
XTuner V1是什么
XTuner V1 是上海人工智能实验室开源的新一代大模型训练引擎,专为超大规模稀疏混合专家(MoE)模型训练设计。基于 PyTorch FSDP 开发,通过显存、通信和负载等多维度优化,实现了高性能训练。XTuner V1 支持高达1万亿参数的MoE模型训练,在2000亿以上量级模型上,训练吞吐量首次超越传统3D并行方案。支持64k长序列训练,无需序列并行技术,显著降低了专家并行依赖,提升了长序列训练效率。
XTuner V1的功能特色
- 无损训练:可训练2000亿规模的MoE模型,无需专家并行,6000亿模型仅需节点内专家并行。
- 长序列支持:支持2000亿MoE模型的64k序列长度训练,无需序列并行。
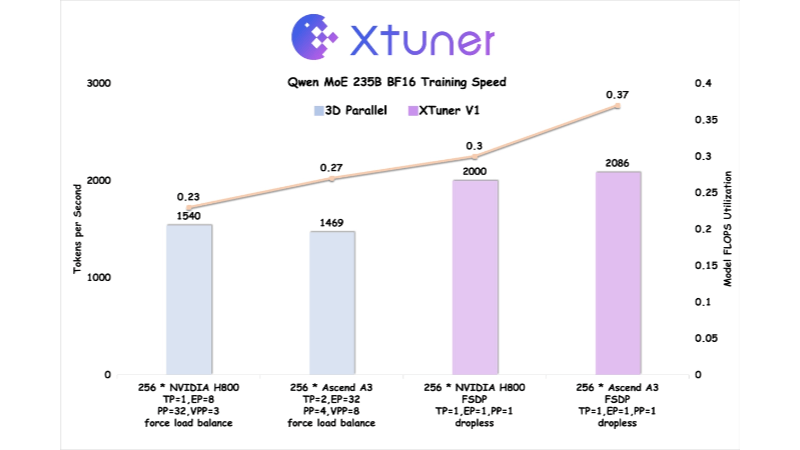
- 高效率:支持1万亿参数的MoE模型训练,2000亿以上模型训练吞吐量超传统3D并行。
- 显存优化:通过自动Chunk Loss机制和Async Checkpointing Swap技术,降低显存峰值。
- 通信掩盖:通过显存优化和Intra-Node Domino-EP技术,掩盖通信耗时。
- DP负载均衡:缓解变长注意力带来的计算空泡问题,保持数据并行维度的负载均衡。
- 硬件协同优化:与华为昇腾合作,在Ascend A3 NPU超节点上优化,训练效率反超NVIDIA H800。
- 开源与工具链支持:XTuner V1、DeepTrace和ClusterX开源,提供全方位支持。
XTuner V1的核心优势
- 高效训练:支持高达1万亿参数的MoE模型训练,训练吞吐量在2000亿以上量级模型中超越传统3D并行方案。
- 长序列处理:无需序列并行即可实现2000亿MoE模型的64k序列长度训练,适合强化学习等长文本处理场景。
- 低资源需求:2000亿参数模型无需专家并行,6000亿模型仅需节点内专家并行,降低了硬件资源需求。
- 显存优化:通过自动Chunk Loss机制和Async Checkpointing Swap技术显著降低显存峰值,支持更大模型训练。
- 通信优化:通过显存优化和Intra-Node Domino-EP技术掩盖通信耗时,减少通信开销对训练效率的影响。
- 负载均衡:缓解变长注意力带来的计算空泡问题,确保数据并行维度的负载均衡,提升训练效率。
XTuner V1官网是什么
- 项目官网:https://xtuner.readthedocs.io/zh-cn/latest/
- GitHub仓库:https://github.com/InternLM/xtuner
XTuner V1的适用人群
- 大模型研究人员:需要训练超大规模稀疏混合专家(MoE)模型的研究人员,XTuner V1 提供高性能的训练引擎,支持高达1万亿参数的模型训练。
- 深度学习工程师:从事大规模分布式训练的工程师,XTuner V1 提供了优化的通信和显存管理功能,能显著提升训练效率。
- AI基础设施开发者:关注硬件协同优化和高性能计算的开发者,XTuner V1 与华为昇腾技术团队合作,提供了针对特定硬件的深度优化。
- 开源社区贡献者:对开源项目感兴趣并希望参与贡献的开发者,XTuner V1 的开源代码提供了丰富的开发和优化机会。
- 企业AI团队:需要高效、低门槛的大模型训练解决方案的企业团队,XTuner V1 提供了易用且高性能的工具链支持。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...