

像LangChain、CrewAI和AutoGen这样的框架通过提供构建人工智能系统的高级抽象而广受欢迎。然而,包括我在内的许多开发人员都发现,这些工具弊大于利,常常给开发过程带来不必要的复杂性和挫折感。
进入Atomic Agents--一个模块化的精简框架,旨在消除与现有人工智能开发工具相关的麻烦。Atomic Agents 基于可靠的编程范式,如 Input–Process–Output(IPO)模型和原子性概念,提供了一种以简单性、灵活性和开发者控制为优先考虑的全新方法。
在本文中,我们将深入探讨 Atomic Agents 的创建原因、它所采用的编程范式以及它如何在众多产品中脱颖而出。结合代码示例和实际示例,一起深入了解 Atomic Agents。如果你也一度觉得 LangChain 太复杂了,下面我们一起看一看吧~
现有人工智能框架的问题
当我第一次开始尝试使用LangChain时,我对它简化人工智能代理开发非常感兴趣。然而,实际上并非如此简单。
除了各种错中复杂的类和方法,LangChain的开发者似乎并不了解人工智能开发所面临的实际挑战,或许他们更看重的是理论上的优雅而非现实世界中的可用性。过度的抽象不仅增加了开发难度,还让开发变得不透明。
CrewAI 和 AutoGen 中的魔法幻觉
同样,CrewAI和AutoGen等框架也试图通过自动化复杂任务来提供 “神奇 ”的解决方案。部署成群的人工智能代理来自主处理一切事务的想法很诱人,但在实践中,这些工具往往一半的时间都无法正常工作。它们的承诺过高,而实际效果却不尽如人意,让开发人员疲于应对不可预测的行为和缺乏控制的问题。
这些框架模糊了底层流程,使得调试或定制功能变得困难。结果就是,这些工具更像是一个黑盒子,而不是一个有用的框架--在开发需要可靠和可维护性的应用程序时,这种情况并不理想。
过度承诺功能:常见问题
这些框架经常出现的一个问题是倾向于过度承诺功能。一些公司和工具声称可以提供接近AGI(人工通用智能)的解决方案,但如果你有长时间从事人工智能领域相关工作,你就会发现,我们还没有达到那个水平。炒作往往会导致不切实际的期望,而当这些工具不可避免地出现不足时,开发人员就不得不面对后果。
需要更好的方法
在与这些挫折搏斗之后,我们清楚地认识到,我们需要一个这样的框架:消除不必要的复杂性和抽象层:
- 消除不必要的复杂性和抽象层。
- 为开发人员提供全面控制,而不会将关键功能隐藏在不透明的接口之后。
- 遵循可靠、久经考验的编程范式,提高可维护性和可扩展性。
- 由开发人员构建,面向开发人员,了解人工智能开发中面临的实际挑战。
这种认识促成了Atomic Agents的诞生。
Atomic Agents介绍

Atomic Agents Logo
Atomic Agents是一个开源框架,旨在尽可能做到轻量级、模块化和可组合。它遵循输入-处理-输出(IPO)模型和原子性的原则,确保每个组件都是单一用途、可重用和可互换的。
Atomic Agents为何存在?
Atomic Agents 的诞生是为了弥补现有框架的不足。它的目标是
- 通过提供清晰、可管理的组件,简化人工智能开发。
- 消除困扰其他框架的多余复杂性和不必要的抽象。
- 促进灵活性和一致性,让开发人员专注于构建有效的人工智能应用,而不是与框架本身纠缠不清。
- 鼓励最佳实践,鼓励开发人员采用模块化、可维护的代码结构。
通过坚持这些原则,Atomic Agents 让开发人员能够构建既强大又易于管理的人工智能代理和应用程序。
Atomic Agents背后的编程范式
Input–Process–Output(IPO)模型
Atomic Agents的核心是Input–Process–Output(IPO)模型,这是一种基本的编程范式,它将程序结构分为三个不同的阶段:
- Input:从用户或其他系统接收数据。
- Process:对数据进行处理或转换。
- Output:处理后的数据作为结果呈现。
这种模型清晰简洁,更容易理解和管理应用程序中的数据流。
在Atomic Agents中,这可以转化为
- Input Schemas(输入模式):使用 Pydantic 定义输入数据的结构和验证规则。
- Processing Components(处理组件):对数据执行操作的代理和工具。
- Output Schemas(输出方案):确保结果在返回前经过结构化和验证。
原子性:功能构件
原子性的概念是将复杂的系统分解成最小的功能部分或 “原子”。每个原子
- 具有单一责任,使其更易于理解和维护。
- 可重复使用,允许在应用程序的不同部分甚至不同项目中使用组件。
- 可与其他原子组件组合,构建更复杂的功能。
通过专注于原子组件,Atomic Agents 促进了模块化架构,提高了灵活性和可扩展性。
Atomic Agents如何工作
组成部分
在Atomic Agents中,人工智能代理由几个关键部分组成:
- 系统提示:定义代理的行为和目的。
- 输入模式:指定输入数据的预期结构。
- 输出模式:定义输出数据的结构。
- 内存:存储对话历史或状态信息。
- 上下文提供程序:在运行时向系统提示注入动态上下文。
- 工具:代理可使用的外部功能或应用程序接口。
每个组件的设计都是模块化和可互换的,并遵循关注点分离和单一责任的原则。
模块化和可组合性
模块化是Atomic Agents的核心。通过将组件设计成自成一体并专注于单一任务,开发人员可以
- 更换工具或代理,而不会影响系统的其他部分。
- 微调单个组件,如系统提示或模式,而不会产生意想不到的副作用。
- 通过调整输入和输出模式,将代理和工具无缝地串联起来。
这种模块化方法不仅使开发更易于管理,还增强了人工智能应用程序的可维护性和可扩展性。
提供上下文:增强灵活性
上下文提供程序允许代理在系统提示中包含动态数据,并根据最新信息加强响应。
示例:
from atomic_agents.lib.components.system_prompt_generator import SystemPromptContextProviderBase
class SearchResultsProvider(SystemPromptContextProviderBase):
def __init__(self, title: str, search_results: List[str]):
super().__init__(title=title)
self.search_results = search_results
def get_info(self) -> str:
return "n".join(self.search_results)
# 向代理注册上下文提供程序
agent.register_context_provider("search_results", search_results_provider)
通过将实时数据注入代理的上下文,您可以创建更动态、反应更灵敏的人工智能应用。
模式和代理的链式连接
Atomic Agents 通过调整输入和输出模式,简化了代理和工具的链式连接过程。
示例: 假设你有一个查询生成代理和一个网络搜索工具。通过设置查询代理的输出模式,使其与搜索工具的输入模式相匹配,就可以直接将它们串联起来。
from web_search_agent.tools.searxng_search import SearxNGSearchTool # Initialize the query agent query_agent = BaseAgent( BaseAgentConfig( # ... other configurations ... output_schema=SearxNGSearchTool.input_schema, # Align output schema ) )
这种设计提高了可重用性和灵活性,可以轻松更换组件或扩展功能。
Atomic Agents优于其他产品的原因
消除不必要的复杂性
与引入多层抽象的框架不同,Atomic Agents 保持了简单明了。每个组件都有明确的目的,没有隐藏的魔法需要破解。
- 透明架构:您可以完全了解数据是如何在应用程序中流动的。
- 调试更容易:由于复杂性降低,识别和修复问题变得更加容易。
- 降低学习曲线:开发人员无需了解复杂的抽象概念,即可快速上手。
由开发人员打造,为开发人员服务
Atomic Agents 的设计考虑到了现实世界中的开发挑战。它采用久经考验的编程范式,并优先考虑开发人员的经验。
- 坚实的编程基础:通过遵循 IPO 模型和原子性,该框架鼓励最佳实践。
- 灵活性和控制:开发人员可根据需要自由定制和扩展组件。
- 社区驱动:作为一个开源项目,它邀请开发者社区提供贡献和协作。
独立和可重复使用的组件
Atomic Agents 的每个部分都可以独立运行,从而促进了可重用性和模块化。
- 可隔离测试:组件可单独测试,确保集成前的可靠性。
- 可跨项目重用:原子组件可用于不同的应用程序,节省开发时间。
- 更易于维护:隔离功能可减少变更的影响,简化更新。
构建一个简单的人工智能代理
我们将构建一个人工智能代理,它能响应用户询问并提出后续问题。
第 1 步:定义自定义输入和输出模式
from pydantic import BaseModel, Field from typing import List from atomic_agents.agents.base_agent import BaseIOSchema class CustomInputSchema(BaseIOSchema): chat_message: str = Field(..., description="The user's input message.") class CustomOutputSchema(BaseIOSchema): chat_message: str = Field(..., description="The agent's response message.") suggested_questions: List[str] = Field(..., description="Suggested follow-up questions.")
第 2 步:设置系统提示
from atomic_agents.lib.components.system_prompt_generator import SystemPromptGenerator system_prompt_generator = SystemPromptGenerator( background=[ "You are a knowledgeable assistant that provides helpful information and suggests follow-up questions." ], steps=[ "Analyze the user's input to understand the context and intent.", "Provide a relevant and informative response.", "Generate 3 suggested follow-up questions." ], output_instructions=[ "Ensure clarity and conciseness in your response.", "Conclude with 3 relevant suggested questions." ] )
第 3 步:初始化代理
from atomic_agents.agents.base_agent import BaseAgent, BaseAgentConfig import instructor import openai # Initialize the agent agent = BaseAgent( config=BaseAgentConfig( client=instructor.from_openai(openai.OpenAI(api_key='YOUR_OPENAI_API_KEY')), model="gpt-4", system_prompt_generator=system_prompt_generator, input_schema=CustomInputSchema, output_schema=CustomOutputSchema ) )
第 4 步:使用代理
user_input = "Can you explain the benefits of using Atomic Agents?" input_data = CustomInputSchema(chat_message=user_input) response = agent.run(input_data)
print(f"Agent: {response.chat_message}")
print("Suggested questions:")
for question in response.suggested_questions:
print(f"- {question}")
预期输出:
Agent: Atomic Agents simplifies AI development by providing modular, reusable components based on solid programming paradigms like the IPO model and atomicity.
Suggested questions:
- How does Atomic Agents compare to other AI frameworks?
- Can you provide an example of building an agent with Atomic Agents?
- What are the key features of Atomic Agents that enhance productivity?
整合工具和上下文提供程序
假设我们想让代理根据用户查询执行网络搜索。
第 1 步:下载并设置 SearxNGSearchTool
使用 Atomic Assembler CLI,我们可以下载搜索工具:
atomic
从菜单中选择 SearxNGSearchTool,然后按照说明安装依赖项。
第 2 步:集成搜索工具
from web_search_agent.tools.searxng_search import SearxNGSearchTool, SearxNGSearchToolConfig # 初始化搜索工具 search_tool = SearxNGSearchTool(config=SearxNGSearchToolConfig(base_url="http://localhost:8080"))
第 3 步:更新代理以使用工具
我们可以修改代理,以便根据用户的输入决定何时使用搜索工具。
from typing import Union class OrchestratorOutputSchema(BaseModel): tool: str = Field(..., description="The tool to use: 'search' or 'chat'") parameters: Union[SearxNGSearchTool.input_schema, CustomInputSchema] = Field(..., description="Parameters for the selected tool.") # 修改代理逻辑以输出 OrchestratorOutputSchema # ... # 执行选定的工具 if response.tool == "search": search_results = search_tool.run(response.parameters) # 处理检索结果 else: # 使用之前的聊天代理 pass
第 4 步:使用包含搜索结果的上下文提供程序
class SearchResultsProvider(SystemPromptContextProviderBase):
def __init__(self, search_results):
super().__init__(title="Search Results")
self.search_results = search_results
def get_info(self) -> str:
return "n".join(self.search_results)
# After obtaining search results
context_provider = SearchResultsProvider(search_results)
agent.register_context_provider("search_results", context_provider)
通过这种集成,代理可以根据实时网络搜索数据提供响应。
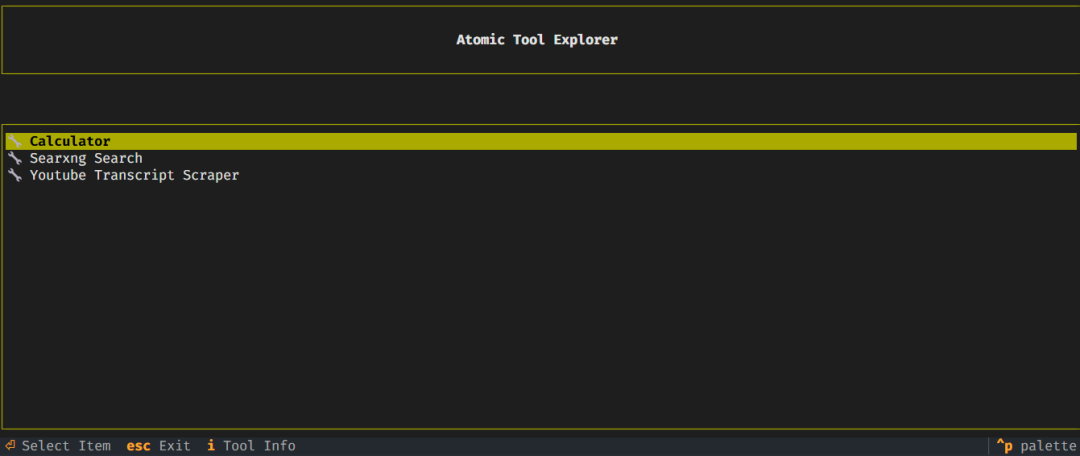
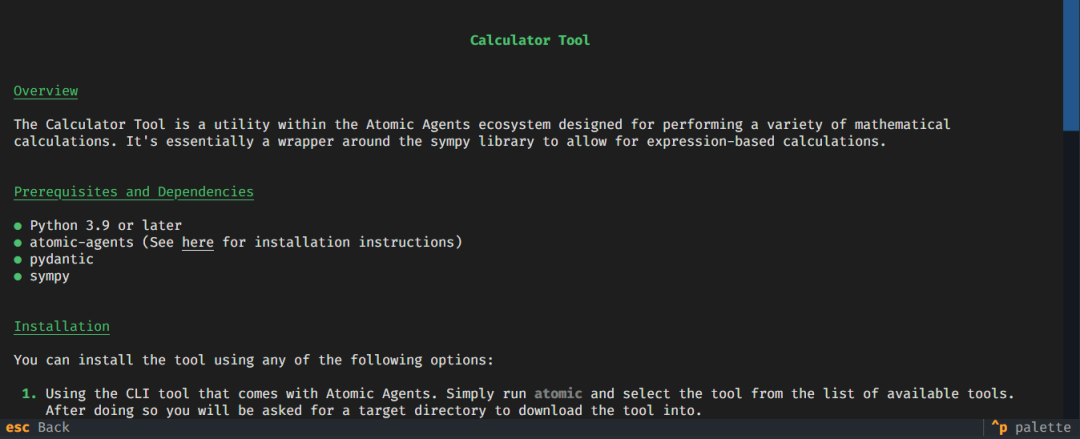
Atomic Assembler CLI:轻松管理工具
Atomic Agents的一个突出特点是Atomic Assembler CLI,这是一个简化工具和代理管理的命令行工具。
受一些现代尾风库(如shadcn)的启发,在这些库中,你不需要将组件作为依赖项安装,而是在自己的源代码中对它们拥有所有权。
这意味着我们不会使用 pip 将工具作为依赖项安装,而是将其复制到我们的项目中。有两种方法可以做到这一点:
- 手动下载工具,或从 Atomic Agents GitHub 代码库中复制/粘贴源代码,并将它们放到
atomic-forge文件夹中。 - 我们将使用 Atomic Assembler CLI 下载工具。

Atomic Agents
主要功能
- 下载和管理工具:轻松将新工具添加到项目中,无需手动复制或解决依赖问题。
- 避免依赖性杂乱:只安装您需要的工具,使您的项目保持精简。
- 轻松修改工具:每个工具都是独立的,有自己的测试和文档。
- 直接访问工具:如果你愿意,可以通过访问工具文件夹来手动管理工具。
写在最后
Atomic Agents 将简洁性、模块化和开发者控制放在首位,为人工智能开发领域带来了亟需的转变。通过采用输入-进程-输出模型和原子性等可靠的编程范式,它解决了许多开发人员在使用 LangChain、CrewAI 和 AutoGen 等现有框架时遇到的挫折。
有了Atomic Agents,你可以
- 消除不必要的复杂性,专注于构建有效的人工智能应用。
- 完全控制系统的每个组件。
- 轻松更换或修改组件,而不会中断整个应用程序。
- 利用模块化和可重用性提高工作效率和可维护性。
如果你已经厌倦了与过于复杂的框架搏斗,这些框架承诺过多,但交付不足,那么是时候试试 Atomic Agents 了。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章




暂无评论...