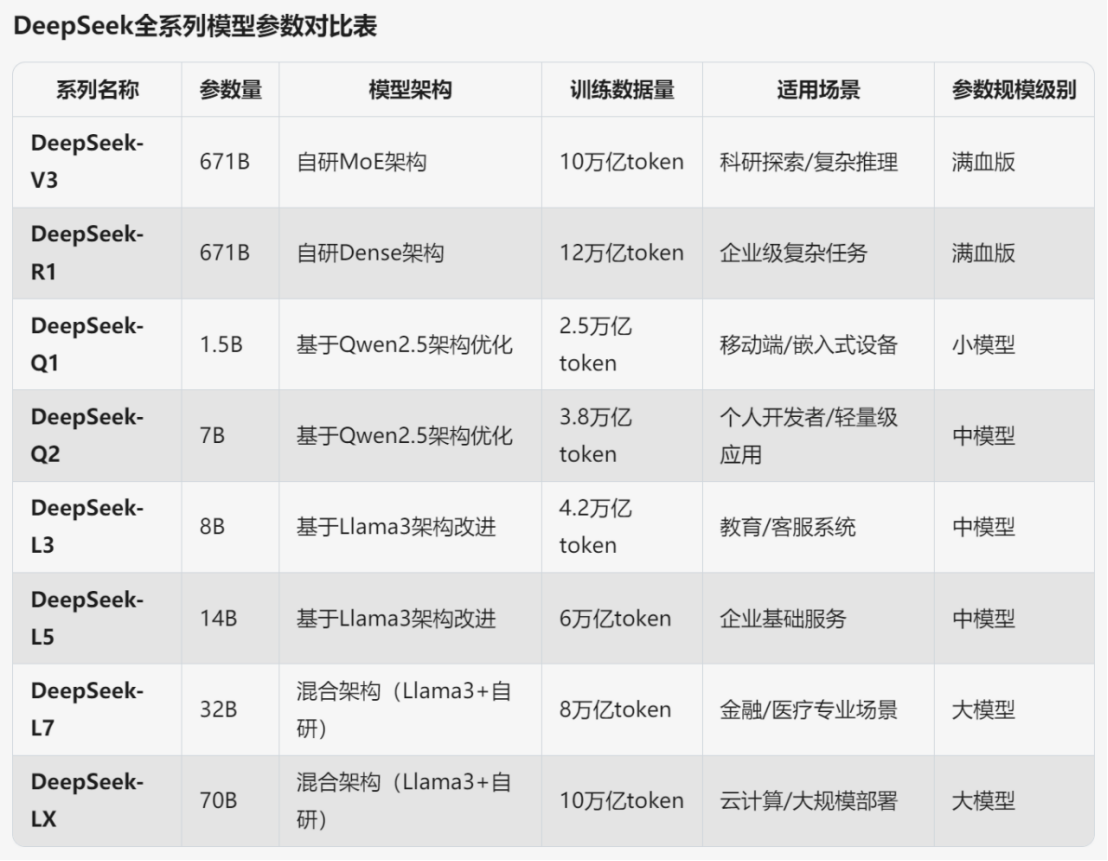

联邦学习的定义
联邦学习(Federated Learning)是一种创新的机器学习方法,由谷歌研究团队在2016年首次提出,解决数据隐私和分布式计算中的挑战。与传统机器学习不同,联邦学习不需将原始数据集中到中央服务器进行处理,允许数据保留在本地设备上,如智能手机、物联网传感器或边缘计算节点。核心过程涉及多个客户端设备协作训练一个共享模型:中央服务器初始化一个全局模型并将其分发给参与设备;每个设备使用本地数据对模型进行训练,生成模型更新(例如梯度或权重变化);这些更新被加密后发送回服务器;服务器聚合所有更新以优化全局模型,不接触任何原始数据。这种方法显著降低了数据泄露风险,符合现代数据保护法规如GDPR的要求。联邦学习的名称灵感来自政治学中的联邦制概念,强调各个实体在保持自治的同时实现协作。应用领域包括医疗健康、金融服务和智能设备,其中数据敏感性和隐私至关重要。联邦学习不仅支持监督学习任务,也适用于无监督和强化学习场景,推动了人工智能在隐私保护方向的发展。

联邦学习的工作原理
联邦学习的工作原理基于分布式计算与隐私保护技术的结合,通过多轮协作训练实现全局模型优化。
- 中心服务器协调初始化:中央服务器首先生成一个初始全局模型(如神经网络结构),该模型作为训练起点分发给参与设备。服务器负责协调训练流程,但不直接接触任何本地数据。
- 客户端设备本地训练:符合条件的设备(如手机、物联网终端)下载全局模型后,利用本地存储的非公开数据进行模型训练。所有计算在设备端完成,原始数据全程保留在本地,从根本上避免数据外流。
- 加密更新上传:设备仅向服务器上传经过加密和压缩的模型更新信息(如梯度或参数调整量)。这种设计大幅降低通信开销,同时通过加密技术防止中间环节的信息泄露。
- 安全聚合机制:服务器采用安全聚合算法(如联邦平均算法)整合来自多设备的更新。该过程支持加密状态下的参数合并,确保服务器无法追溯单个设备的更新内容。
- 多轮迭代优化:通过循环执行"分发-本地训练-上传-聚合"流程,模型在持续迭代中优化。训练终止条件通常设置为模型性能达标或收敛,最终生成具备泛化能力的全局模型。
- 差异化配置机制:系统支持动态调整参与设备数量、本地训练轮数等参数,以适应不同网络环境和计算能力,保证训练过程的稳定性与效率。
联邦学习的优势
联邦学习相比传统方法带来多项好处,尤其在数据隐私和效率方面。
- 隐私保护增强:原始数据始终保留在本地设备,避免了中央存储带来的泄露风险,符合严格的数据法规。
- 减少通信成本:只传输模型更新而非原始数据,降低了网络带宽需求,特别适用于移动设备或带宽受限环境。
- 利用分散数据:能整合来自多个源的数据,提高模型泛化能力,不需要数据共享或集中化。
- 提升可扩展性:支持大量设备并行训练,适应物联网和边缘计算场景,实现大规模机器学习部署。
- 增强用户信任:通过透明和隐私友好的方式,用户更愿意参与数据驱动的服务,促进人工智能应用普及。
联邦学习的应用场景
联邦学习在多个行业找到实际应用,解决数据孤岛和隐私问题。
- 医疗健康领域:医院或研究机构协作训练疾病诊断模型,患者数据保留在原机构,避免敏感医疗信息共享。
- 金融服务:银行使用联邦学习进行欺诈检测,整合不同分支的数据而不暴露客户交易细节,提高模型准确性。
- 智能手机输入法:谷歌键盘利用联邦学习改进预测模型,用户输入习惯在设备上本地训练,保护个人隐私。
- 物联网和智能家居:设备如智能音箱或传感器协作优化能源管理或语音识别,数据在边缘处理,减少云依赖。
- 自动驾驶汽车:车辆共享模型更新以改进导航系统,但不上传行驶数据,确保安全和隐私合规。
联邦学习的挑战
尽管有优势,联邦学习也面临一些技术和管理上的难题。
- 数据异构性:不同设备的数据分布可能非独立同分布(Non-IID),导致模型训练偏差或收敛困难,需要 advanced 聚合技术。
- 通信瓶颈:频繁的模型更新传输可能消耗网络资源,尤其在农村或低带宽地区,影响训练效率。
- 设备资源限制:客户端设备如手机可能有有限的计算能力、电池寿命或存储空间,制约训练深度和参与度。
- 安全威胁:数据不集中,模型更新仍可能泄露信息,面临推理攻击或恶意参与方,需加强加密和验证机制。
- 协调复杂性:管理大量异步设备需要 robust 的服务器架构和故障处理机制,增加系统设计和维护成本。
联邦学习的安全机制
为确保联邦学习过程的安全,多种技术被集成到框架中。
- 差分隐私(Differential Privacy):在模型更新中添加噪声,防止从更新中推断出个体数据信息,平衡隐私和模型效用。
- 安全多方计算(Secure Multi-Party Computation):允许多个设备协作计算模型聚合,而不暴露各自更新,通过加密协议实现。
- 同态加密(Homomorphic Encryption):服务器直接在加密更新上进行聚合操作,解密仅最终结果,避免中间数据泄露。
- 设备认证和访问控制:只有授权设备才能参与训练,防止恶意节点加入,通过数字证书或区块链技术强化身份验证。
- 审计和日志记录:监控训练过程,检测异常行为如模型投毒攻击,确保系统完整性和透明度。
联邦学习的发展历程
联邦学习的概念和实践经历了从萌芽到成熟的演变。
- 萌芽与早期探索(2010年代初期):联邦学习的理论基础源于分布式机器学习与密码学的交叉研究。随着边缘计算设备的普及,研究者开始探索在终端设备直接进行模型训练的可能,为联邦学习架构奠定基础。
- 技术概念正式提出(2016年):谷歌研究团队首次系统性地提出"联邦学习"术语,并通过手机输入法预测等实际案例验证其可行性。这一突破性工作吸引了工业界和学术界的广泛关注,开启了系统化研究热潮。
- 算法优化与突破(2017-2019年):研究重点转向解决实际部署挑战,包括非独立同分布数据挑战、通信效率优化等。联邦平均算法等核心算法的提出显著提升了训练效率,使得联邦学习在多种场景的应用成为可能。
- 开源生态与框架发展(2020年至今):TensorFlow Federated、PySyft等开源框架的出现大幅降低了技术使用门槛。各行业开始尝试在医疗、金融等领域部署联邦学习系统,推动技术从实验室走向实际应用。
- 标准化与生态建设(现阶段):IEEE等标准组织开始制定联邦学习技术框架和评估标准,重点关注安全规范、性能指标和系统兼容性。这些努力为技术的大规模产业化应用奠定坚实基础。
联邦学习与集中式学习的比较
联邦学习和传统集中式学习在多个维度存在差异。
- 数据位置:联邦学习数据分散在客户端,集中式学习数据集中在服务器,前者隐私更好但协调更复杂。
- 通信模式:联邦学习需要频繁上下行传输模型更新,集中式学习一次性上传数据,通信模式影响成本和延迟。
- 可扩展性:联邦学习更适合大规模分布式环境,集中式学习受服务器容量限制,扩展性较差。
- 合规性:联邦学习天然符合数据本地化法规,集中式学习需额外措施满足隐私要求,增加合规负担。
联邦学习的未来趋势
联邦学习的发展方向聚焦于技术创新和更广泛的应用。
- 算法进步:研究更高效的聚合方法和适应Non-IID数据的算法,提高模型收敛速度和准确性。
- 硬件集成:与边缘计算芯片和5G网络结合,实现低延迟训练,支持实时应用如 augmented reality。
- 跨领域融合:与区块链结合增强审计能力,或与联邦数据库协作,解决数据孤岛问题。
- 标准化和法规:行业组织制定统一标准,政府出台指导政策,促进联邦学习合规部署。
- 用户体验优化:简化开发工具和界面,让非专家也能轻松实施,加速普及到中小企业。
联邦学习的实际案例
现实世界中,联邦学习已在多个项目中成功应用。
- 谷歌键盘项目:数百万用户设备协作训练文本预测模型,每日处理数十亿次输入,而不上传个人输入数据。
- 医疗影像分析:多家医院使用联邦学习训练癌症检测模型,数据保留在各医院,提高诊断准确性并保护患者隐私。
- 金融风控系统:银行联盟通过联邦学习构建反欺诈模型,共享风险模式而不交换客户数据,增强整体安全。
- 智能城市项目:交通传感器协作优化信号控制,模型更新共享以减少拥堵,数据在本地处理。
- 工业物联网:制造设备预测维护需求,工厂间共享模型见解,避免停机同时保护专有操作数据。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...