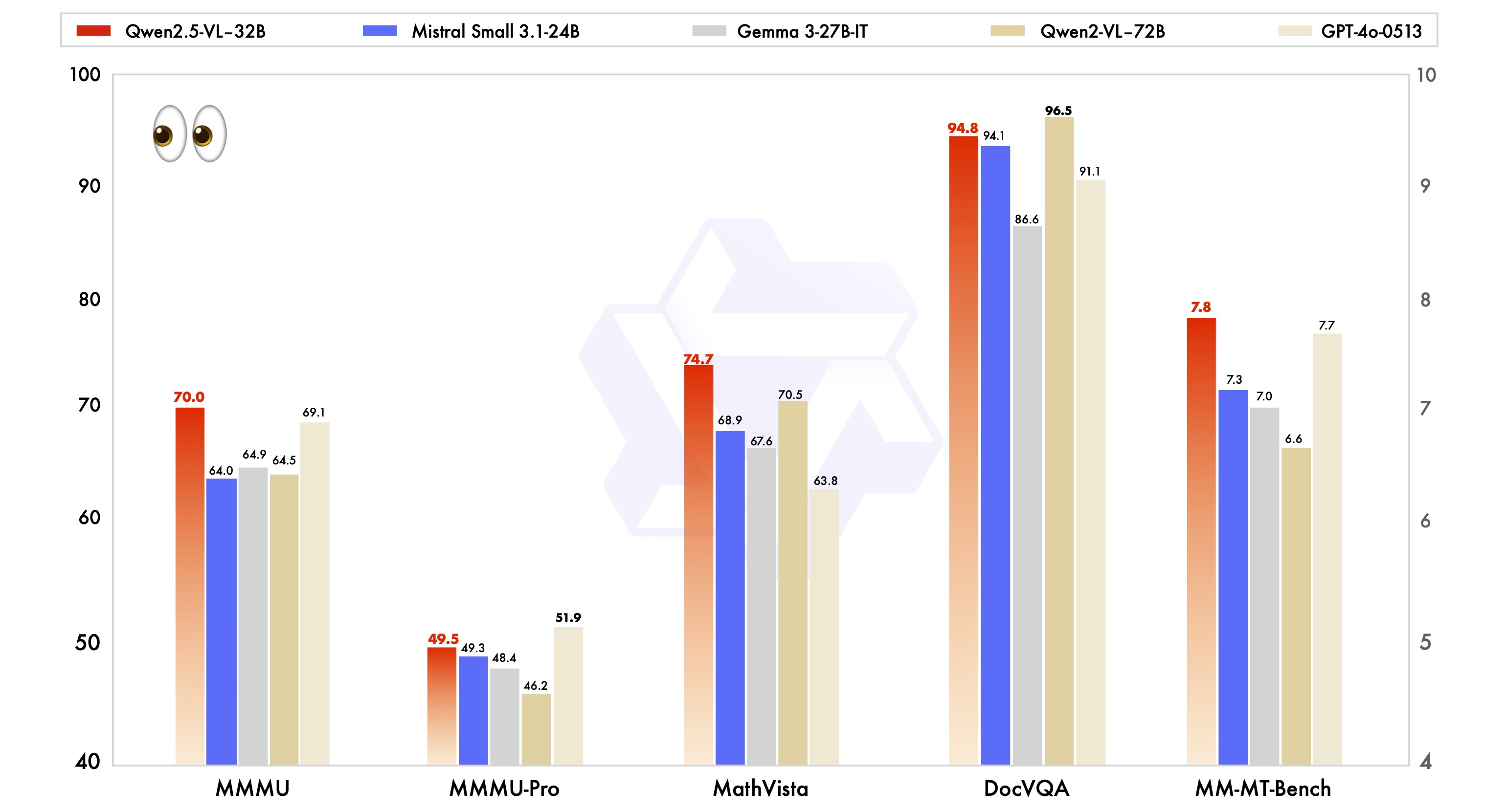

我们推出了
vdr-2b-multi-v1,这是用于视觉文档检索的最佳多语言嵌入模型。我们还发布了它的纯英文版本vdr-2b-v1,并开源了新的vdr-multilingual-train数据集。该数据集包含 50 万个高质量样本,是用于视觉文档检索的最大开源多语言合成数据集。

隆重推出 vdr-2b-multi-v1 (🤗) ,这是一款为跨多种语言和领域的视觉文档检索而设计的多语言嵌入模型。此模型旨在将文档页面截图编码为密集的单向量表示,这将有效地允许搜索和查询视觉丰富的多语言文档,而无需任何 OCR、数据提取管道、分块...
vdr-2b-multi-v1 模型基于 MrLight/dse-qwen2-2b-mrl-v1 ,并在大量自制的多语言查询-图像对数据集上进行训练。此模型是与 LlamaIndex 合作构建的,是 mcdse-2b-v1 的下一个迭代版本。我们的 vdr-2b-multi-v1 扩展并改进了用于训练它的学习和方法,从而产生了一个更强大、更好的模型。
- 在 🇮🇹 意大利语、🇪🇸 西班牙语、🇬🇧 英语、🇫🇷 法语和 🇩🇪 德语上进行训练: 它们共同构成了一个新的大型开源多语言训练数据集,包含 50 万个高质量样本。
- 低显存和更快的推理速度:在合成视觉文档检索 (ViDoRe) 基准测试中,我们使用 768 个图像块的纯英文模型比使用 2560 个图像块的基础模型表现更好。这使得推理速度提高了 3 倍,并大大降低了显存使用量。
- 跨语言检索:在真实场景中明显更好。例如,您可以使用意大利语查询搜索德语文档。
- Matryoshka 表示学习:您可以将向量大小缩小 3 倍,同时仍保持 98% 的嵌入质量。这可以在降低存储成本的同时显着提高检索速度。
用法
🎲 立即试用
vdr-2b-multi-v1,可在 Hugging Face Space 上找到!
通过 SentenceTransformers 和 LlamaIndex 的直接集成,使用 vdr-2b-multi-v1 生成嵌入比以往任何时候都更容易。只需几行代码即可开始使用:
通过 LlamaIndex
pip install -U llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
model = HuggingFaceEmbedding(
model_name="llamaindex/vdr-2b-multi-v1",
device="cpu", # "mps" for mac, "cuda" for nvidia GPUs
trust_remote_code=True,
)
image_embedding = model.get_image_embedding("image.png")
query_embedding = model.get_query_embedding("Chi ha inventato Bitcoin?")
通过 SentenceTransformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
model_name_or_path="llamaindex/vdr-2b-multi-v1",
device="cuda",
trust_remote_code=True,
# These are the recommended kwargs for the model, but change them as needed if you don't have CUDA
model_kwargs={
"torch_dtype": torch.bfloat16,
"device_map": "cuda:0",
"attn_implementation": "flash_attention_2"
},
)
embeddings = model.encode("image.png")
训练数据集
为视觉文档检索训练良好的单向量模型需要高质量的数据,但是当前的多模态现成数据集非常稀缺且不是多语言的。
因此,我们花费了大量时间从头开始构建它。原始数据集包含 50 万个多语言查询-图像样本,这些样本是使用公共互联网 PDF 从头收集和生成的。与每个图像关联的查询是使用视觉语言模型 (VLM) 合成生成的。作为比较,我们的数据集比先前最大的用于多模态视觉文档检索的开源合成数据集(即为 ColPali 训练数据集 生成的废弃文档)多 10 倍样本。

数据收集
对于每种语言,我们生成一个涵盖许多不同主题的长查询列表,然后将其用于搜索 PDF。我们使用搜索引擎的语言过滤功能来抓取仅使用指定语言的文档。这种“按主题搜索”技术确保模型已经看到许多不同的主题和领域,并且在现实生活场景中表现良好。
抓取过程产生了约 5 万份多语言文档。与之前的 mcdse-2b-v1 模型中使用的方法相反,页面不是随机提取的。相反,每个 PDF 的每个页面都通过文档布局分析模型运行,以确定该页面包含更多的文本元素还是视觉元素。结果是一个将页面分类为仅文本、仅视觉或混合的数字。然后使用此标记步骤对约 10 万个页面进行采样,确保它们按页面类型均匀分布。
合成生成
然后使用 gemini-1.5-pro 和 Qwen2-VL-72B 生成查询。他们的任务是提出一个具体的问题和一个一般的问题。只有具体的问题才用于训练模型,但是迫使大语言模型 (LLM) 区分两者通常会导致更强大的具体问题用于信息检索训练。
生成后,进一步的清理步骤可确保问题足以进行训练。这包括:
- 确保语言正确
- 修复格式问题
- 删除 markdown
- 确保只提出一个问题
- 删除基础短语(例如,“根据图 1”、“本文档”、...)
过滤和硬负例挖掘
此清理步骤确保查询在语法上正确并遵循一些严格的准则。但这仍然不能确保查询足以用于信息检索。
为了过滤掉不好的问题,我们使用 voyage-3 嵌入模型嵌入并索引了每个广泛的查询。对于每个具体的问题,我们搜索索引。如果其相关的广泛问题出现在前 100 个结果中,则该查询被标记为“良好”。此方法删除低熵、重复或太相似的问题。平均而言,每个语言数据集中删除了 40% 的查询。
然后仅在具有 0.75 固定阈值的特定问题上使用 voyage-3 挖掘硬负例。还使用了如 nvidia/NV-Retriever-v1 中所述的正例感知负例挖掘进行了实验,但是在此数据集上,它似乎产生了过于容易/遥远的负例。
下载
(vdr-multilingual-train 🤗)训练数据集现在是开源的,可直接在 Hugging Face 上获取。训练数据集包含 496,167 个 PDF 页面,其中只有 280,679 个页面与过滤后的查询相关联(使用上述方法)。其余没有查询的图像仍然用作硬负例。
| 语言 | # 已过滤查询 | # 未过滤查询 |
|---|---|---|
| 英语 | 53,512 | 94,225 |
| 西班牙语 | 58,738 | 102,685 |
| 意大利语 | 54,942 | 98,747 |
| 德语 | 58,217 | 100,713 |
| 法语 | 55,270 | 99,797 |
| 总计 | 280,679 | 496,167 |
该数据集由 5 个不同的子集组成,每个子集对应一种语言。您可以在此处直接浏览它:
数据集由 5 个不同的子集组成,每个子集对应一种语言。您可以在这里直接探索它:
或者,您可以在 load_dataset 中指定语言子集,单独下载语言:
from datasets import load_dataset
italian_dataset = load_dataset("llamaindex/vdr-multilingual-train", "it", split="train")
english_dataset = load_dataset("llamaindex/vdr-multilingual-train", "en", split="train")
french_dataset = load_dataset("llamaindex/vdr-multilingual-train", "fr", split="train")
german_dataset = load_dataset("llamaindex/vdr-multilingual-train", "de", split="train")
spanish_dataset = load_dataset("llamaindex/vdr-multilingual-train", "es", split="train")
评估

该模型已在 ViDoRe 基准测试和自定义构建的评估集上进行了评估,这些评估集允许测试其在仅文本、仅视觉和混合页面屏幕截图上的多语言功能。评估数据集也可在 Hugging Face 上公开获取(vdr-multilingual-test 🤗)。
我们确保这些数据集中的任何页面都不会出现在训练集中,以避免任何评估污染。这些数据集的收集和生成方法与训练数据集相同,但样本量较小。过滤步骤全部手动完成:对每个查询进行评估、整理和改进(如有必要),以确保高质量的数据。
所有评估均通过使用 1536 维向量和可以使用 最多 768 个 Token 表示的图像分辨率来计算 NDCG@5 分数来执行。
| 平均 | 法语 (文本) | 法语 (视觉) | 法语 (混合) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 93.5 | 94.7 | 90.8 | 95.1 |
| vdr-2b-multi-v1 | 95.6 | 95.6 | 93.3 | 97.9 |
| +2.2% |
| 平均 | 德语 (文本) | 德语 (视觉) | 德语 (混合) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 93.0 | 93.4 | 90.0 | 95.5 |
| vdr-2b-multi-v1 | 96.2 | 94.8 | 95.7 | 98.1 |
| +3.4% |
| 平均 | 意大利语 (文本) | 意大利语 (视觉) | 意大利语 (混合) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 95.1 | 95.1 | 94.0 | 96.2 |
| vdr-2b-multi-v1 | 97.0 | 96.4 | 96.3 | 98.4 |
| +2% |
| 平均 | 西班牙语 (文本) | 西班牙语 (视觉) | 西班牙语 (混合) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 96.7 | 97.2 | 94.7 | 98.2 |
| vdr-2b-multi-v1 | 98.1 | 98.3 | 96.9 | 99.1 |
| +1.4% |
| 平均 | 英语 (文本) | 英语 (视觉) | 英语 (混合) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 98.0 | 98.3 | 98.5 | 97.1 |
| vdr-2b-multi-v1 | 98.1 | 97.9 | 99.1 | 97.3 |
| +0.1% |
多语言模型在每种语言和每种页面类型上的表现都优于基础模型,平均提高了 +2.3%。在 ViDoRe 基准测试中,它的表现也略好 (+0.5%)。我们微调的 vdr-2b-multi-v1 在性能方面取得了巨大飞跃,尤其是在非英语的纯视觉或混合页面方面。例如,请参阅德语纯视觉检索相比基础模型提高了 +6.33% 的 NDCG@5。
我们还在英语子集上训练了一个版本(vdr-2b-v1 🤗)。在完整的 ViDoRe 基准测试中(使用 768 个图像 Token 进行评估),多语言版本和纯英文版本的性能都优于基础模型。
| 平均 | shiftproject | government | healthcare | energy | ai | docvqa | arxivqa | tatdqa | infovqa | tabfquad | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 83.6 | 79.8 | 95.7 | 96.9 | 92.0 | 98.2 | 56.3 | 85.2 | 53.9 | 87.5 | 90.3 |
| vdr-2b-multi-v1 | 84.0 | 82.4 | 95.5 | 96.5 | 91.2 | 98.5 | 58.5 | 84.7 | 53.6 | 87.1 | 92.2 |
| vdr-2b-v1 | 84.3 | 83.4 | 96.9 | 97.2 | 92.6 | 96.8 | 57.4 | 85.1 | 54.1 | 87.9 | 91.3 |
更快的推理

纯英文 vdr-2b-v1 模型在 ViDoRe 基准合成数据集上的性能也与基础模型相匹配,同时仅使用 30% 的图像 Token(768 个对比 2560 个)。这有效地使推理速度提高了 3 倍,并大大降低了显存使用量。
| 平均 | shiftproject | government | healthcare | energy | ai | |
|---|---|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 (2560 个图像 Token) | 93.0 | 82 | 96 | 96.4 | 92.9 | 97.5 |
| vdr-2b-v1 (768 个图像 Token) | 93.4 | 83.4 | 96.9 | 97.2 | 92.6 | 96.8 |
跨语言检索
尽管该模型是分别在每种语言上进行训练的,但它在跨语言检索方面也有所改进。为了测试此能力,使用 DeepL 将德语评估集查询翻译成意大利语。文档页面截图保留为原始德语。
| 平均 | 意大利语 -> 德语 (文本) | 意大利语 -> 德语 (视觉) | 意大利语 -> 德语 (混合) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 93.1 | 92.6 | 93.5 | 93.3 |
| vdr-2b-multi-v1 | 95.3 | 95.0 | 95.8 | 95.1 |
| +2.3% |
该模型在所有文档类型上的表现都明显更好,平均提高了 +2.3%。这些检索能力对于现实世界的用例至关重要,尤其是在欧洲等语言分散的地区。例如,它可以在复杂的欧洲约束性决定、说明手册、金融资产 KID、药品包装说明书等复杂的多语言来源上实现与语言无关的搜索。
MRL 和二进制嵌入
此模型使用 Matryoshka 表示学习 (MRL) 进行训练。训练期间使用的损失函数经过校准,可以跟踪所有这些维度上的性能,从而使模型能够预先加载最重要的识别信息。这使您可以根据规模和预算有效地缩小嵌入维度。要了解有关 MRL 的更多信息,Hugging Face 的此博客文章对此进行了很好的解释。
为了测试模型在不同向量维度下的检索能力,在意大利语 -> 德语跨语言基准中进行评估。
NDCG@5(浮点数)
| 平均 | 意大利语 -> 德语 (文本) | 意大利语 -> 德语 (视觉) | 意大利语 -> 德语 (混合) | |
|---|---|---|---|---|
| 1536 维 | ||||
| dse-qwen2-2b-mrl-v1 | 93.1 | 92.6 | 93.5 | 93.3 |
| vdr-2b-multi-v1 | 95.3 | 95.0 | 95.9 | 95.1 |
| +2.3% | ||||
| 1024 维 | ||||
| dse-qwen2-2b-mrl-v1 | 92.2 | 90.9 | 92.3 | 93.5 |
| vdr-2b-multi-v1 | 94.6 | 93.1 | 95.7 | 95.1 |
| +2.5% | ||||
| 512 维 | ||||
| dse-qwen2-2b-mrl-v1 | 89.8 | 87.9 | 89.4 | 92.2 |
| vdr-2b-multi-v1 | 93.0 | 91.1 | 93.4 | 94.5 |
| +3.4% |
NDCG@5(二进制)
| 平均 | 意大利语 -> 德语 (文本) | 意大利语 -> 德语 (视觉) | 意大利语 -> 德语 (混合) | |
|---|---|---|---|---|
| 1536 维 | ||||
| dse-qwen2-2b-mrl-v1 | 89.8 | 88.2 | 90.3 | 90.8 |
| vdr-2b-multi-v1 | 92.3 | 89.6 | 94.1 | 93.3 |
| +2.8% | ||||
| 1024 维 | ||||
| dse-qwen2-2b-mrl-v1 | 86.7 | 84.9 | 88.2 | 86.9 |
| vdr-2b-multi-v1 | 90.8 | 87.0 | 92.6 | 92.8 |
| +4.6% | ||||
| 512 维 | ||||
| dse-qwen2-2b-mrl-v1 | 79.2 | 80.6 | 81.7 | 75.4 |
| vdr-2b-multi-v1 | 82.6 | 77.7 | 86.7 | 83.3 |
| +4.0% |
1024 维浮点向量在质量和大小之间提供了非常好的平衡。它们小约 30%,但仍保留了 99% 的检索性能。1536 维二进制向量也是如此,每个向量的字节数减少了 10 倍,但仍保留了 97% 的检索质量。有趣的是,1536 个二进制向量几乎与基础模型的 1536 个浮点向量的性能相匹配。
结论和下一步
我们相信 vdr-2b-multi-v1 和 vdr-2b-v1 将被证明对许多用户有用。
我们的多语言模型是同类中的第一个,它显着提高了多语言和跨语言场景中的性能,并且由于 MRL 和二进制量化,检索比以往任何时候都更加高效和快速。我们认为这将开启新的用例和机会,尤其是在欧洲等语言分散的地区。
它的纯英文版本代表了对基础模型的重大改进,现在能够以 3 倍的速度嵌入文档,同时减少了显存并保持相同(或更好)的检索质量。
这一切都归功于新的 vdr-multilingual-train 数据集。该数据集包含 50 万个高质量样本,是用于视觉文档检索的最大多语言开源合成数据集。
未来的工作将探索我们的模型在适应新的和特定领域时的表现。这仍处于开发的早期阶段,在发布结果之前还需要做更多的工作,但早期测试似乎已经表明,以非常少的数据和计算资源实现了令人印象深刻的检索增益。
请继续关注未来的更新!
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...