
Audio2Face是什么
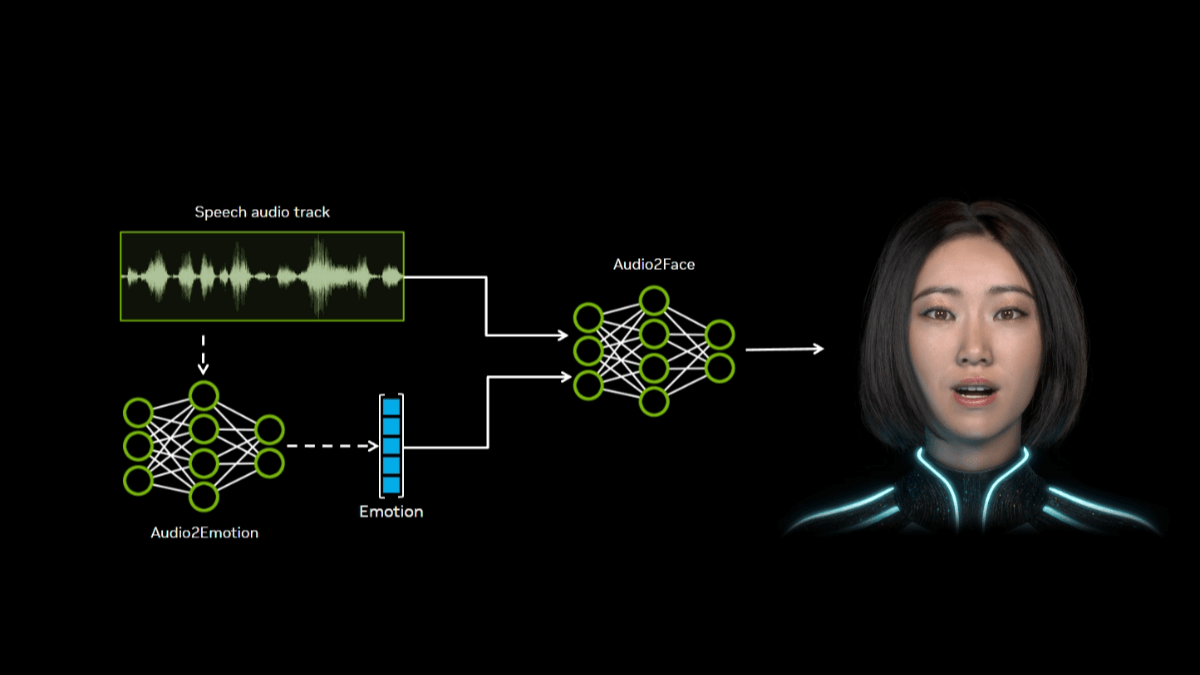
Audio2Face是NVIDIA开源的能将音频输入转化为逼真的3D面部动画AI工具。通过分析音频中的语音特征,如音素和语调,生成精确的唇部同步和细腻的情感表达,为虚拟角色赋予生动的人类表情。开发者可以免费获取Audio2Face的模型和SDK,将其集成到游戏、3D应用或其他项目中,快速创建高保真角色动画。NVIDIA还开源了Audio2Face训练框架,让开发者能使用自己的数据对模型进行微调和定制,以满足特定需求。例如,开发者可以训练出符合特定角色表演风格、语言或情感表达的模型。Audio2Face提供了针对Autodesk Maya和Unreal Engine 5的插件,方便用户在这些主流3D软件中直接使用该技术。
Audio2Face的功能特色
- 音频驱动动画:通过分析音频输入,自动生成逼真的3D面部动画,包括唇部同步和表情变化。
- 实时性能:支持实时音频流输入,能即时生成面部动画,适用于交互式应用和实时渲染场景。
- 多语言支持:兼容多种语言的音频输入,可生成对应语言的面部表情和口型动画,满足不同语言环境下的使用需求。
- 情感表达:能根据音频中的语调和情感特征,推断并生成相应的情感表情,使角色表现更加生动自然。
- 模型定制:提供训练框架,允许用户使用自己的数据对模型进行微调和定制,以适应特定角色或场景的需求。
- 广泛集成:支持多种3D软件和平台,如Autodesk Maya和Unreal Engine 5,方便开发者在不同环境中使用该技术。
Audio2Face的核心优势
- 高效制作流程:能快速生成高质量的面部动画,大大节省了传统动画制作中人工逐帧调整的时间和精力。
- 自然逼真的效果:生成的面部动画自然流畅,唇部同步精准,情感表达细腻,使虚拟角色更具真实感和感染力。
- 易于集成和使用:提供了丰富的SDK和插件,方便开发者将其集成到各种3D软件和游戏引擎中,无需复杂的设置和开发。
- 强大的自定义能力:通过训练框架,用户可以根据自己的需求对模型进行定制,满足不同角色、风格和语言的动画需求。
- 实时交互支持:支持实时音频输入和动画生成,适用于需要即时反馈的交互式应用,如虚拟现实、实时游戏等。
- 降低制作成本:开源的模型和工具降低了使用门槛,减少了对专业动画师的依赖,从而降低了制作成本。
- 多平台支持:兼容多种操作系统和硬件平台,具有良好的跨平台性能,提高了技术的通用性和适用性。
Audio2Face官网是什么
- 项目官网:https://developer.nvidia.com/blog/nvidia-open-sources-audio2face-animation-model/
- GitHub仓库:https://github.com/NVIDIA/Audio2Face-3D
Audio2Face的适用人群
- 游戏开发者:可用于快速生成游戏中的角色面部动画,提升角色表现力和游戏沉浸感。
- 影视动画师:帮助制作预渲染内容或实时动画,提高工作效率,实现更自然的表情和口型同步。
- 虚拟现实(VR)和增强现实(AR)开发者:为虚拟角色赋予生动表情,增强用户体验的真实感和互动性。
- 3D艺术家和设计师:在创作过程中快速生成面部动画原型,探索不同的表情和情感效果。
- 技术总监和动画技术负责人:评估和整合新技术到现有制作流程中,提升团队的动画制作能力。
- 教育工作者和学生:作为教学工具,帮助学生学习3D动画和AI技术,激发创意和实践能力。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章




暂无评论...