

VTP是什么
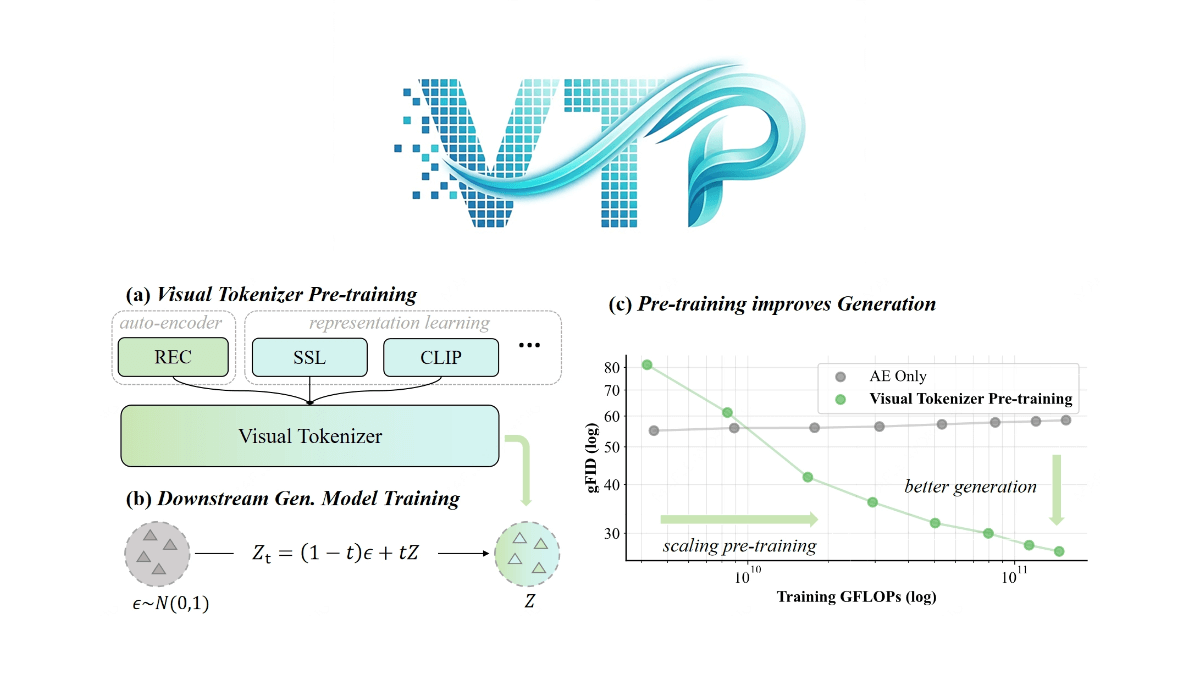
VTP(Visual Tokenizer Pre-training)是MiniMax海螺视频团队提出的视觉生成模型关键技术,通过改进视觉分词器(tokenizer)的预训练方法提升生成系统性能。传统方法中,tokenizer仅关注图像重建,但VTP创新性地引入语义理解能力,成为生成质量的核心驱动因素。框架采用Vision Transformer架构,通过两阶段训练策略(预训练阶段优化表征学习,微调阶段提升画质)和多任务目标(重建、自监督、图文对比),首次实现tokenizer的规模化扩展,即算力、数据量增加时生成效果同步提升。实验显示,VTP在同等计算预算下显著超越传统VAE,为扩散模型和多模态大模型提供了更高效的视觉底座。
VTP的功能特色
- 多任务联合优化:VTP通过结合图像-文本对比学习、自监督学习(如自蒸馏和掩码图像建模)以及像素级重建目标,实现多任务联合训练,提升模型的语义理解和空间感知能力。
- 高效可扩展性:VTP展示了出色的可扩展性,其生成性能随着训练计算量(FLOPs)、模型参数和数据集大小的增加而稳步提升,突破了传统自编码器在大规模预训练时的性能瓶颈。
- 优异的生成性能:在ImageNet上,VTP实现了78.2%的零样本分类准确率和0.36的rFID,显著优于其他方法,且在下游生成任务中表现出色,仅通过增加预训练计算量就能显著提升生成质量。
- 快速收敛:VTP从预训练阶段开始重新设计,相比基于蒸馏基础模型的方法,实现了更高的性能上限和4.1倍更快的收敛速度,大大提高了训练效率。
- 开源与易用性:VTP提供了详细的安装和使用指南,包括预训练权重的下载和快速启动脚本,方便研究人员和开发者快速上手并应用于实际项目中。
VTP的核心优势
- 多任务学习融合:VTP整合了图像-文本对比学习、自监督学习和像素级重建目标,通过多任务联合优化,使模型在语义理解和生成能力上得到显著提升。
- 强大的可扩展性:VTP在预训练阶段展现出优异的可扩展性,其生成性能随着计算量、模型参数和数据集规模的增加而稳步提升,突破了传统自编码器的局限。
- 卓越的生成质量:在ImageNet等基准测试中,VTP实现了78.2%的零样本分类准确率和0.36的rFID,生成质量显著优于其他方法,且在下游生成任务中表现出色。
- 快速收敛能力:VTP从预训练阶段开始重新设计,相比传统方法,实现了更高的性能上限和4.1倍更快的收敛速度,大大提高了训练效率。
- 开源与易用性:VTP提供详细的安装指南和预训练权重,用户可以快速上手并应用于实际项目,降低了使用门槛。
- 创新的预训练范式:VTP提出了一种新的视觉分词器预训练范式,通过多任务学习提升生成能力,为视觉生成领域提供了新的思路和方法。
VTP官网是什么
- GitHub仓库:https://github.com/MiniMax-AI/VTP
- HuggingFace模型库:https://huggingface.co/collections/MiniMaxAI/vtp
- arXiv技术论文:https://arxiv.org/pdf/2512.13687v1
VTP的适用人群
- 深度学习研究人员:对视觉生成模型感兴趣,希望探索新的预训练方法以提升生成质量和语义理解能力的研究者,VTP提供了新的技术框架和实验思路。
- 计算机视觉工程师:致力于开发高质量视觉生成应用(如图像生成、视频生成等)的工程师,VTP的高效可扩展性和优异性能可以帮助他们快速实现和优化生成任务。
- 自然语言处理专家:关注跨模态学习和多模态融合的研究者,VTP通过图像-文本对比学习等技术,为视觉和语言的联合建模提供了新的视角和工具。
- 机器学习开发者:希望在实际项目中快速部署和应用预训练模型的开发者,VTP的开源代码和详细的使用指南降低了使用门槛,便于快速集成到项目中。
- 学术研究人员:从事人工智能、计算机视觉和自然语言处理相关领域的学术研究者,VTP为他们提供了新的研究方向和实验平台,有助于推动相关领域的学术进展。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...