
论文地址:https://arxiv.org/abs/2404.17723
知识图谱只能有针对的抽取实体关系,这类可稳定抽取的实体关系可以理解为接近结构化数据。
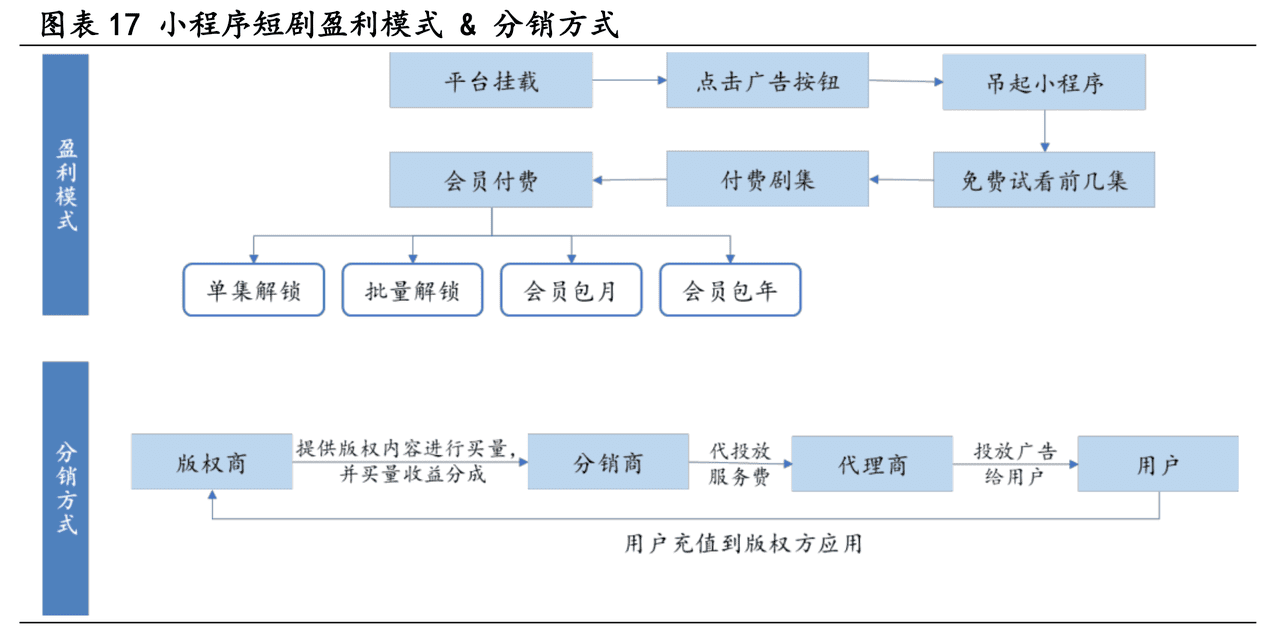
图1展示了一种结合了知识图谱(KG)和检索增强生成(RAG)的客户服务问答系统的工作流程。以下是对该流程的总结:
1. 知识图谱构:系统从历史客户服务问题票据中构建一个全面的知识图谱,包括两个主要步骤:
- 内票据树表示:每个问题票据被解析为一个树状结构,其中的节点代表票据的不同部分(如摘要、描述、优先级等)。
- 票据间连接:基于问题跟踪票据中的显式链接和通过语义相似性推导的隐式连接,将各个票据树连接成一个完整的图谱。
2. 嵌入生成:为图谱中的节点生成嵌入向量,使用预训练的文本嵌入模型(如BERT或E5),并将这些嵌入存储在向量数据库中。
3. 检索和问答过程:
- 问题意图嵌入:解析用户查询,识别命名实体和意图。
- 基于嵌入的检索:使用实体检索最相关的票据,并过滤出相关的子图。
- 过滤:进一步筛选和确定最相关的信息。
4. 检索到的票据:系统会检索到与用户查询相关的具体票据,如ENT-22970、PORT-133061、ENT-1744和ENT-3547,并展示它们之间的克隆(CLONE_FROM/CLONE_TO)和相似(SIMILAR_TO)关系。
5. 答案生成:最终,系统会综合检索到的信息和用户原始查询,通过大型语言模型(LLM)生成答案。
6. 图数据库和向量数据库:整个过程中,图数据库用于存储和管理图谱中的节点和链接,而向量数据库用于存储和管理节点的文本嵌入向量。
7. 使用LLM的步骤:在多个步骤中,大型语言模型被用来解析文本、生成查询、提取子图和生成答案。
这个流程图提供了一个高层次的视角,展示了如何通过结合知识图谱和检索增强生成技术来提高客户服务自动化问答系统的效率和准确性。

该图左侧展示了知识图谱的构建;右侧显示检索和问答过程。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...