
DeepOCR是什么
DeepOCR 是开源复刻项目,实现 DeepSeek-OCR 的核心架构,通过光学压缩技术高效处理文本信息。核心是 DeepEncoder,由 SAM-base(处理高分辨率图像)、16×卷积压缩器(减少 token 数量)和 CLIP-large(处理压缩后的特征)组成。这种设计在保持高分辨率处理能力的同时,显著降低了激活内存和 token 数量。DeepOCR 采用两阶段训练流程:第一阶段使用 LLaVA-CC3M 数据集进行视觉 - 语言对齐训练;第二阶段使用 olmOCR 数据集进行 OCR 特定预训练。通过这种训练方法,DeepOCR 在 OmniDocBench 和 olmOCR 基准测试中表现出色,尤其在英文文本识别和表格解析任务中,验证了光学压缩的有效性。
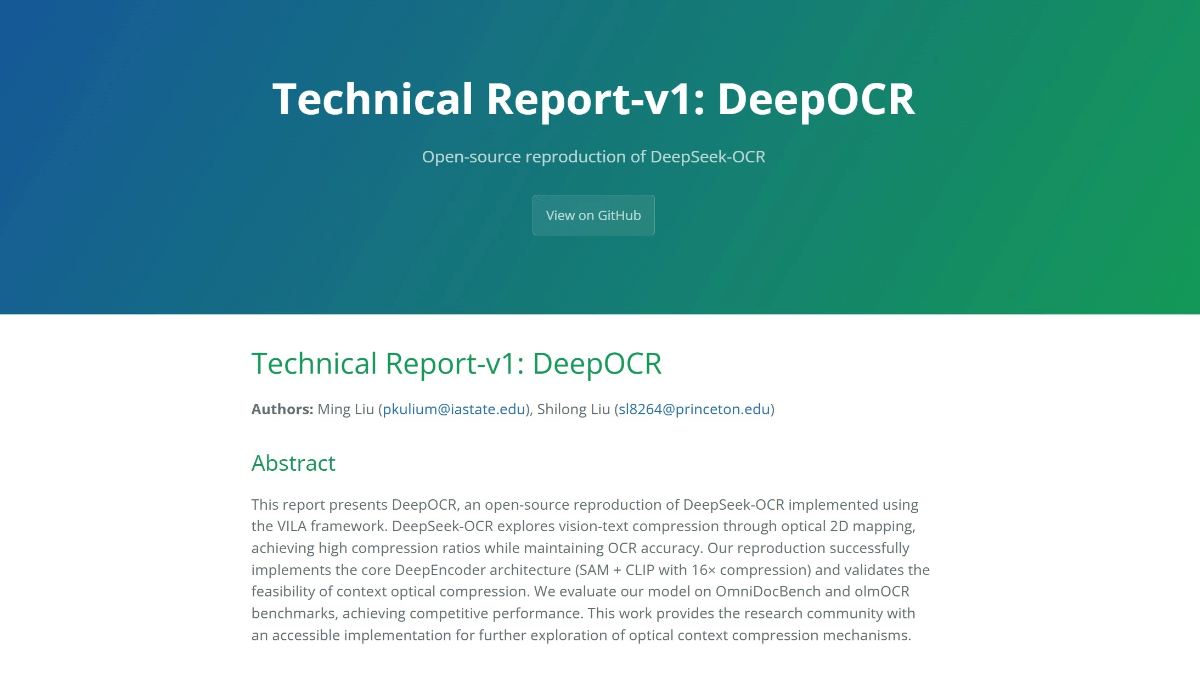
DeepOCR的功能特色
- 光学压缩:通过将文本渲染为图像并利用视觉编码器(如 SAM 和 CLIP)进行处理,实现文本信息的高效压缩,压缩率可达 7-20 倍。
- 高分辨率处理:支持 1024×1024 及更高分辨率的图像输入,通过窗口注意力机制和卷积压缩技术,有效管理激活内存。
- 多模态融合:将 SAM 的局部特征和 CLIP 的全局语义特征进行拼接,生成 2048 维的融合特征,为下游任务提供丰富的信息。
- 两阶段训练:第一阶段进行视觉 - 语言对齐训练,第二阶段针对 OCR 任务进行预训练,确保模型在文本识别和文档解析任务中表现优异。
- 低算力友好:通过冻结 DeepEncoder(SAM + CLIP),大幅降低显存需求,使得模型可以在有限的 GPU 资源(如 2×H200)上完成训练。
- 开源实现:基于 VILA 框架完全开源,为研究社区提供了探索光学上下文压缩机制的可访问平台。
- 基准测试:在 OmniDocBench 和 olmOCR 基准测试中验证了模型的性能,尤其在英文文本识别和表格解析任务中表现出色。
DeepOCR的核心优势
- 高效压缩:通过光学压缩技术,将文本渲染为图像并利用视觉编码器进行处理,显著减少了文本 token 数量,压缩率可达 7-20 倍。这使得模型在处理长文本时更加高效,降低了计算资源需求。
- 高分辨率处理能力:支持高分辨率输入(如 1024×1024),通过窗口注意力机制(SAM)和卷积压缩技术,有效管理激活内存,避免内存爆炸。这使得 DeepOCR 能够处理复杂的文档布局和高分辨率图像。
- 多模态融合:将 SAM 的局部特征与 CLIP 的全局语义特征进行融合,生成 2048 维的丰富特征。这种多模态融合为下游任务提供了更全面的信息,提升了模型的性能。
- 低算力友好:在训练过程中,DeepEncoder(SAM + CLIP)被冻结,大幅降低了显存需求。这使得模型可以在有限的 GPU 资源(如 2×H200)上完成训练,降低了硬件门槛,适合中小团队使用。
DeepOCR官网是什么
- 项目官网:https://pkulium.github.io/DeepOCR_website/
- Github仓库:https://github.com/pkulium/DeepOCR
DeepOCR的适用人群
- 文档处理和OCR领域的开发者:需要高效处理长文本和复杂文档布局,DeepOCR 的光学压缩和高分辨率处理能力可以显著提升文档解析效率。
- 中小团队和独立开发者:DeepOCR 的低算力友好特性使其适合在有限的硬件资源上运行,降低了开发门槛。
- 开源社区贡献者:开源社区的成员可以参与代码贡献、改进和扩展,推动技术发展。
- 对创新技术感兴趣的学术研究者:希望探索光学压缩在不同领域的应用,如图像理解、UI 元素检测等。
- 需要高效文本处理的企业和机构:可以利用 DeepOCR 的高效压缩和处理能力,优化内部文档处理流程,提升工作效率。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...