

综合介绍
TPO-LLM-WebUI 是由 Airmomo 在 GitHub 上开源的一个创新项目,通过直观的 Web 界面实现大语言模型(LLM)的实时优化。它采用 TPO(Test-Time Prompt Optimization)框架,彻底告别传统微调的繁琐流程,无需训练即可直接优化模型输出。用户输入问题后,系统利用奖励模型和迭代反馈,让模型在推理过程中动态进化,越用越聪明,输出质量最高可提升50%。无论是技术文档润色还是安全响应生成,这个轻量高效的工具都能为开发者与研究人员提供强大支持。


功能列表
- 实时进化:通过推理阶段优化输出,越用越符合用户需求。
- 无需微调:不更新模型权重,直接提升生成质量。
- 多模型兼容:支持加载不同基础模型和奖励模型。
- 动态偏好对齐:根据奖励反馈调整输出,贴近人类期望。
- 推理可视化:展示优化迭代过程,便于理解和调试。
- 轻量高效:计算成本低,部署简单。
- 开源灵活:提供源代码,支持用户自定义开发。
使用帮助
安装流程
TPO-LLM-WebUI 的部署需要一些基础环境配置。以下是详细步骤,帮助用户快速上手。
1. 准备环境
确保以下工具已安装:
- Python 3.10:核心运行环境。
- Git:用于获取项目代码。
- GPU(推荐):NVIDIA GPU 可加速推理。
创建虚拟环境:
使用 Condi:
conda create -n tpo python=3.10
conda activate tpo
或 Python 自带工具:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
下载并安装依赖:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
安装 TextGrad:
TPO 依赖 TextGrad,需额外安装:
cd textgrad-main
pip install -e .
cd ..
2. 配置模型
需要手动下载基础模型和奖励模型:
- 基础模型:如
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(Hugging Face)。 - 奖励模型:如
sfairXC/FsfairX-LLaMA3-RM-v0.1(Hugging Face)。
将模型放入指定目录(如/model/HuggingFace/),并在config.yaml中设置路径。
3. 启动 vLLM 服务
使用 vLLM 托管基础模型。以 2 个 GPU 为例:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
服务运行后,监听 http://127.0.0.1:8000。
4. 运行 WebUI
在新终端中启动 Web 界面:
python gradio_app.py
浏览器访问 http://127.0.0.1:7860,即可使用。
主要功能操作流程
功能1:模型初始化
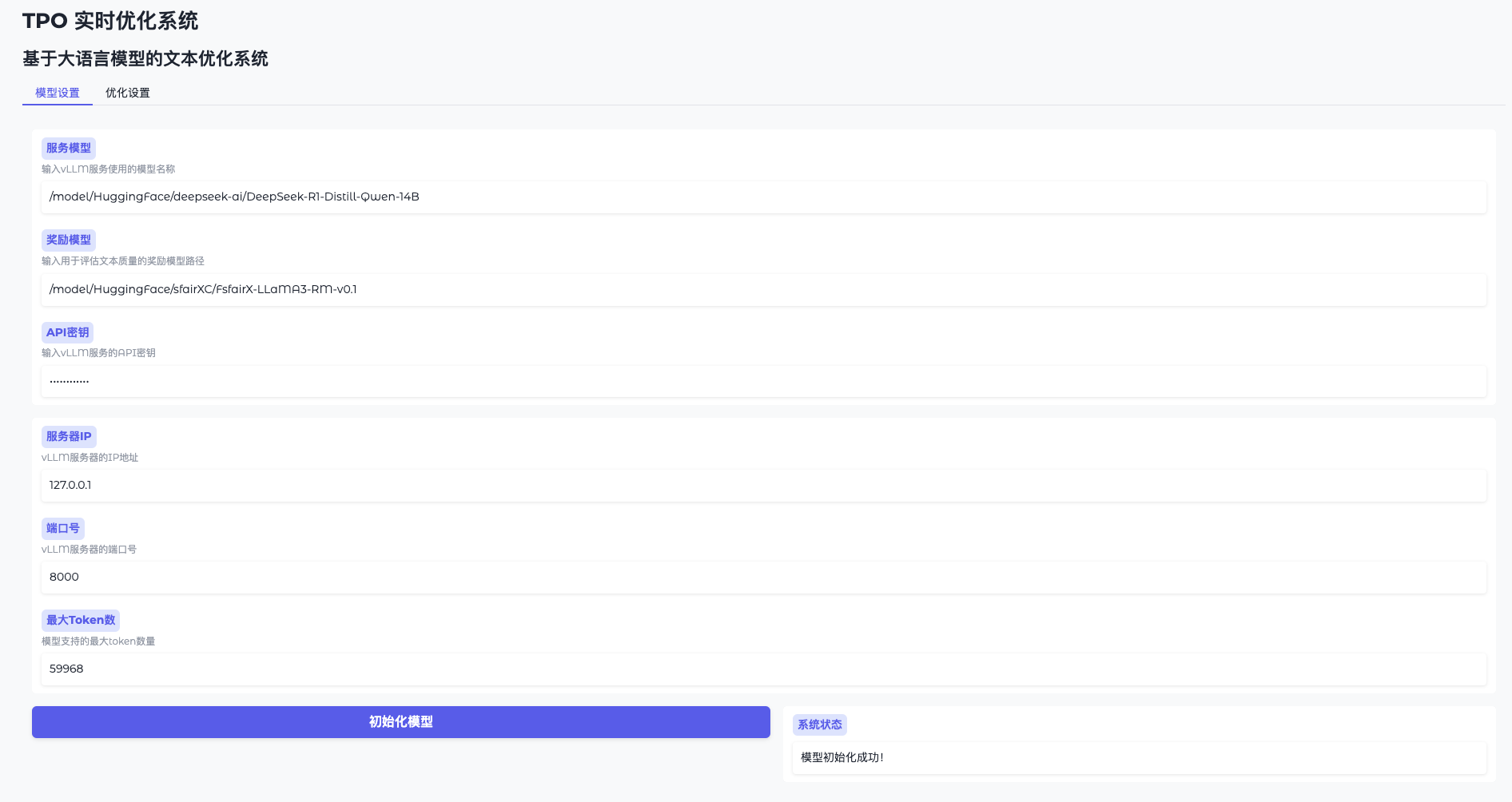
- 打开模型设置
进入 WebUI,点击“模型设置”。 - 连接 vLLM
输入地址(如http://127.0.0.1:8000)和密钥(token-abc123)。 - 加载奖励模型
指定路径(如/model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1),点击“初始化”,等待 1-2 分钟。 - 确认就绪
界面提示“模型已就绪”后可继续。
功能2:实时优化输出
- 切换优化页面
进入“优化设置”。 - 输入问题
输入内容,如“润色这篇技术文档”。 - 运行优化
点击“开始优化”,系统生成多个候选结果并迭代改进。 - 查看进化过程
结果页面展示初始与优化后的输出,质量逐步提升。
功能3:脚本模式优化
若不使用 WebUI,可运行脚本:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
优化结果保存至 logs/ 文件夹。
特色功能详细说明
告别微调,实时进化
- 操作步骤:
- 输入问题,系统生成初始回答。
- 奖励模型评估并反馈,指导下一次迭代。
- 多次迭代后,输出逐渐“聪明”,质量提升显著。
- 优势:无需训练,随时优化,节省时间与算力。
越用越聪明
- 操作步骤:
- 多次使用同一模型,输入不同问题。
- 系统根据每次反馈积累经验,输出更贴合需求。
- 优势:动态学习用户偏好,长期使用效果更佳。
注意事项
- 硬件要求:推荐 16GB 以上显存,多 GPU 需确保资源空闲,可用
export CUDA_VISIBLE_DEVICES=2,3指定。 - 问题解决:显存溢出时,降低
sample_size或检查 GPU 占用。 - 社区支持:参考 GitHub README 或 Issues 获取帮助。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...