
最近,许多从事大模型训练和推理的朋友都在讨论模型参数量和模型大小之间的关系。例如,著名的羊驼系列 LLaMA 大模型,就包含了 LLaMA-7B、LLaMA-13B、LLaMA-33B 和 LLaMA-65B 四种不同参数规模的版本。
这里的 “B” 是 “Billion” 的缩写,代表十亿。因此,最小的 LLaMA-7B 模型包含约 70 亿个参数,而最大的 LLaMA-65B 模型则包含约 650 亿个参数。
那么,这些参数量是如何计算出来的呢?此外,一个 100GB 的模型文件,对应的大模型参数量大概是什么级别?十亿、百亿、千亿还是万亿?本文将深入浅出地解答这些问题。
一、大模型参数量计算方法
我们将以大模型的基础架构——Transformer 为例,详细解析参数量的计算过程。
一个标准的 Transformer 模型由 L 个相同的层堆叠而成,每个层包含两个主要部分:自注意力层 (Self-Attention) 和 前馈神经网络层 (MLP)。
1. 自注意力层 (Self-Attention)
自注意力机制是 Transformer 的核心。无论是单头自注意力 (Self-Attention) 还是多头自注意力 (Multi-Head Self-Attention, MHA),其核心的参数量计算方式是相同的。
在自注意力层中,输入序列首先会被映射成三个向量:查询向量 (Query, Q)、键向量 (Key, K) 和 值向量 (Value, V)。在 MHA 中,这三个向量会被进一步分割到多个头中,每个头负责关注输入序列的不同部分。

- 单头自注意力: Q, K, V 分别通过一个形状为 [h, h] 的权重矩阵进行线性变换,其中 h 是隐藏层维度。因此,Q, K, V 的总参数量为 3h²。此外,还有一个用于输出的线性变换层,权重矩阵形状同样为 [h, h]。因此,单头自注意力的总参数量为 4h² (忽略偏置项)。
- 多头自注意力 (MHA): 假设有 n_head 个头,每个头的维度是 h_head = h / n_head。每个头都有独立的 Q, K, V 权重矩阵,形状都是 [h, h_head]。因此,每个头的 Q, K, V 权重矩阵参数量是 3 * h * h_head = 3h²/n_head。n_head 个头的参数量总共是 n_head * (3h²/n_head) = 3h²。最后,输出层的线性变换权重矩阵形状是 [h, h]。所以 MHA 的总参数量也是 4h² (忽略偏置项)。
因此,无论单头还是多头,自注意力层的参数量都可以近似为 4h²。
2. 前馈神经网络层 (MLP)
MLP 层由两个线性层组成。第一个线性层将隐藏层维度 h 扩展到 4h,第二个线性层再将维度从 4h 缩减回 h。

- 第一个线性层的权重矩阵形状为 [h, 4h],参数量为 4h²。
- 第二个线性层的权重矩阵形状为 [4h, h],参数量同样为 4h²。
因此,MLP 层的总参数量为 8h² (忽略偏置项)。
3. 层归一化 (Layer Normalization)
在每个 Self-Attention 层和 MLP 层之后,以及 Transformer 最后一层输出后,通常都会有一个层归一化 (Layer Normalization) 操作。每个 Layer Normalization 层包含两个可训练参数:
- 缩放参数 (gamma): 形状为 [h]。
- 平移参数 (beta): 形状为 [h]。
由于每个 Transformer 层有两个 Layer Normalization (分别在 Self-Attention 和 MLP 之后),再加上输出层后的一个, 所以 L 层 Transformer 的 Layer Normalization 总参数量为 (2L + 1) * 2h。
4. 词嵌入层 (Embedding)
输入文本首先需要通过词嵌入层转换为词向量。假设词表大小为 V,词向量维度为 h,那么词嵌入层的参数量为 Vh。
5. 输出层
输出层的权重矩阵通常与词嵌入层共享权重 (Weight Tying),以减少参数量并可能提升性能。因此,如果采用权重共享,输出层通常不引入额外的参数量。如果不共享,则参数量为 Vh。
6. 位置编码 (Positional Encoding)
位置编码用于为模型提供输入序列中单词的位置信息。
- 可训练的位置编码: 如果使用可训练的位置编码,参数量为 N * h,其中 N 是最大序列长度。例如,ChatGPT 的最大序列长度为 4k。
- 相对位置编码 (如 RoPE 或 ALiBi): 这些方法不引入可训练的参数。
由于位置编码的参数量相对较少,通常在计算总参数量时可以忽略不计。
7. 总参数量计算
综上所述,一个 L 层的 Transformer 模型的总参数量为:
总参数量 = L * (Self-Attention 参数 + MLP 参数 + LayerNorm 参数 * 2) + Embedding 参数 + 输出层参数 + LayerNorm 参数(输出层后)
总参数量 ≈ L * (4h² + 8h² + 4h) + Vh + (可选的 Vh) + 2h
总参数量 ≈ L * (12h² + 4h) + Vh + 2h (假设输出层与词嵌入层共享权重)
当隐藏维度 h 较大时,一次项 4h 和 2h 可以忽略不计,模型参数量可以进一步近似为:
总参数量 ≈ 12Lh² + Vh
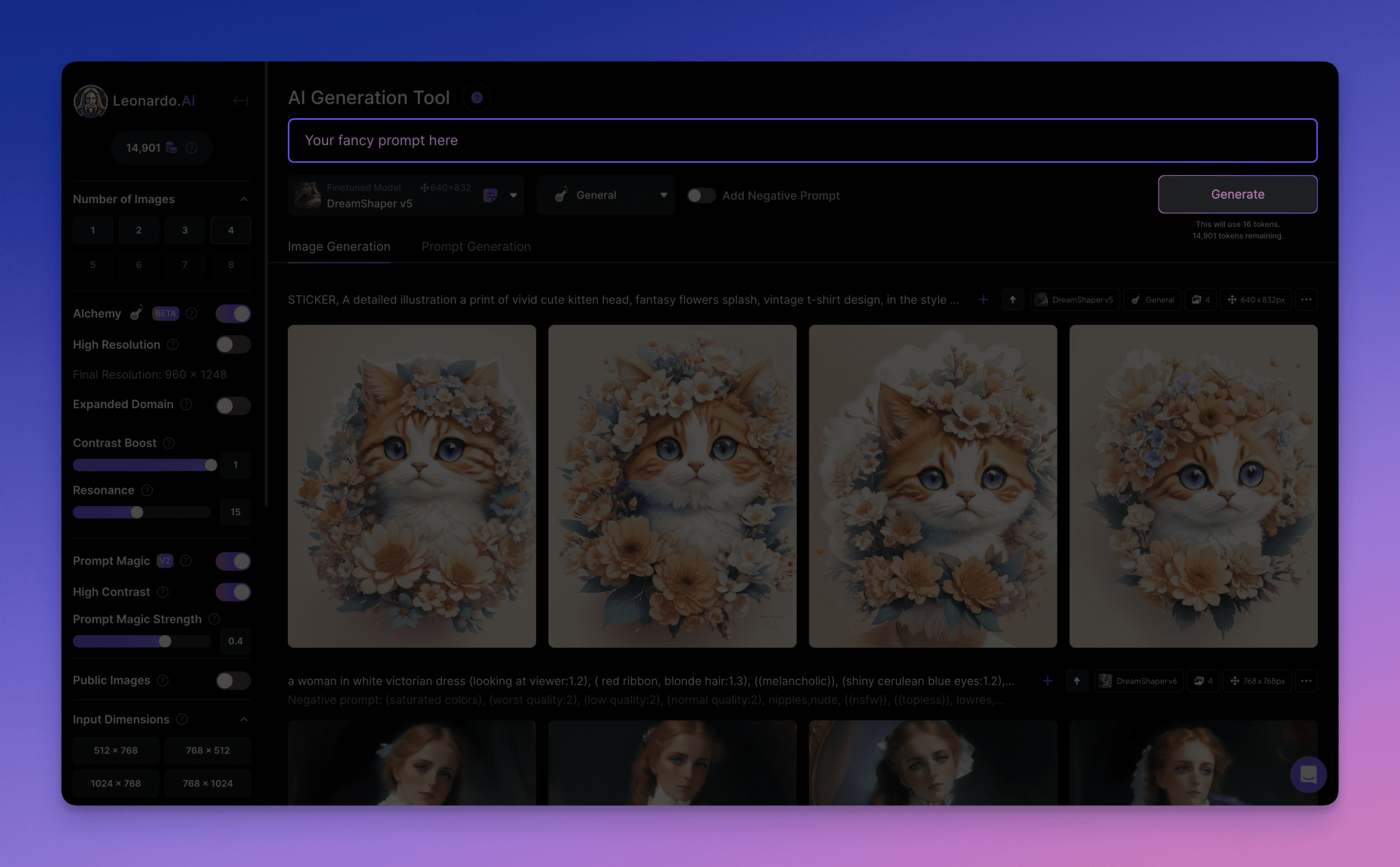
8. LLaMA 参数量估算
下表展示了 LLaMA 不同版本的一些关键参数以及其参数量的估算:
**我们可以根据上述公式进行验证。以 LLaMA-7B 为例,根据表格,L=32, h=4096, V=32000。**
估算参数量 ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6.55B
这个估算值与 6.7B 较为接近。其他的几个版本也可以通过这种方法进行估算和验证。
二、大模型参数量与模型大小的转换
了解了参数量的计算方法,接下来我们看看参数量和模型大小是如何转换的。
我们仍以 LLaMA-7B 为例,其参数量约为 70 亿。
- 理论计算: 如果每个参数都以 FP32 (32 位浮点数,占用 4 个字节) 格式存储,那么 LLaMA-7B 的理论大小为:7B * 4 bytes = 28GB。
- 实际存储: 为了节省存储空间和提高计算效率,模型权重通常以较低精度的格式存储,如 FP16 (16 位浮点数,占用 2 个字节) 或 BF16。使用 FP16 存储时,LLaMA-7B 的大小理论上为:7B * 2 bytes = 14GB。
- 其他因素: 除了权重参数外,模型文件还可能包含优化器状态 (如 Adam 优化器的动量和方差)、词表、模型配置等信息,这些都会占用额外的存储空间。此外,一些参数 (如 Layer Normalization 的 gamma 和 beta) 可能会以 FP32 格式存储。
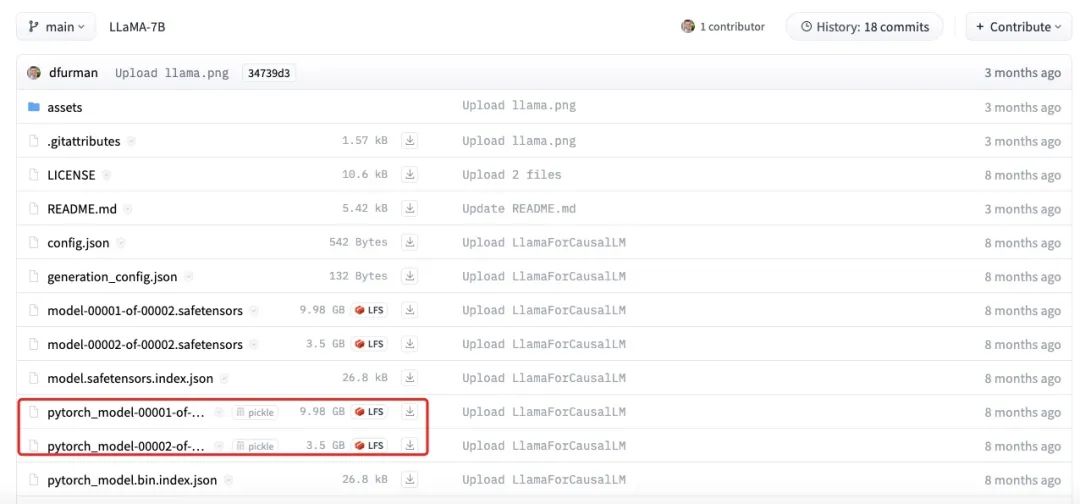
上图展示了 LLaMA-7B 模型文件的实际大小。可以看到,各个部分的大小总和约为 13.5GB,与我们估算的 14GB 较为接近。其中的微小差异可能是由舍入误差、偏置参数或者部分参数仍然使用 FP32 存储等原因造成的。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...