
近日,英伟达(NVIDIA)联合麻省理工学院和清华大学,推出了一款名为SANA的开源图像生成模型。SANA不仅能够高效生成分辨率高达4096×4096的图像,还具备极快的生成速度。
SANA的性能表现
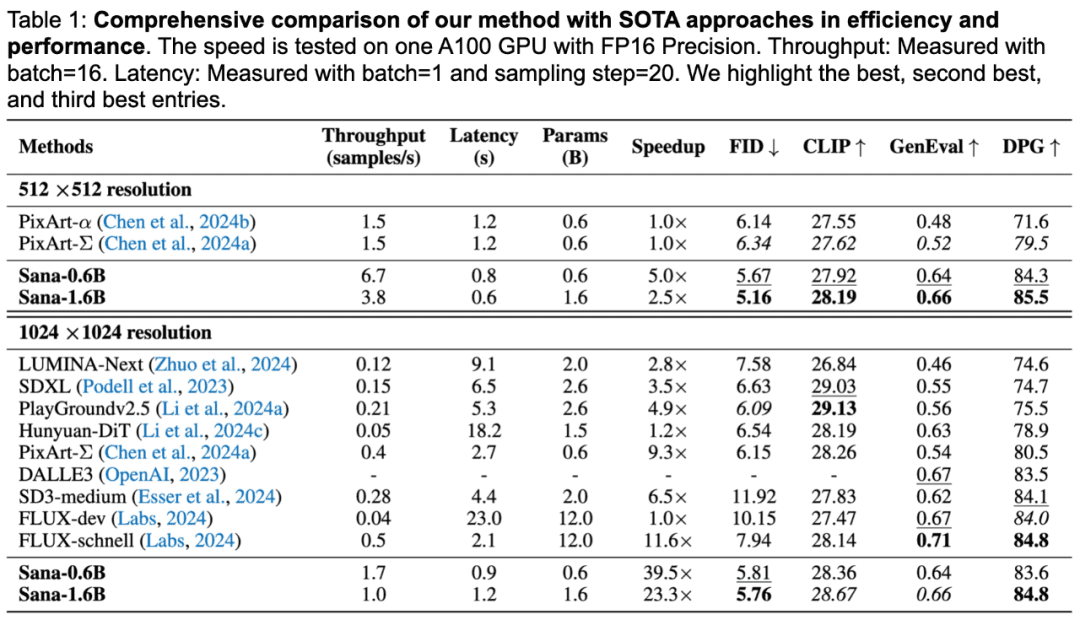
SANA的特点就是一个快字,SANA-0.6B只用不到一秒就可以生成1024×1024分辨率图像,比Flux-Dev快25倍,而生成4096×4096分辨率图像的速度比Flux-Dev快106倍。

在生成质量上,SANA在DPG-Bench测试基准中分数与Flux持平,仅在GenEval指标上略低于Flux模型。
SANA的核心设计
SANA的成功离不开其四大核心设计:
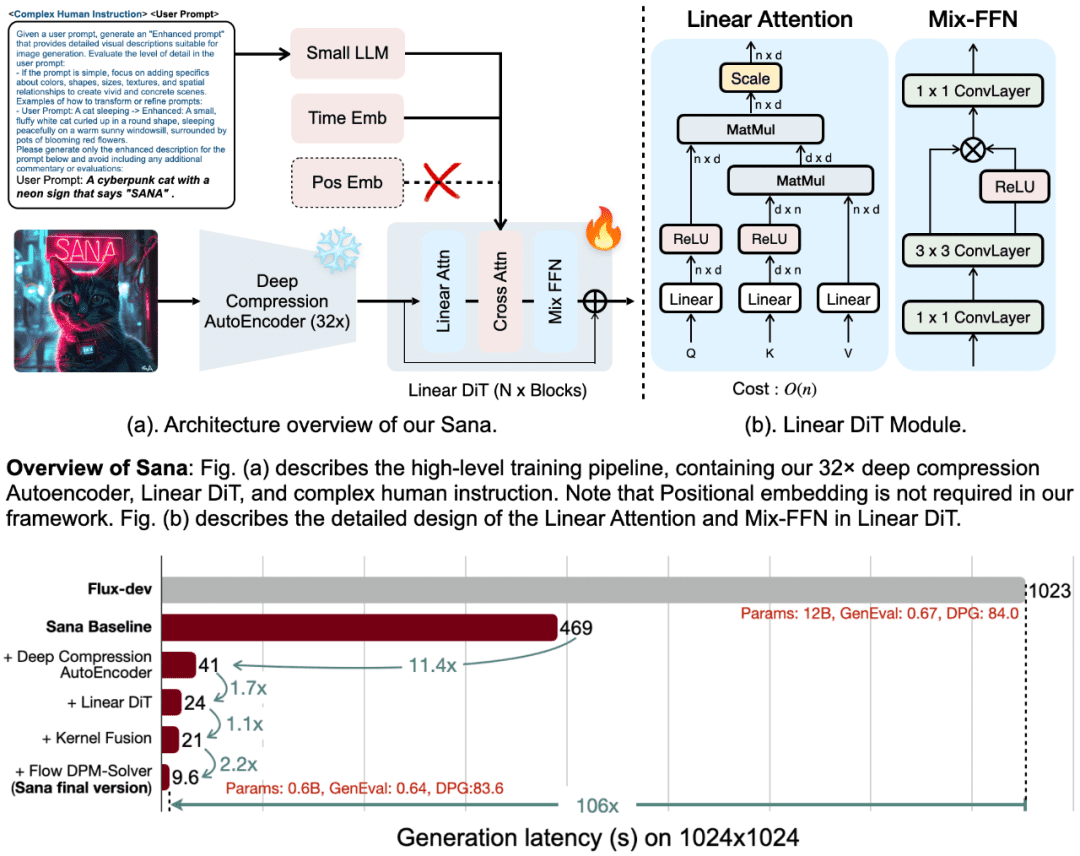
1. 深度压缩自动编码器(DC-AE)
传统的自动编码器(AE)通常将图像压缩8倍,而SANA引入了深度压缩自动编码器,将压缩倍数提升至32倍。这一设计大幅减少了潜在标记的数量,使得SANA能够高效生成超高分辨率图像(如4K分辨率),同时显著降低了训练和生成的计算成本。
2. 线性DIT(Diffusion Image Transformer)
SANA采用了一种新的线性注意力机制,取代了传统的二次注意力机制,将复杂度从O(N²)降低到O(N)。这一改进不仅提高了高分辨率图像生成的效率,还消除了对位置编码的需求,标志着首个无需位置嵌入的DIT模型诞生。
3. 仅解码器的小型LLM作为文本编码器
SANA使用仅解码器的小型语言模型(如Gemma 2)作为文本编码器,取代了传统的CLIP或T5模型。Gemma具备卓越的文本理解和指令遵循能力,结合复杂的人工指令设计,显著提升了图像与文本的对齐效果。
4. 高效的训练和推理策略
SANA提出了自动标记和训练策略,通过多个视觉语言模型(VLM)生成不同的重新字幕,并基于CLIPScore选择高质量字幕,从而加速模型收敛并增强文本-图像对齐。此外,SANA还引入了Flow-DPM-Solver,大幅减少了推理步骤,进一步提升了生成效率。
低成本部署与开源
SANA的另一个亮点是其低成本的部署能力。SANA-0.6B可以在16GB的笔记本电脑GPU上运行,生成1024×1024分辨率的图像仅需不到1秒,并且22GB显存能直出4096×4096分辨率图像,这一特性使得SANA不仅适用于高端计算设备,也能在普通用户的笔记本电脑上高效运行。此外,英伟达还宣布将公开发布SANA的代码和模型,进一步推动了文本到图像生成技术的普及和应用。
使用
英伟达建立了8个3090的网页使用界面,所有人都可以免费试用。值得一提的是SANA模型可以直接使用中文提示词。
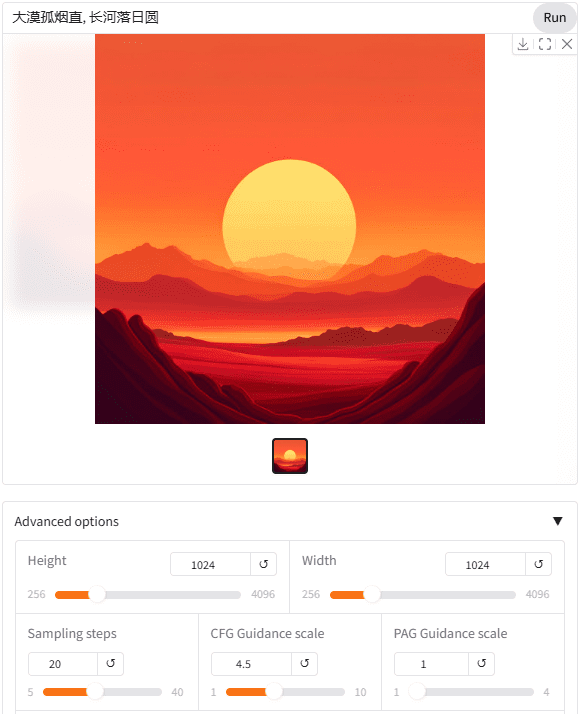
甚至使用带有图标符号的提示词也可以,这应该是得益于使用 Gemma2 2B 视觉语言模型作为文本编码器的原因。

通过ComfyUI_ExtraModels插件,在本地Comfyui上也能非常方便的使用SANA模型。插件安装很简单,不需要自己配置依赖,安装后运行会自动下载需要的模型文件。
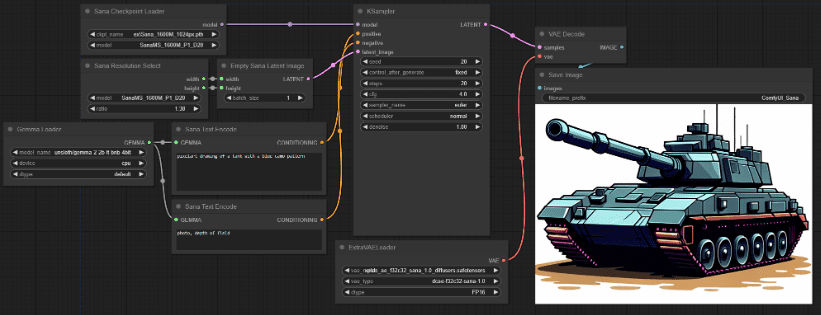
通过深度压缩自动编码器、线性DIT、仅解码器的小型LLM以及高效的训练和推理策略,SANA不仅能够高效生成超高分辨率图像,还具备强大的文本-图像对齐能力和低成本部署优势。对于需要快速出图的朋友,SANA还是不错的,就是在生态上还无法跟Flux比。

项目页:
github.com/NVlabs/Sana
网页使用:
nv-sana.mit.edu
Comfyui插件:
github.com/Efficient-Large-Model/ComfyUI_ExtraModels
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章




暂无评论...