
综合介绍
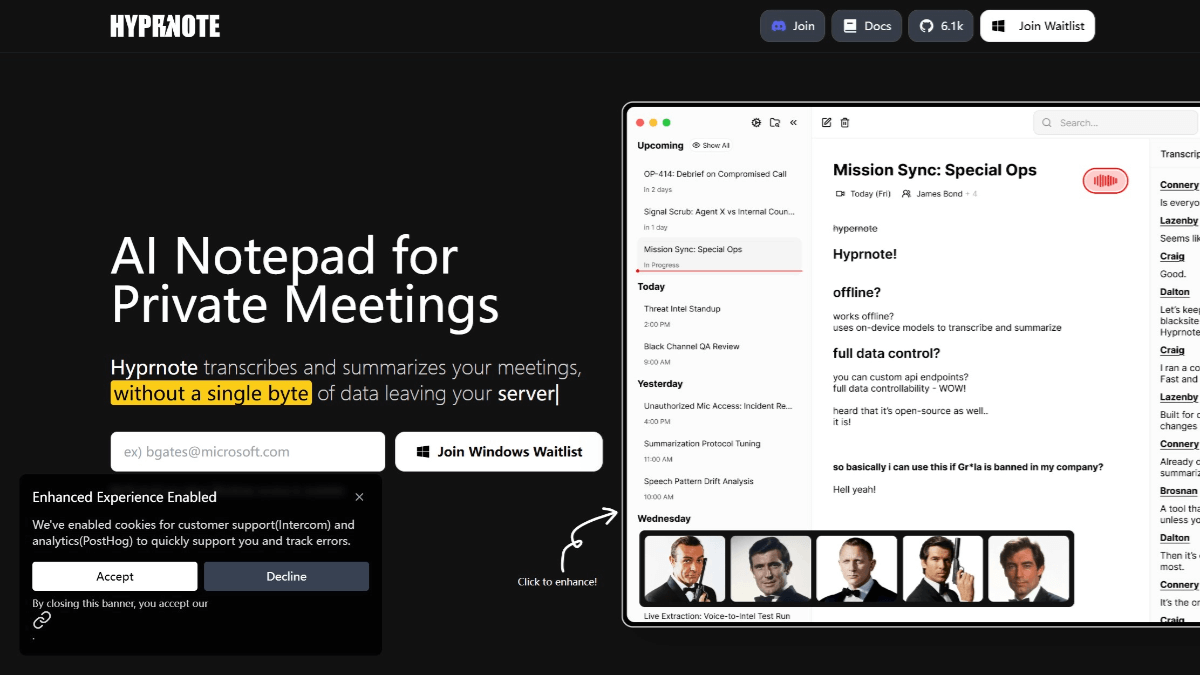
Surya是一个开源的多语言文档OCR工具包,支持90多种语言的文本识别。它不仅能够进行逐行文本检测,还能进行布局分析、阅读顺序检测和表格识别。Surya的性能与云服务相媲美,适用于各种类型的文档,包括PDF、图像、Word文档和PPT等。该工具包旨在为用户提供全面的文档解析解决方案。
托管API:https://www.datalab.to/
适用于 PDF、图像、Word 文档和 PowerPoint

功能列表
- OCR:支持90多种语言的文本识别
- 逐行文本检测:自动识别文档中每一行文字的位置
- 布局分析:检测文档中的表格、图像、标题等元素
- 阅读顺序检测:识别文档中的阅读顺序
- 表格识别:检测表格中的行和列
使用帮助
安装流程
- 确保已安装Python 3.9+和PyTorch。
- 如果不是使用Mac或GPU机器,可能需要先安装CPU版本的torch。
- 使用以下命令安装Surya:
pip install surya-ocr - 第一次运行Surya时,模型权重会自动下载。
使用流程
- 检查并配置
surya/settings.py中的设置,可以通过环境变量覆盖任何设置。 - Surya会自动检测torch设备,但可以手动覆盖。例如:
TORCH_DEVICE=cuda - 使用以下命令运行OCR应用:
python run_ocr_app.py - 处理文档时,可以选择不同的功能模块,如文本检测、布局分析等。
功能操作流程
- OCR功能:
- 加载文档(PDF、图像等)。
- 选择语言(支持90多种语言)。
- 运行OCR识别,提取文本内容。
- 逐行文本检测:
- 加载文档。
- 运行逐行文本检测,获取每一行文字的位置。
- 导出检测结果。
- 布局分析:
- 加载文档。
- 运行布局分析,检测文档中的表格、图像、标题等元素。
- 导出分析结果。
- 阅读顺序检测:
- 加载文档。
- 运行阅读顺序检测,识别文档中的阅读顺序。
- 导出检测结果。
- 表格识别:
- 加载文档。
- 运行表格识别,检测表格中的行和列。
- 导出识别结果。
Surya提供了丰富的文档解析功能,用户可以根据需求选择不同的功能模块进行操作。详细的操作流程和设置说明可以参考官方文档和示例代码。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
Related posts


暂无评论...