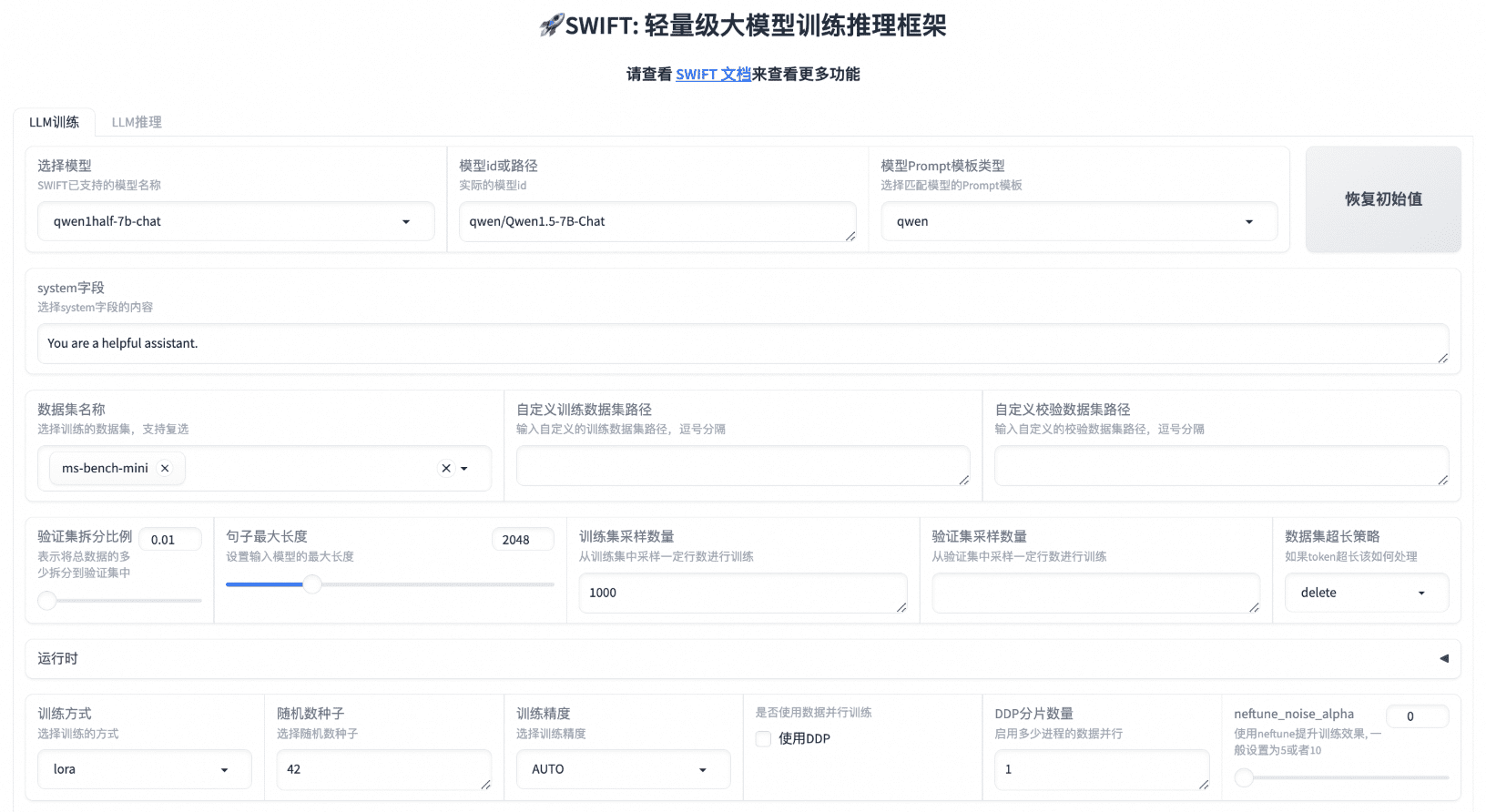
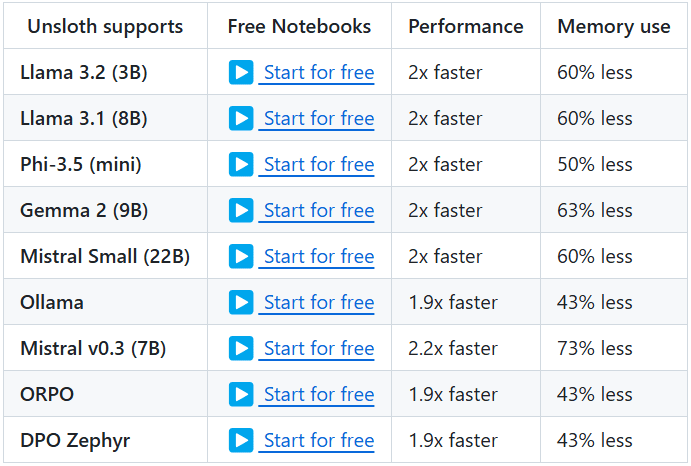
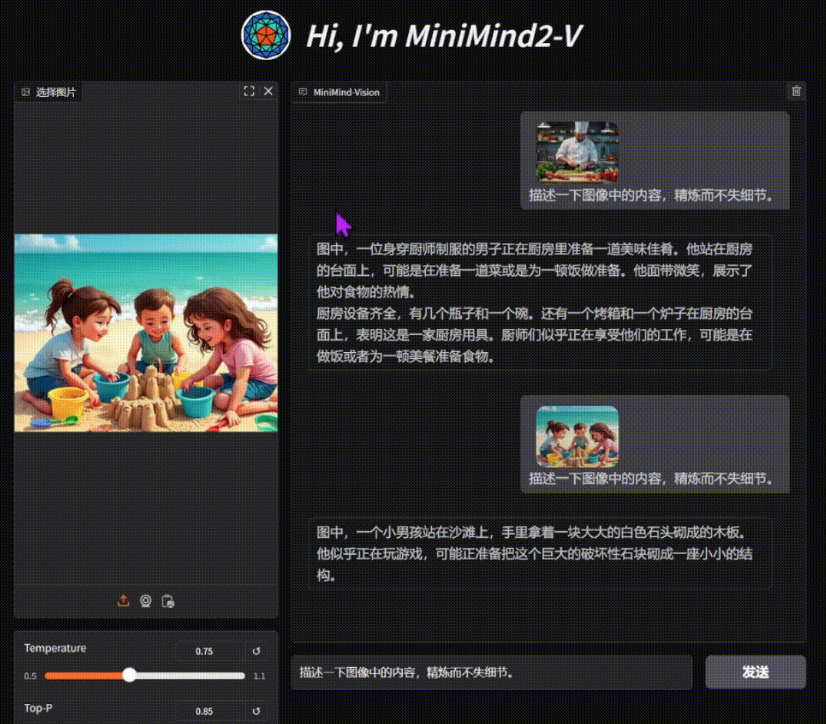
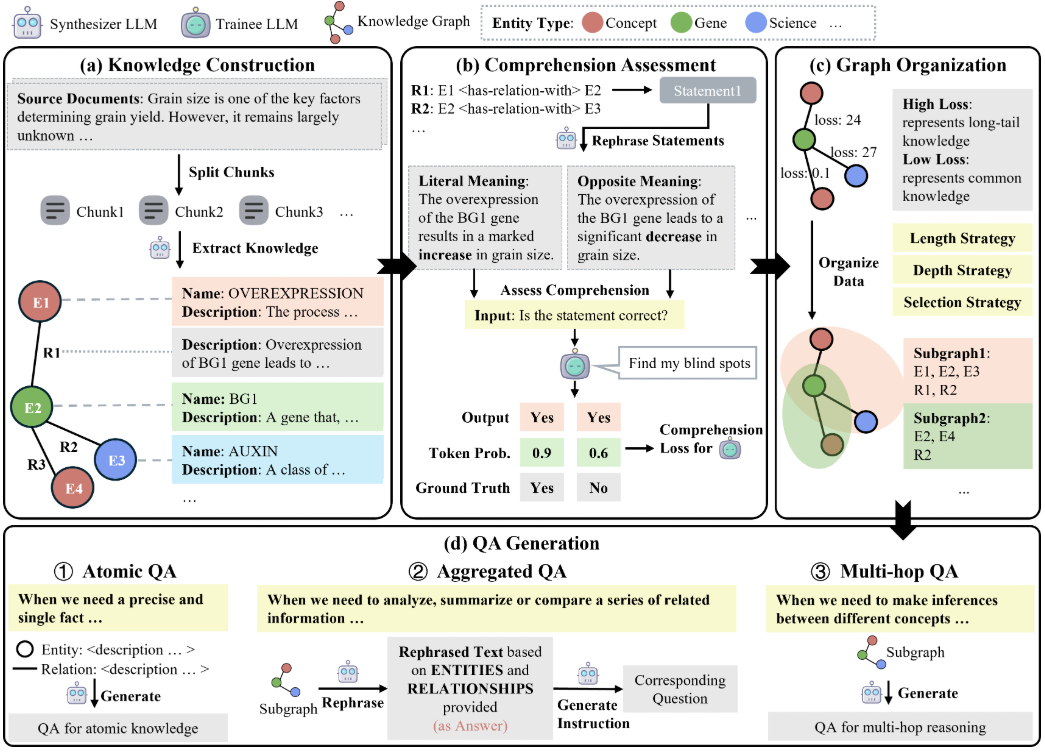
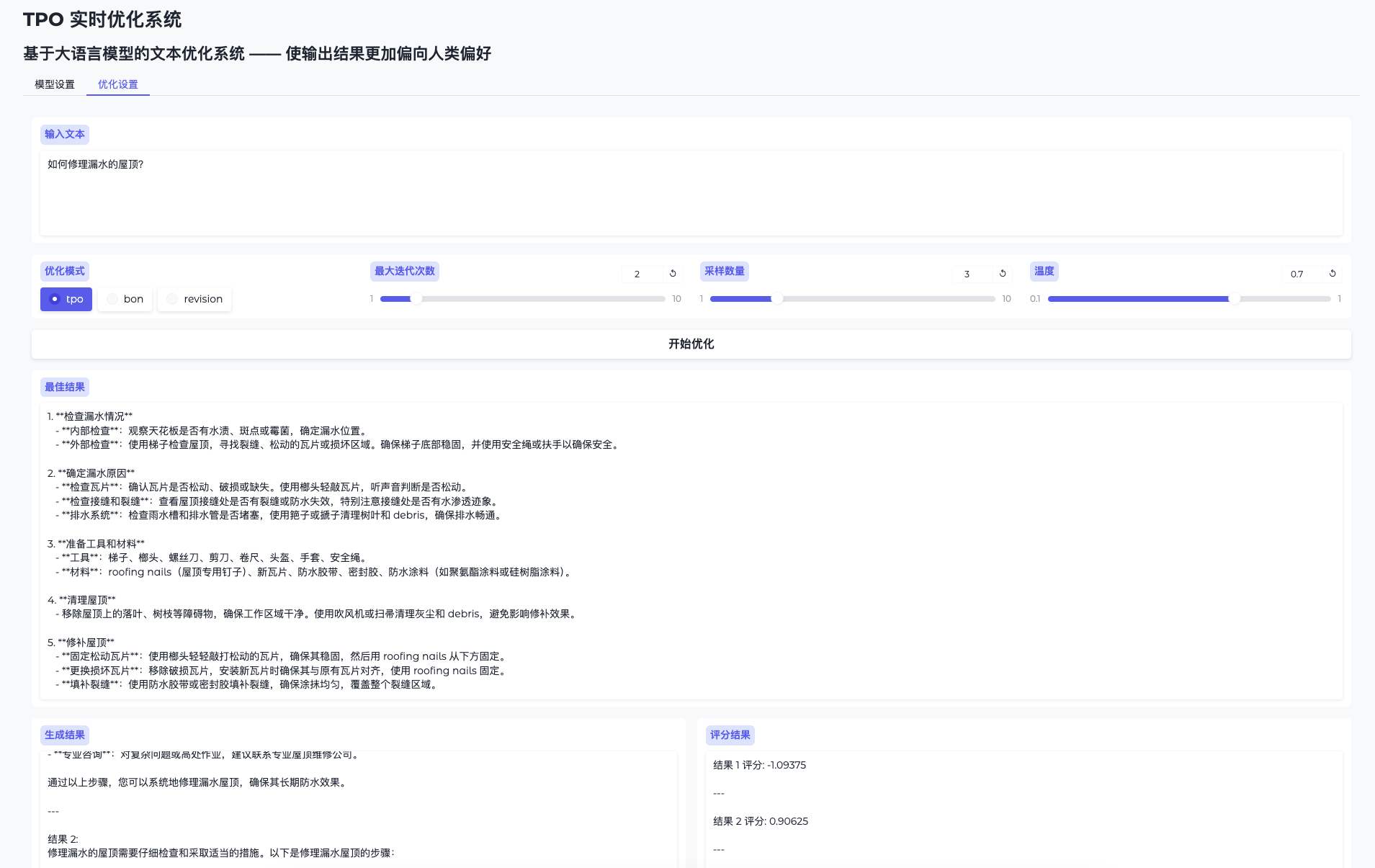
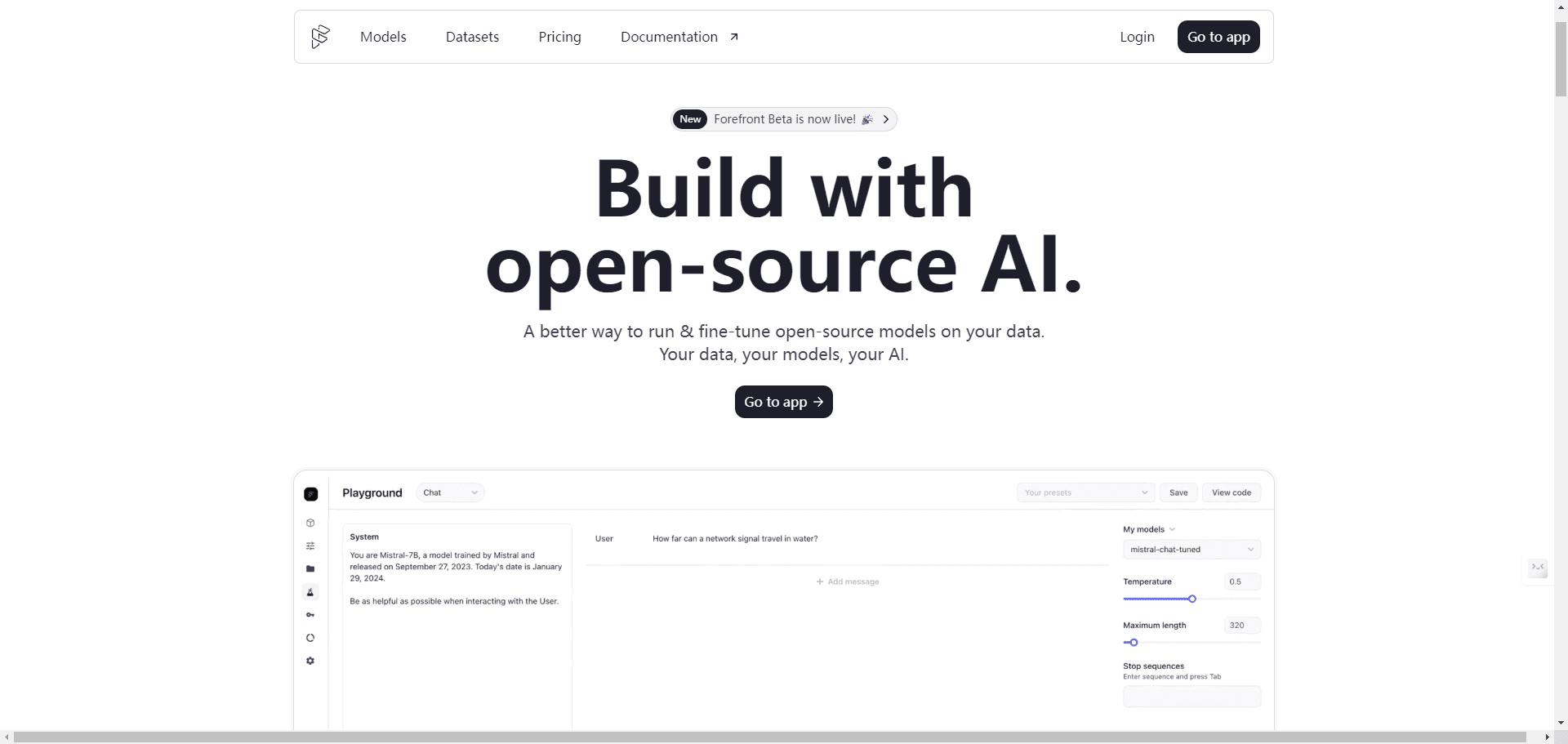
AI Toolkit by Ostris: Стабильная диффузия с FLUX.1 Model Training Toolkit
Общее представление AI Toolkit by Ostris - это набор инструментов ИИ с открытым исходным кодом, ориентированный на поддержку моделей Stable Diffusion и FLUX.1 для задач обучения и генерации изображений. Инструментарий создан и поддерживается разработчиком Ostris, тор...