
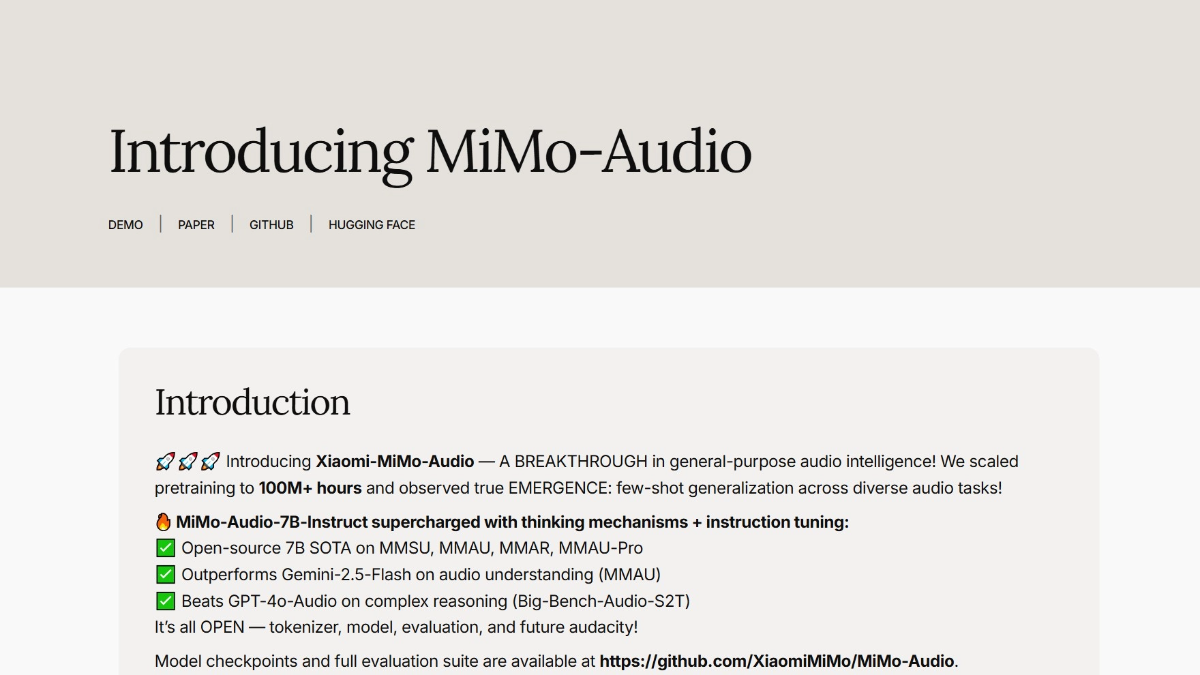
Xiaomi-MiMo-Audio是什么
Xiaomi-MiMo-Audio 是小米开源的70亿参数端到端语音大模型,具备多语言对话、语音续写、少样本泛化和音频理解等强大功能,能在语音智能和音频理解基准测试中达到SOTA水平,超越谷歌Gemini-2.5-Flash等模型。模型创新的语音无损压缩预训练和语音生成式预训练技术,使模型在语音转换、风格迁移等任务中表现出色。小米已开源了预训练模型MiMo-Audio-7B-Base、指令微调模型 MiMo-Audio-7B-Instruct、MiMo-Audio Tokenizer模型、技术报告及评估框架,助力语音大模型研究与语音AGI发展。
Xiaomi-MiMo-Audio的功能特色
- 多语言对话:支持与用户流畅交流,涵盖多种话题,如哲学、人生理想等,且能学习网络热梗和英语口语。
- 语音续写:能生成高度逼真的脱口秀、朗诵、直播和辩论等语音内容,保留说话者身份、韵律和环境声音等关键声学特性。
- 少样本泛化:训练数据中缺失某些任务(如语音转换、风格迁移、语音编辑)能轻松应对,展现出强大的泛化能力。
- 音频理解:具备音频字幕、音频推理和长时间音频理解功能,能处理和分析冗长的音频序列,提供详细描述和深入分析。
MiMo-Audio的核心优势
- 超大规模预训练数据:基于超1亿小时语音数据预训练,使模型具备强大泛化能力,能出色完成训练数据中缺失的复杂任务。
- 独创的语音无损压缩预训练技术:实现语音领域跨任务泛化性突破,让模型在少样本学习中展现“涌现”行为,提升效率。
- 首个开源的语音续写能力:作为开源领域首个具备语音续写能力的模型,能生成逼真的脱口秀、朗诵等语音内容,为创作带来新可能。
- 强大的音频理解能力:在音频字幕、推理及长时间音频理解上表现出色,能处理冗长音频序列并提供准确分析,助力音频内容自动标注与分析。
- 思考模式的引入:首次引入思考模式用于语音理解和生成过程,支持混合思考,使模型在语音交互中更灵活自然,适应不同场景与需求。
Xiaomi-MiMo-Audio的官网是什么
- 项目官网:https://xiaomimimo.github.io/MiMo-Audio-Demo/
- GitHub仓库:https://github.com/XiaomiMiMo/MiMo-Audio
- HuggingFace模型库:https://huggingface.co/collections/XiaomiMiMo/mimo-audio-68cc7202692c27dae881cce0
- 技术论文:https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf
Xiaomi-MiMo-Audio的适用人群
- 语音技术开发者:为开发者提供强大的语音模型,用在开发语音助手、语音交互应用等,加速语音技术产品的研发和创新。
- 语音内容创作者:帮助创作者高效生成有声读物、播客、脱口秀等语音内容,提升创作效率和质量。
- 语言学习者:作为语言学习工具,为学习者提供口语练习和语言交流的模拟环境,助力语言学习。
- 游戏开发者:用在游戏中的语音对话生成,为游戏角色赋予生动的语音表现,增强游戏的沉浸感。
- 教育工作者:将教学内容转化为语音讲解,制作语音课程和在线讲座,丰富教学形式,提高教学效果。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...