
GPUStack 是一个开源的大模型即服务平台,可以高效整合并利用 Nvidia、Apple Metal、华为昇腾和摩尔线程等各种异构的 GPU/NPU 资源,提供本地私有部署大模型解决方案。
GPUStack 可以支持 RAG 系统中所需要的三种关键模型:Chat 对话模型(大语言模型)、Embedding 文本嵌入模型和 Rerank 重排序模型三件套,只需要非常简单的傻瓜化操作就能部署 RAG 系统所需要的本地私有模型。
下面介绍如何安装 GPUStack 和 Dify,并使用 Dify 来对接 GPUStack 部署的对话模型、Embedding 模型和 Reranker 模型。
安装 GPUStack
在 Linux 或 macOS 上通过以下命令在线安装,在安装过程中需要输入 sudo 密码: curl -sfL https://get.gpustack.ai | sh -
如果环境连接不了 GitHub,无法下载一些二进制文件,使用以下命令安装,用 --tools-download-base-url 参数指定从腾讯云对象存储下载:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
在 Windows 上以管理员身份运行 Powershell,通过以下命令在线安装:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
如果环境连接不了 GitHub,无法下载一些二进制文件,使用以下命令安装,用 --tools-download-base-url 参数指定从腾讯云对象存储下载:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
当看到以下输出时,说明已经成功部署并启动了 GPUStack:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
接下来按照脚本输出的指引,拿到登录 GPUStack 的初始密码,执行以下命令:
在 Linux 或 macOS 上:cat /var/lib/gpustack/initial_admin_password
在 Windows 上:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
在浏览器访问 GPUStack UI,用户名 admin,密码为上面获得的初始密码。
重新设置密码后,进入 GPUStack: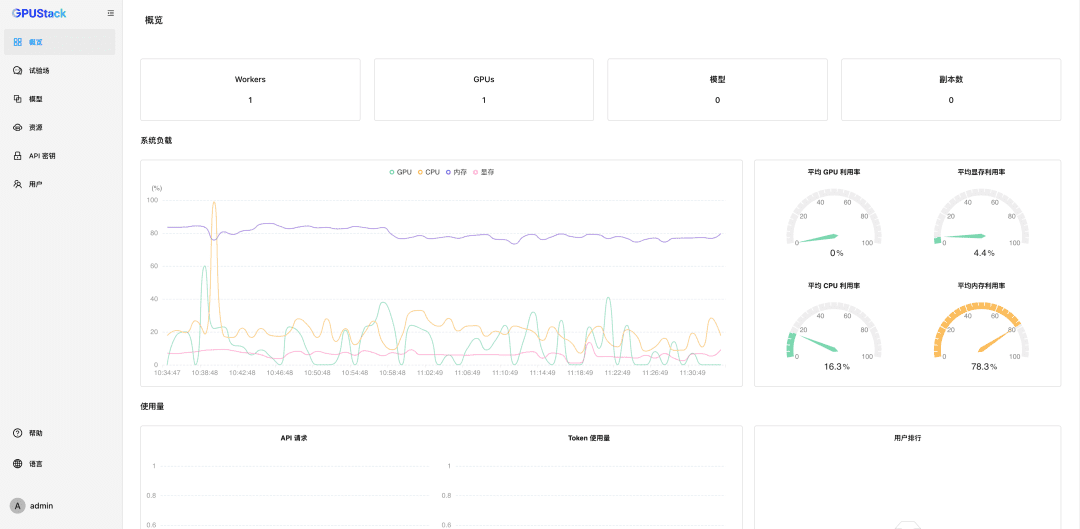
纳管 GPU 资源
GPUStack 支持 Linux、Windows 和 macOS 设备的 GPU 资源,通过以下步骤来纳管这些 GPU 资源。
其他节点需要通过认证 Token 加入 GPUStack 集群,在 GPUStack Server 节点执行以下命令获取 Token:
在 Linux 或 macOS 上:cat /var/lib/gpustack/token
在 Windows 上:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
拿到 Token 后,在其他节点上运行以下命令添加 Worker 到 GPUStack,纳管这些节点的 GPU(将其中的 http://YOUR_IP_ADDRESS 替换为你的 GPUStack 访问地址,将 YOUR_TOKEN 替换为用于添加 Worker 的认证 Token):
在 Linux 或 macOS 上:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
在 Windows 上:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
通过以上步骤,我们已经创建了一个 GPUStack 环境并纳管了多个 GPU 节点,接下来可以使用这些 GPU 资源来部署私有大模型。
部署私有大模型
访问 GPUStack,在 Models 菜单中部署模型。GPUStack 支持从 HuggingFace、Ollama Library、ModelScope 和私有模型仓库部署模型,国内网络建议从 ModelScope 部署。
GPUStack 支持 vLLM 和 llama-box 推理后端,vLLM 专门针对生产推理进行了优化,在并发和性能方面更能满足生产需求,但 vLLM 只支持 Linux 系统。llama-box 则是一个灵活、兼容多平台的推理引擎,是 llama.cpp 的优化版本,对性能和稳定性进行了针对性的优化,支持 Linux、Windows 和 macOS 系统,不止支持各种 GPU 环境,也支持在 CPU 环境运行大模型,更适合需要多平台兼容性的场景。
GPUStack 会在部署模型时自动根据模型文件的类型选择适当的推理后端,如果模型为 GGUF 格式,GPUStack 会使用 llama-box 作为后端运行模型服务,如果为非 GGUF 格式, GPUStack 会使用 vLLM 作为后端运行模型服务。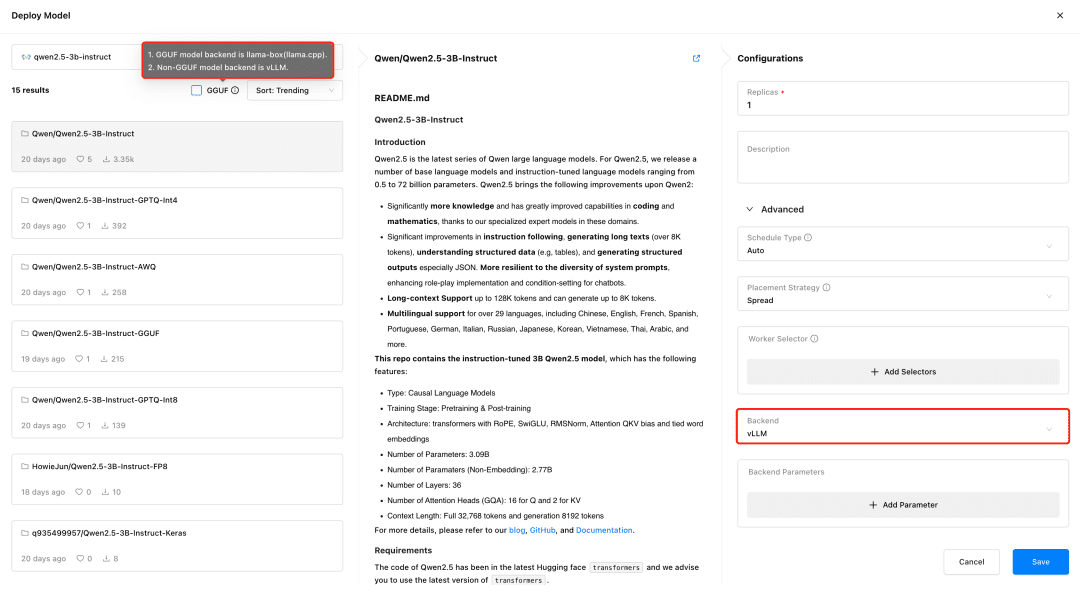
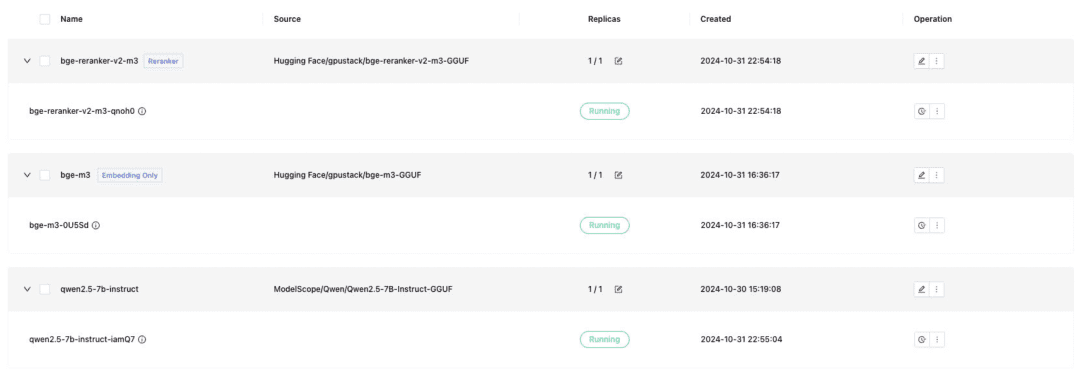
部署 Dify 对接所需要的文本对话模型、Embedding 文本嵌入模型、Reranker 模型,记得部署时勾选 GGUF 格式:
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
GPUStack 还支持 VLM 多模态模型,部署 VLM 多模态模型需要使用 vLLM 推理后端:
Qwen2-VL-2B-Instruct 

模型部署好后,RAG 系统或其他生成式 AI 应用可以通过 GPUStack 提供的 OpenAI / Jina 兼容 API 对接 GPUStack 部署的模型,接下来使用 Dify 来对接 GPUStack 部署的模型。
Dify 集成 GPUStack 模型
安装 Dify
采用 Docker 方式运行 Dify,需要准备好 Docker 环境,注意避免 Dify 和 GPUStack 的 80 端口冲突,使用其他主机或修改端口。执行以下命令安装 Dify:git clone -b 0.10.1 https://github.com/langgenius/dify.git访问 Dify 的 UI 界面 http://localhost,初始化管理员账户并登录。
cd dify/docker/
cp .env.example .env
docker compose up -d
集成 GPUStack 模型首先添加 Chat 对话模型,在 Dify 右上角选择“设置-模型供应商”,在列表中找到 GPUStack 类型,选择添加模型:
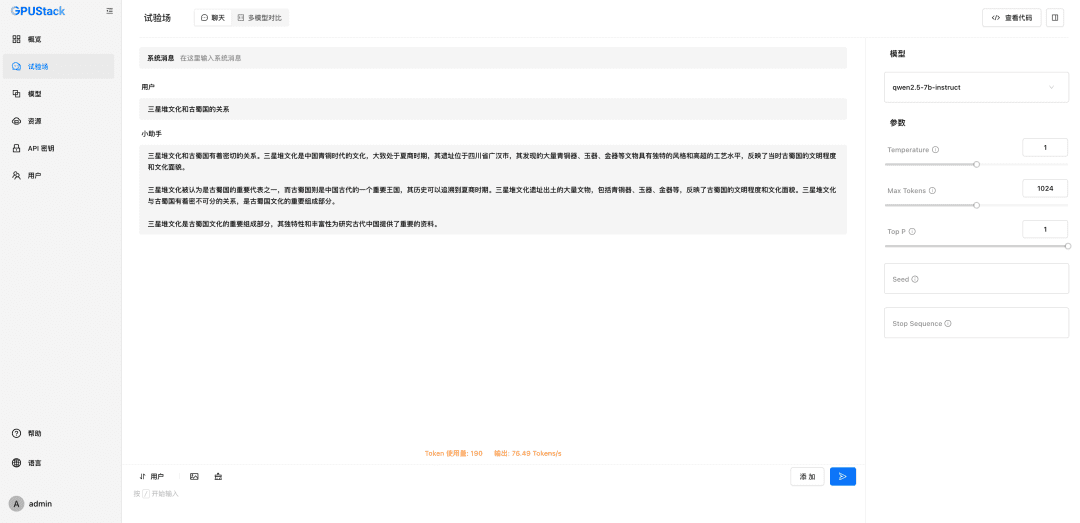
填写 GPUStack 上部署的 LLM 模型名称(例如 qwen2.5-7b-instruct)、GPUStack 的访问地址(例如 http://192.168.0.111)和生成的 API Key,还有模型设置的上下文长度 8192 和 max tokens 2048: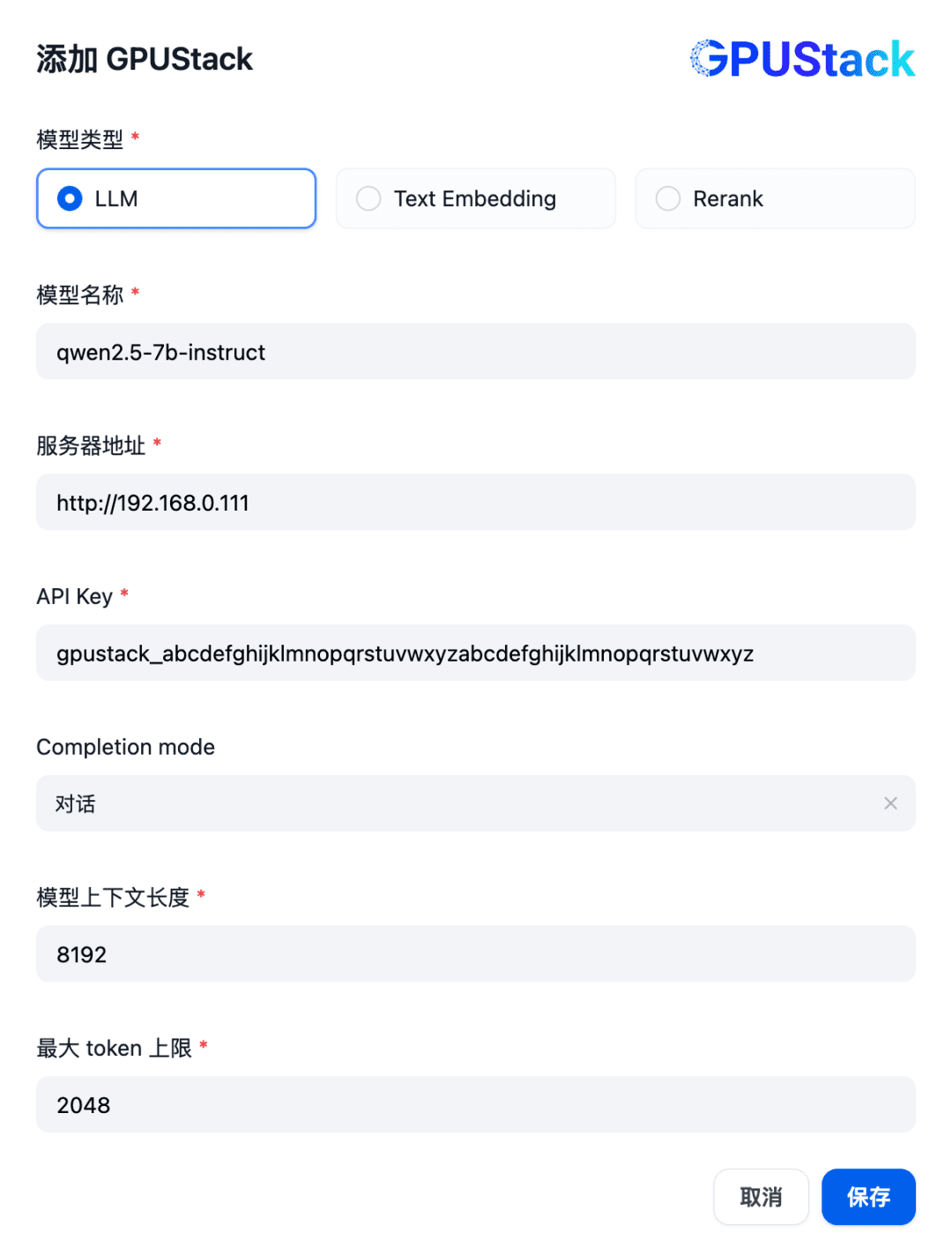
接下来添加 Embedding 模型,在模型供应商的最上方继续选择 GPUStack 类型,选择添加模型: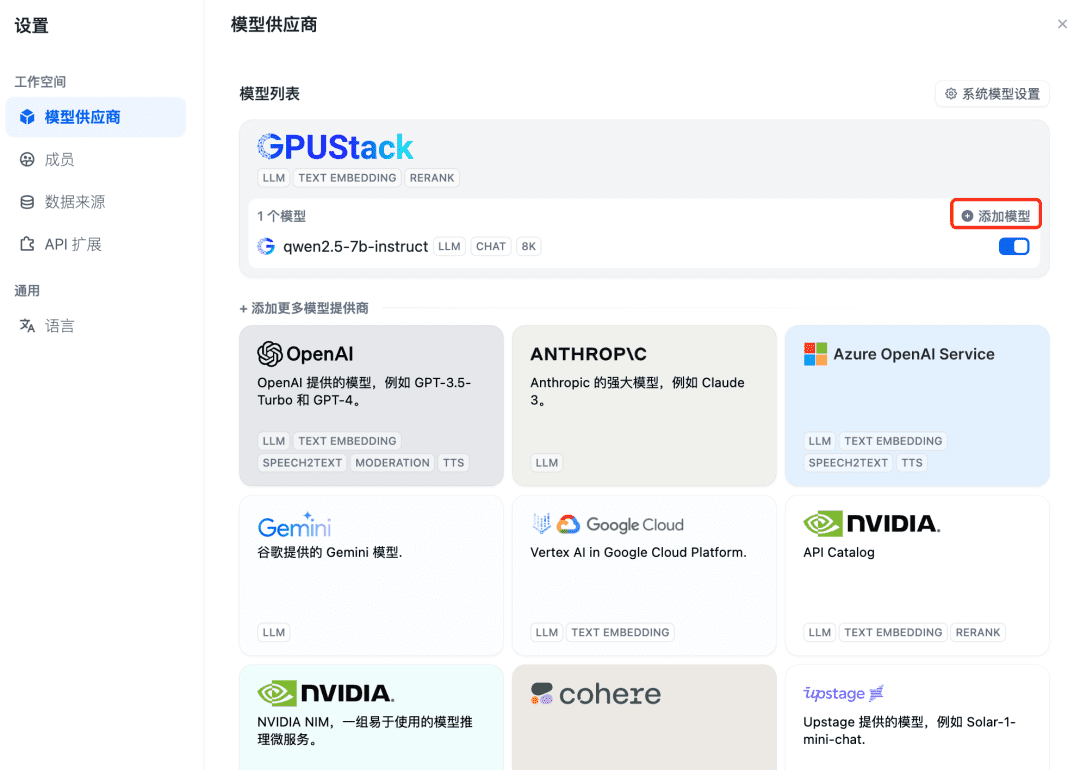
添加 Text Embedding 类型的模型,填写 GPUStack 上部署的 Embedding 模型名称(例如 bge-m3)、GPUStack 的访问地址(例如 http://192.168.0.111)和生成的 API Key,还有模型设置的上下文长度 8192: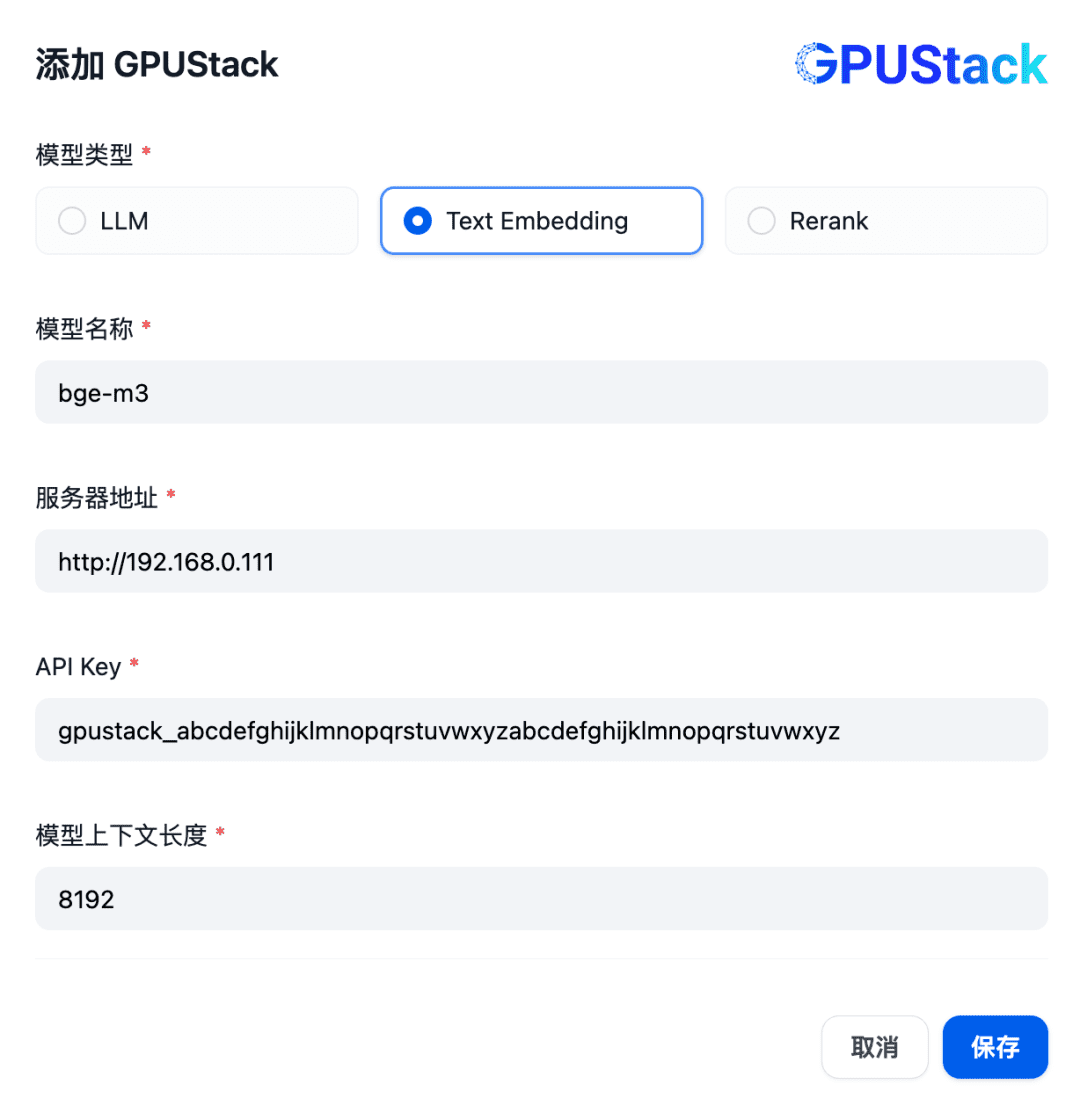
接下来添加 Rerank 模型,继续选择 GPUStack 类型,选择添加模型,添加 Rerank 类型的模型,填写 GPUStack 上部署的 Rerank 模型名称(例如 bge-reranker-v2-m3)、GPUStack 的访问地址(例如 http://192.168.0.111)和生成的 API Key,还有模型设置的上下文长度 8192: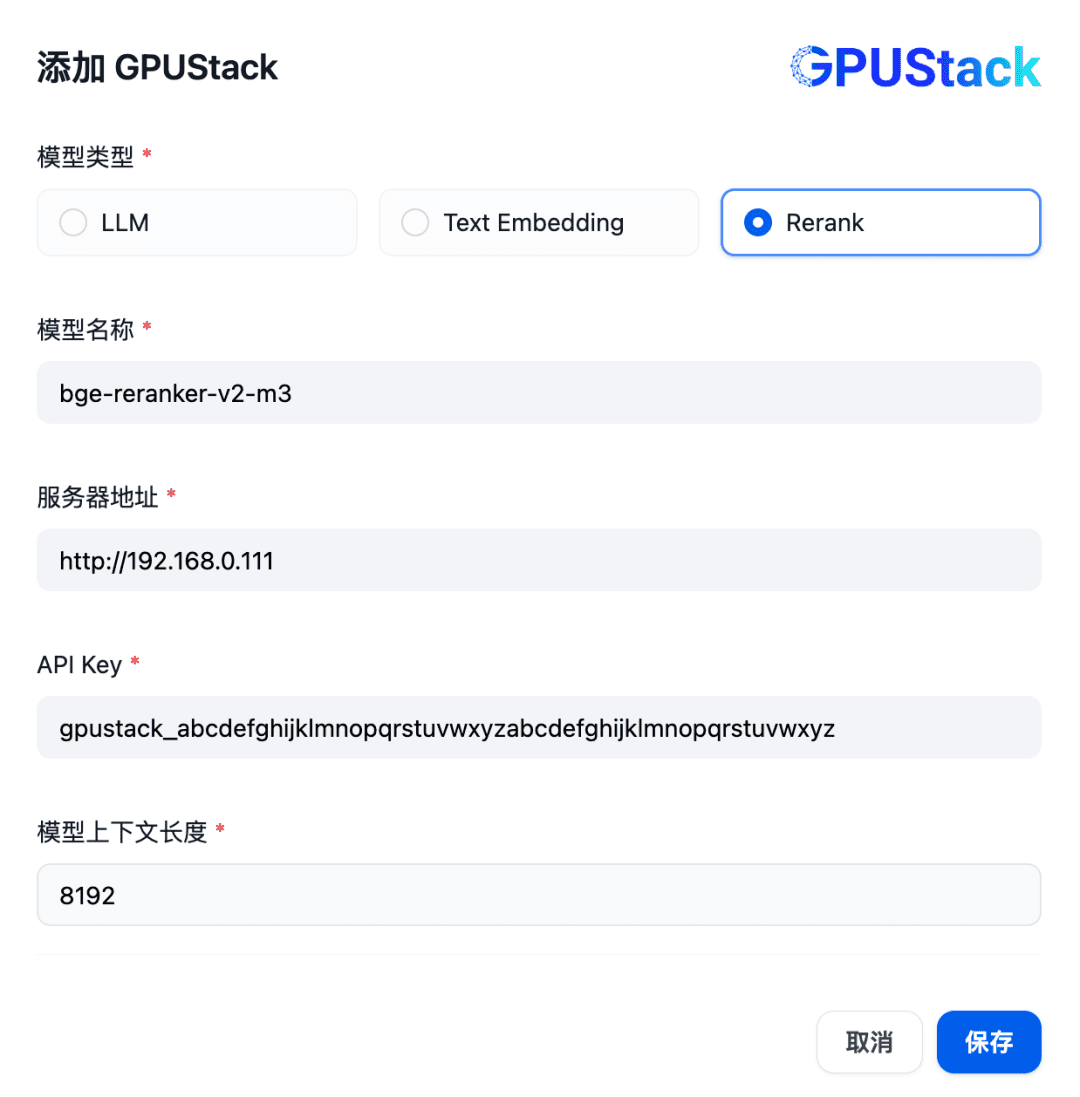
添加后重新刷新,然后在模型供应商确认系统模型配置为上面添加的三个模型: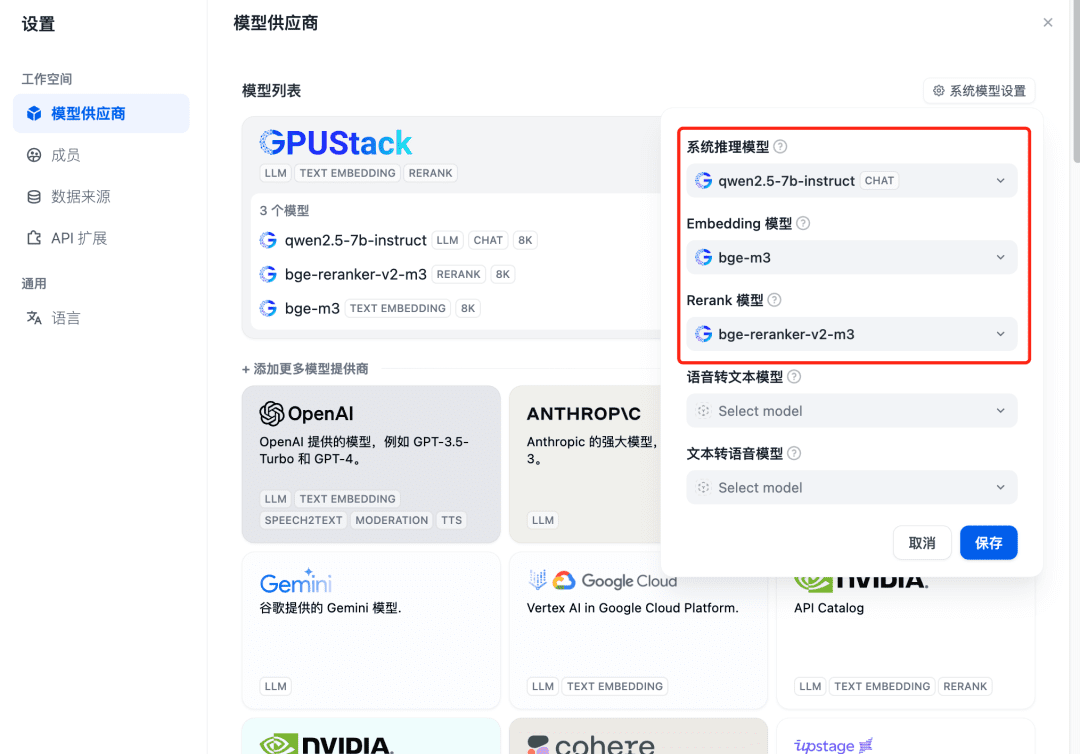
在 RAG 系统使用模型选择 Dfiy 的知识库,选择创建知识库,导入一个文本文件,确认 Embedding 模型选项,检索设置使用推荐的混合检索,并开启 Rerank 模型: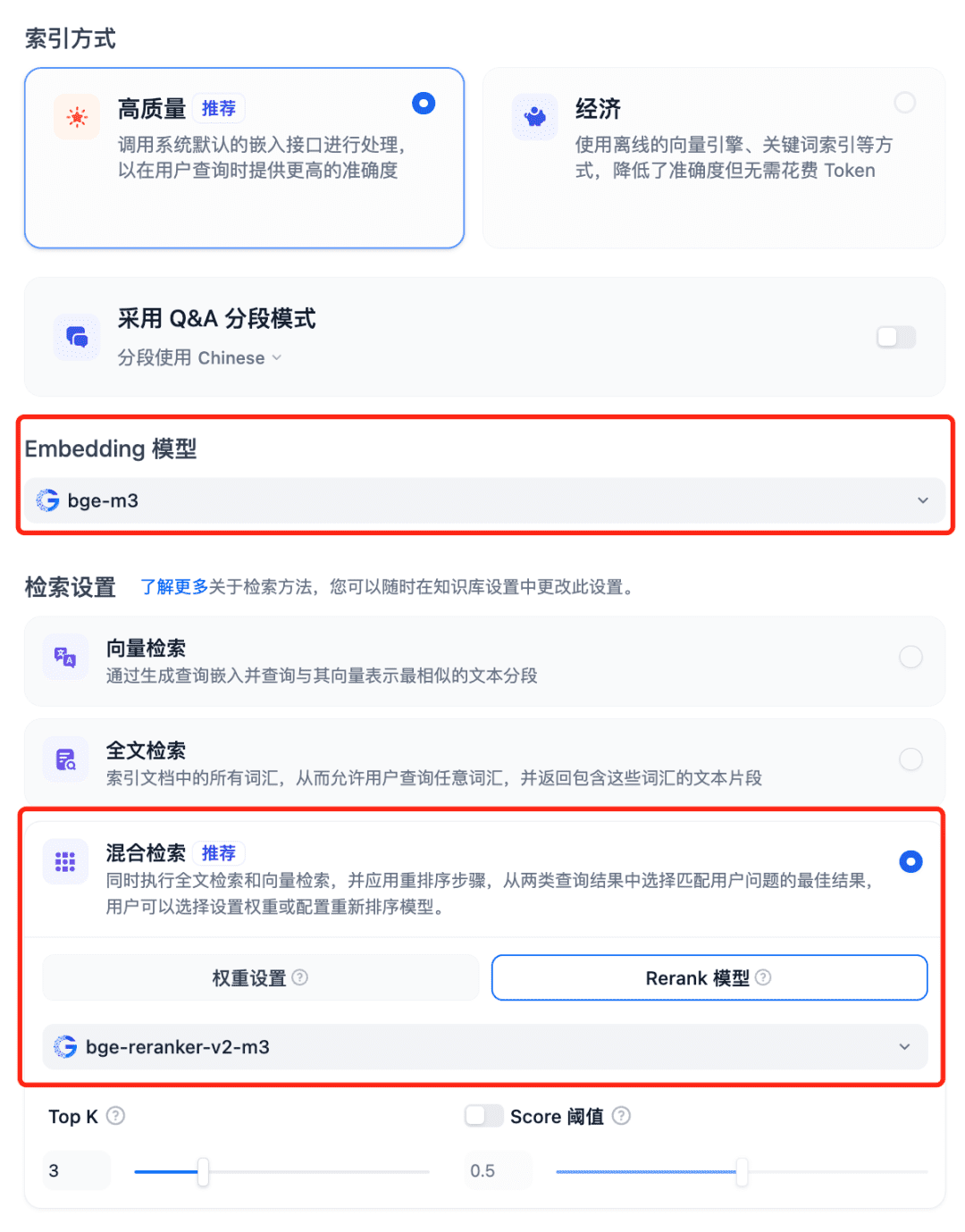
保存,开始将文档进行向量化过程,向量化完成后,知识库即可以使用了。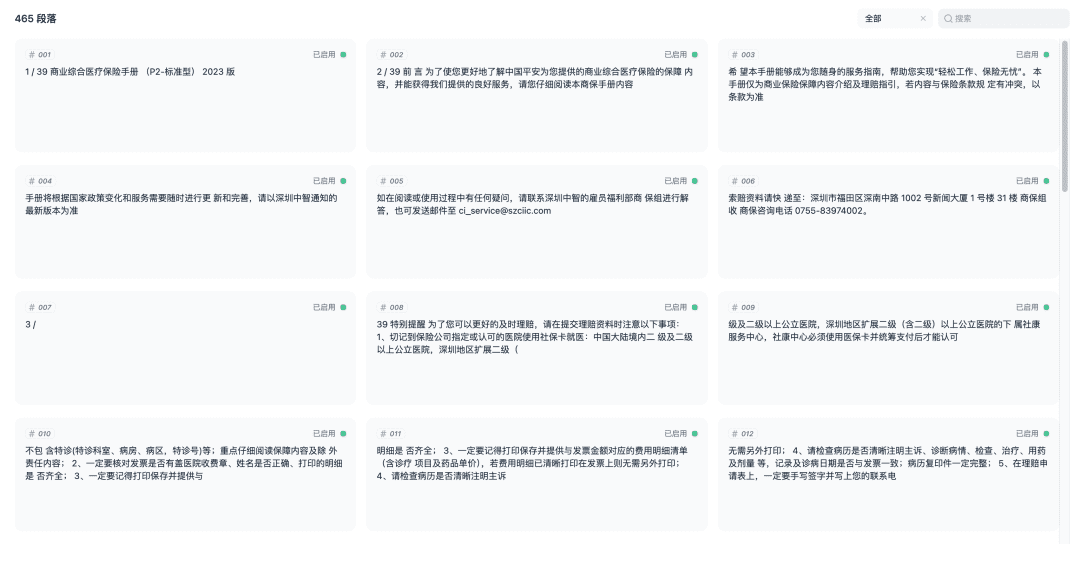
可以通过召回测试确认知识库的召回效果,Rerank 模型将进行精排以召回更有相关性的文档,以达到更好的召回效果: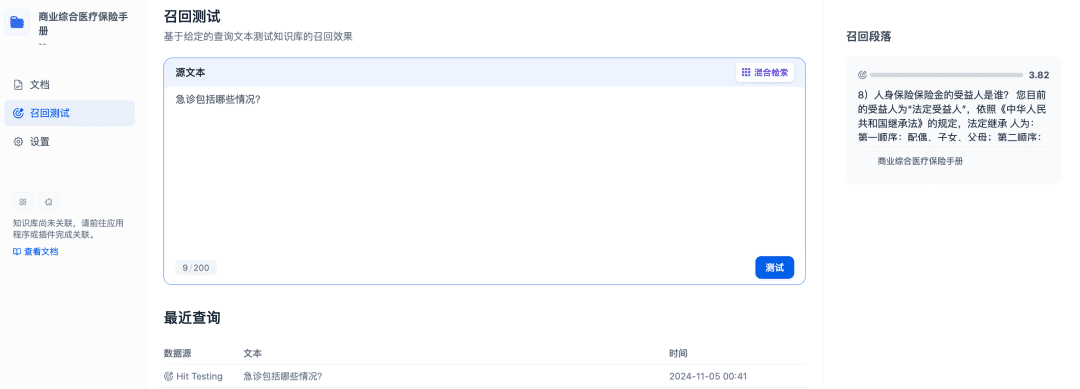
接下来在聊天室创建一个聊天助手应用: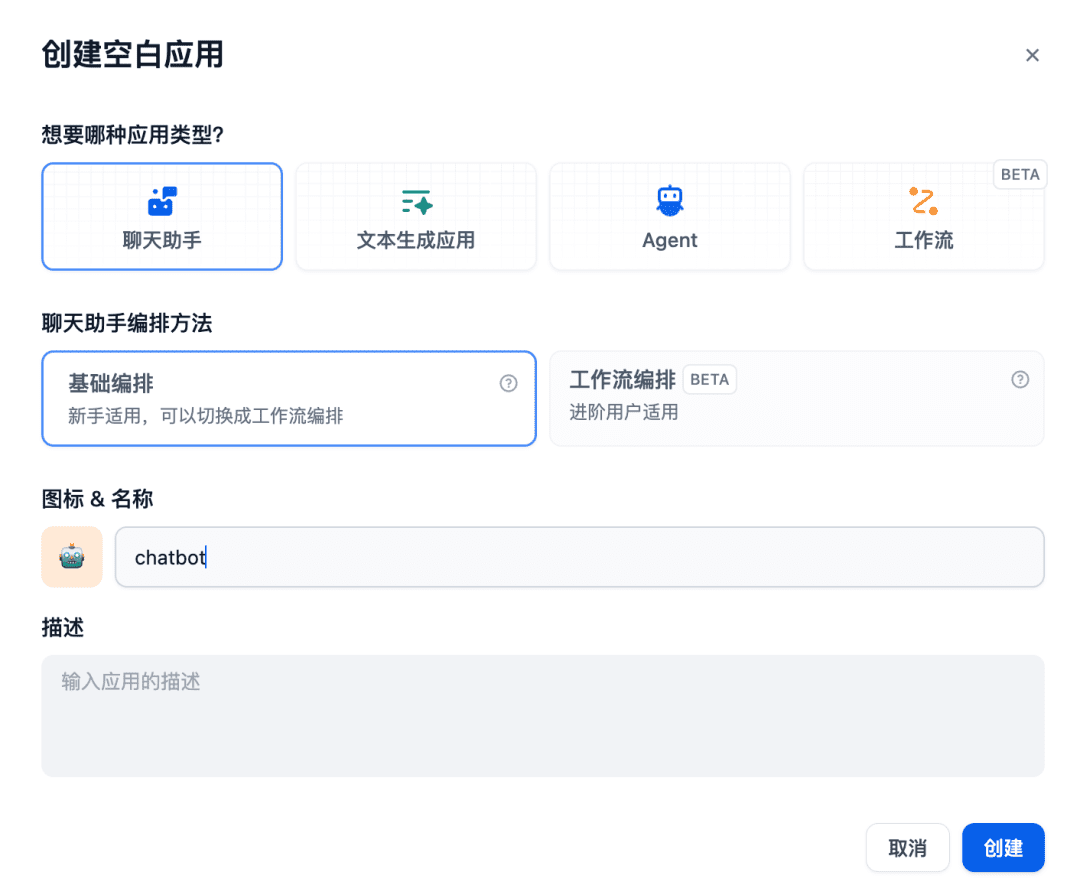
在上下文中添加相关知识库即可使用,此时 Chat 模型、Embedding 模型和 Reranker 模型将共同为 RAG 应用提供支撑,Embedding 模型负责向量化、 Reranker 模型负责对召回的内容进行精排,Chat 模型负责根据问题和召回的上下文内容进行回答: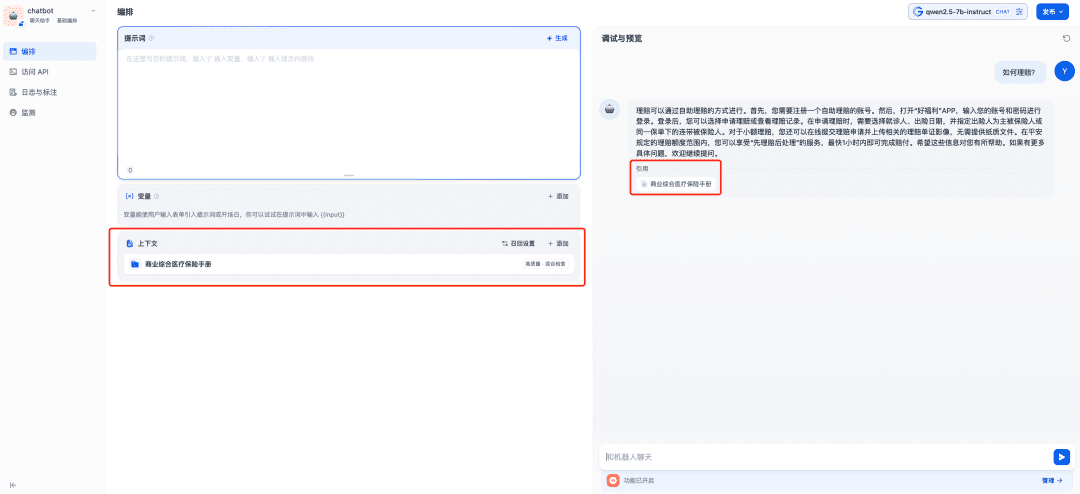
以上为使用 Dify 对接 GPUStack 模型的示例,其他 RAG 系统也可以通过 OpenAI / Jina 兼容 API 对接 GPUStack,即可利用 GPUStack 平台部署的各种 Chat 模型、Embedding 模型和 Reranker 模型来支撑 RAG 系统。
以下为 GPUStack 功能的简单介绍。
GPUStack 功能介绍
- 异构 GPU 支持:支持异构 GPU 资源,当前支持 Nvidia、Apple Metal、华为昇腾和摩尔线程等各种类型的 GPU/NPU
- 多推理后端支持:支持 vLLM 和 llama-box (llama.cpp) 推理后端,兼顾生产性能需求与多平台兼容性需求
- 多平台支持:支持 Linux、Windows 和 macOS 平台,覆盖 amd64 和 arm64 架构
- 多模型类型支持:支持 LLM 文本模型、VLM 多模态模型、Embedding 文本嵌入模型 和 Reranker 重排序模型等各种类型的模型
- 多模型仓库支持:支持从 HuggingFace、Ollama Library、ModelScope 和私有模型仓库部署模型
- 丰富的自动/手动调度策略:支持紧凑调度、分散调度、指定 Worker 标签调度、指定 GPU 调度等各种调度策略
- 分布式推理:如果单个 GPU 无法运行较大的模型,可以通过 GPUStack 的分布式推理功能,自动将模型运行在跨主机的多个 GPU 上
- CPU 推理:如果没有 GPU 或 GPU 资源不足,GPUStack 可以用 CPU 资源来运行大模型,支持 GPU&CPU 混合推理和纯 CPU 推理两种 CPU 推理模式
- 多模型对比:GPUStack 在 Playground 中提供了多模型对比视图,可以同时对比多个模型的问答内容和性能数据,以评估不同模型、不同权重、不同 Prompt 参数、不同量化、不同 GPU、不同推理后端的模型 Serving 效果
- GPU 和 LLM 观测指标:提供全面的性能、利用率、状态监控和使用数据指标,以评估 GPU 和 LLM 的利用情况
GPUStack 提供了建设一个私有大模型即服务平台所需要的各项企业级功能,作为一个开源项目,只需要非常简单的安装设置,就可以开箱即用地构建企业私有大模型即服务平台。
总结
以上为安装 GPUStack 和使用 Dify 集成 GPUStack 模型的配置教程,项目的开源地址为:https://github.com/gpustack/gpustack。
GPUStack 作为一个低门槛、易上手、开箱即用的开源平台,可以帮助企业快速整合和利用异构 GPU 资源,在短时间内快速搭建起一个企业级的私有大模型即服务平台。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...