
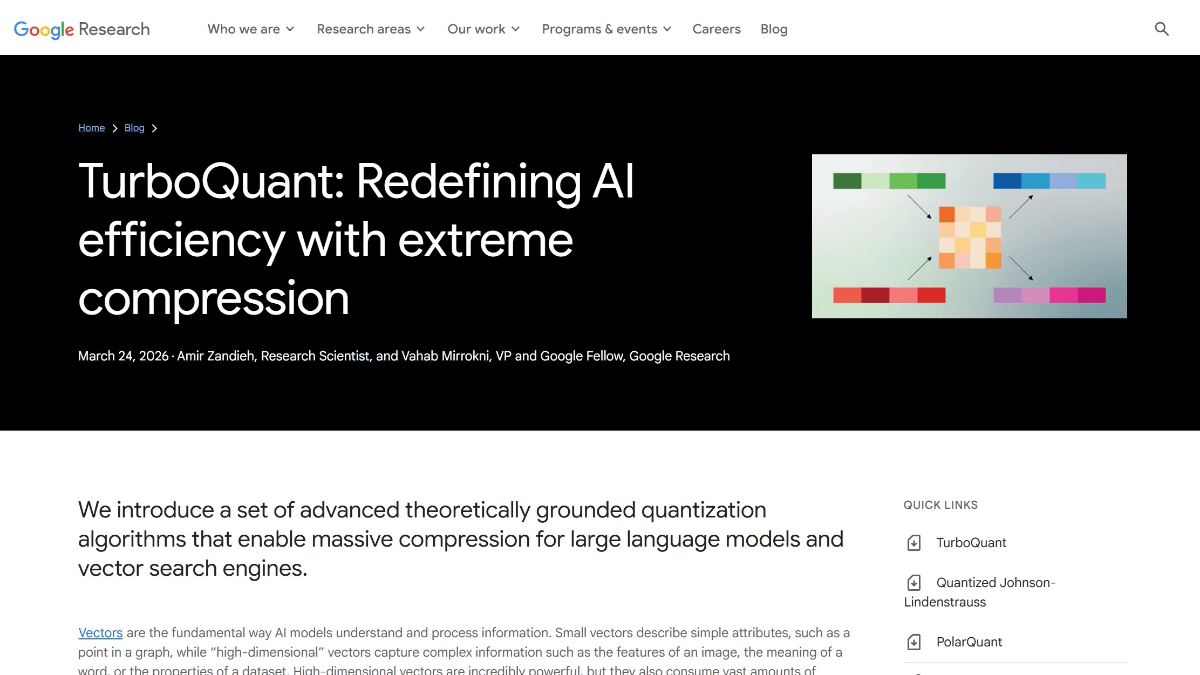
TurboQuant是什么
TurboQuant 是 Google Research 推出的突破性内存压缩算法,专为解决大语言模型推理中的 KV 缓存瓶颈而设计。技术通过 PolarQuant 极坐标量化与 QJL 量化变换相结合,将传统 16bit/32bit 的键值缓存压缩至仅 3bit,实现 6 倍以上内存节省,同时在英伟达 H100 GPU 上带来最高 8 倍的注意力计算加速。
TurboQuant的功能特色
- 极致压缩:将 KV 缓存从常规的 16bit/32bit 压缩至 3bit,实现 6倍以上内存节省。
- 零精度损失:在 3.5-bit 配置下实现绝对质量中性,2.5-bit 配置下仅边际性能下降。
- 无需重新训练:可直接应用于现有模型(如 Gemma、Mistral),无需微调或重新训练。
- 性能大幅提升:在英伟达 H100 GPU 上,注意力计算速度最高提升 8倍。
TurboQuant的核心优势
- 极致压缩率:将 KV 缓存从 16bit/32bit 压缩至 3bit,实现 6 倍以上内存节省,大幅降低推理成本。
- 零精度损失:在 3.5-bit 配置下实现绝对质量中性,2.5-bit 配置下仅边际性能下降,保证模型输出质量。
- 即插即用:无需重新训练或微调,可直接应用于现有大模型(如 Gemma、Mistral),降低部署门槛。
- 显著加速:在英伟达 H100 GPU 上,注意力计算速度最高提升 8 倍,提升推理效率。
- 数据无关性:无需针对特定数据集校准,适用于实时数据流和在线应用场景。
- 长上下文支持:在高达 10 万 token 的"大海捞针"测试中保持 99.7% 准确率,支持超长上下文推理。
- 理论最优性:数学证明其失真度接近任何量化算法的理论最小值,仅相差约 2.7 倍常数因子。
- 广泛适用:除 LLM 外,还可用于向量搜索引擎、推荐系统等高维向量压缩场景。
TurboQuant官网是什么
- 项目官网:https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
- arXiv技术论文:https://arxiv.org/pdf/2504.19874
TurboQuant的适用人群
- AI 推理服务提供商:需要降低大模型部署成本、提升推理吞吐量的云服务商和 MaaS 平台。
- 长上下文应用开发者:开发超长文档分析、多轮对话、代码理解等需要大上下文窗口的 AI 应用团队。
- 边缘设备部署工程师:在资源受限的边缘设备或移动端部署大模型的技术人员。
- 向量数据库/搜索引擎开发者:需要高效压缩高维向量以提升检索性能的向量检索系统开发者。
- 推荐算法工程师:处理大规模用户/物品嵌入向量、需要降低内存占用的推荐系统团队。
- AI 基础设施架构师:负责优化数据中心 GPU 利用率、降低 TCO 的企业技术决策者。
TurboQuant的常见问题FAQ
Q:TurboQuant 需要重新训练模型吗?
A:不需要。TurboQuant 可直接应用于现有模型(如 Gemma、Mistral),无需微调或重新训练,即插即用。
Q:TurboQuant 会影响模型精度吗?
A:在 3.5-bit 配置下实现绝对质量中性(零精度损失),2.5-bit 配置下仅边际性能下降,对大多数应用场景影响可忽略。
Q:TurboQuant 支持哪些硬件平台?
A:目前已在英伟达 H100 GPU 上验证,可实现最高 8 倍注意力计算加速,未来有望扩展至更多硬件平台。
Q:TurboQuant 适用于哪些模型?
A:适用于基于 Transformer 架构的大语言模型,包括 Gemma、Mistral 等主流开源模型,以及各类自研模型。
Q:TurboQuant 只能用于 LLM 吗?
A:不仅限于 LLM,还可用于向量搜索引擎、推荐系统、实时流处理等需要压缩高维向量的场景。
Q:TurboQuant 支持多长的上下文?
A:在高达 10 万 token 的"大海捞针"测试中保持 99.7% 准确率,支持超长上下文推理。
Q:TurboQuant 是开源的吗?
A:目前 Google 已发布研究论文,具体开源代码和工具包状态需关注官方后续公告。
Q:TurboQuant 与 DeepSeek 的压缩技术有何区别?
A:两者目标相似,但 TurboQuant 采用 PolarQuant 极坐标量化与 QJL 变换相结合的两阶段算法,在理论最优性和数据无关性方面具有独特优势。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...