是 nGQL 语法,改一下,DDL 放前面,DML 放后面”
最终数据量: 几轮对话后,数据量如图:

图谱效果: 随便展开几个节点看看:
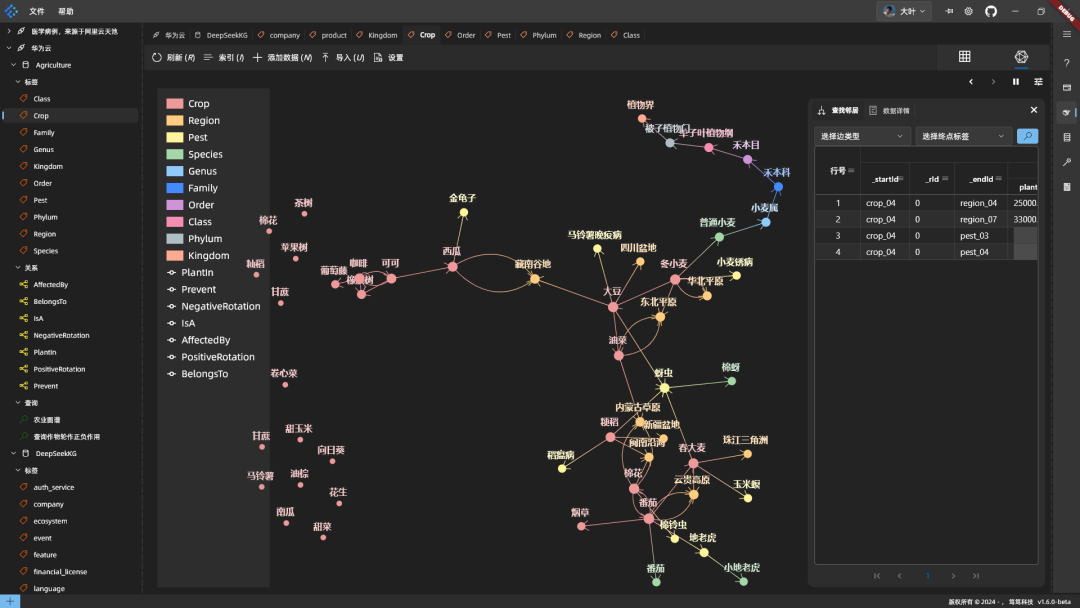
轮种增产组合例子: 临期种植的增产组合效果:
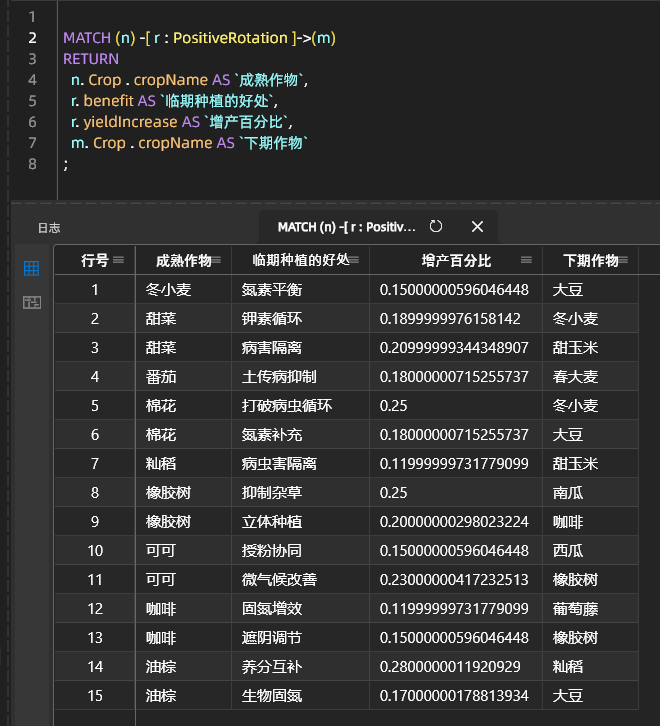
四、总结
结论: DeepSeek 在知识图谱构建和融合上表现出色,实验证明了它的能力:
- 提取信息快又准: DeepSeek 能快速从文本提取关键信息,生成符合要求的 nGQL 脚本,语言理解能力强,能识别实体、关系和事件。
- 融合知识能力强: DeepSeek 融合多篇文章知识效果好,能根据新文章扩展和更新图谱,保证图谱完整性和准确性。
- 无中生有也能建图谱: 没文章也能按主题生成图谱。虽然生成过程有些语法小问题,但调整后能生成合格的脚本。
- 细节需要优化: DeepSeek 生成的脚本偶尔有语法问题,比如注释不对。生成大量节点时,服务器可能反应慢。实际用的时候需要注意这些问题。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...