
综合介绍
Crawl4AI 是一个开源的异步网页爬虫工具,专为大型语言模型(LLMs)和人工智能(AI)应用设计。它简化了网络爬虫和数据提取流程,支持高效的网页爬取,并提供对 LLM 友好的输出格式,如 JSON、清理过的 HTML 和 Markdown。Crawl4AI 支持同时爬取多个 URL,完全免费且开源,适合各种数据抓取需求。
功能列表
- 异步架构:高效处理多个网页,快速抓取数据
- 多种输出格式:支持 JSON、HTML、Markdown
- 多 URL 爬取:同时爬取多个网页
- 媒体标签提取:提取图片、音频和视频标签
- 链接提取:提取所有外部和内部链接
- 元数据提取:从页面中提取元数据
- 自定义钩子:支持身份验证、请求头和页面修改
- 用户代理定制:自定义用户代理
- 页面截图:抓取页面截图
- 执行自定义 JavaScript:在爬取前执行多个自定义 JavaScript
- 代理支持:增强隐私和访问
- 会话管理:处理复杂的多页面爬取场景
使用帮助
安装流程
Crawl4AI 提供灵活的安装选项,适用于各种使用场景。您可以将其作为 Python 包安装或使用 Docker。
使用 pip 安装
- 基本安装
pip install crawl4ai这将默认安装 Crawl4AI 的异步版本,使用 Playwright 进行网页爬取。
- 手动安装 Playwright(如果需要)
playwright install或者
python -m playwright install chromium
使用 Docker 安装
- 拉取 Docker 镜像
docker pull unclecode/crawl4ai - 运行 Docker 容器
docker run -it unclecode/crawl4ai
使用指南
- 基本使用
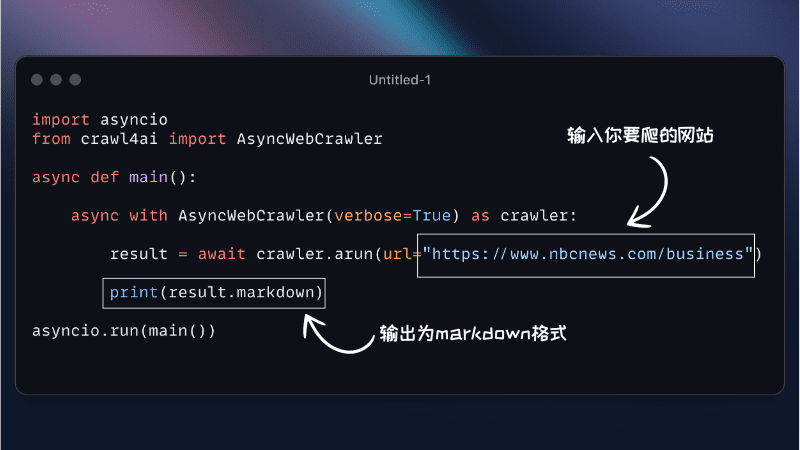
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - 自定义设置
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - 提取特定数据
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - 会话管理
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
Crawl4AI 提供了丰富的功能和灵活的配置选项,适用于各种网页爬取和数据抓取需求。通过详细的安装和使用指南,用户可以轻松上手并充分利用该工具的强大功能。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...