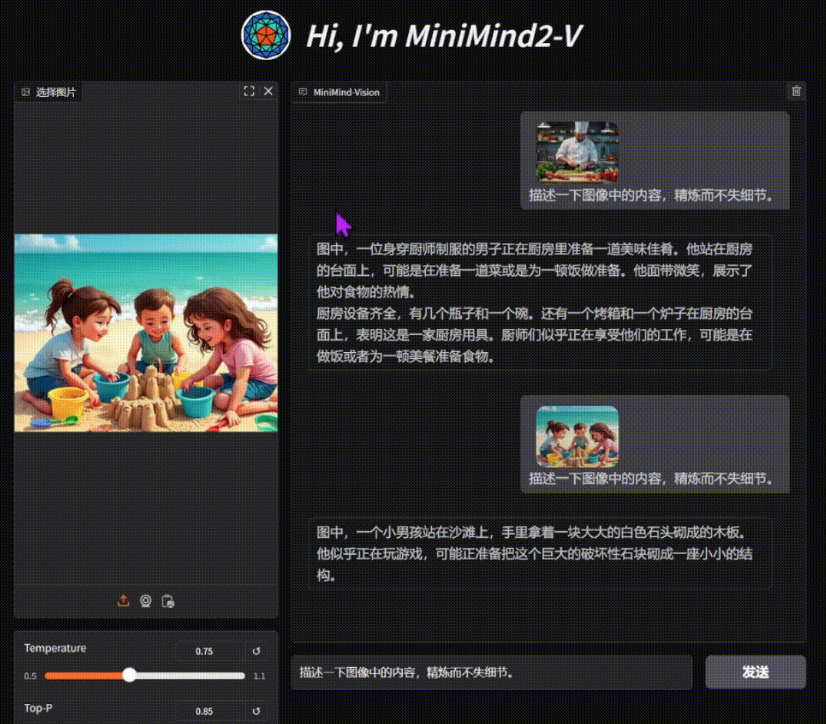
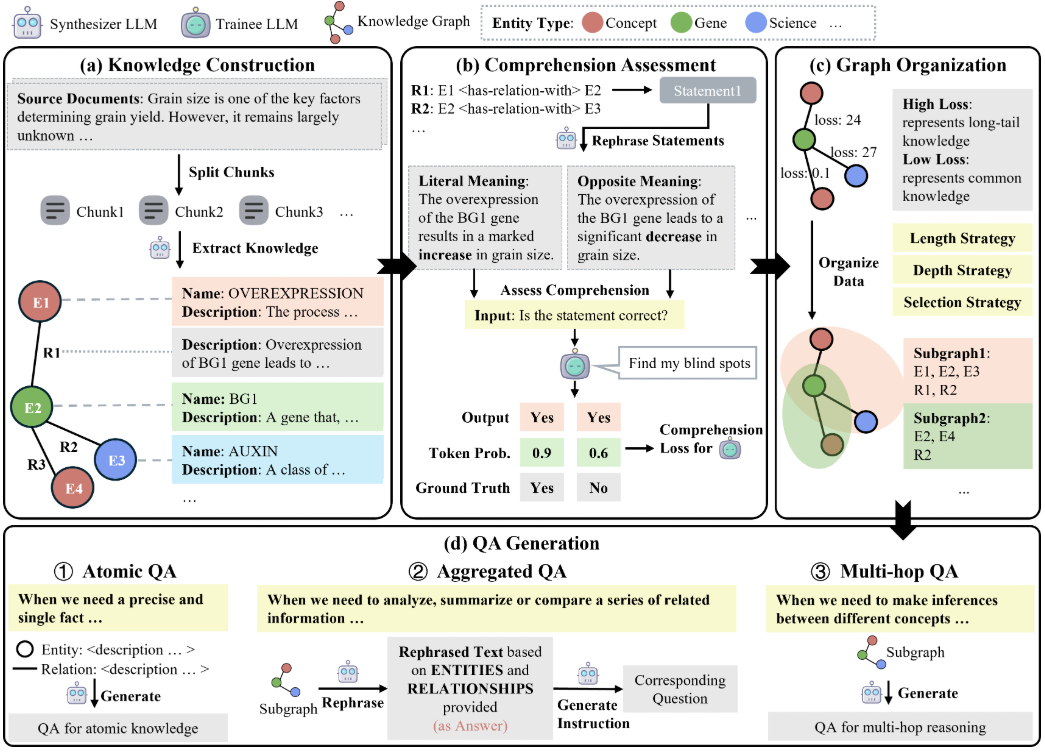
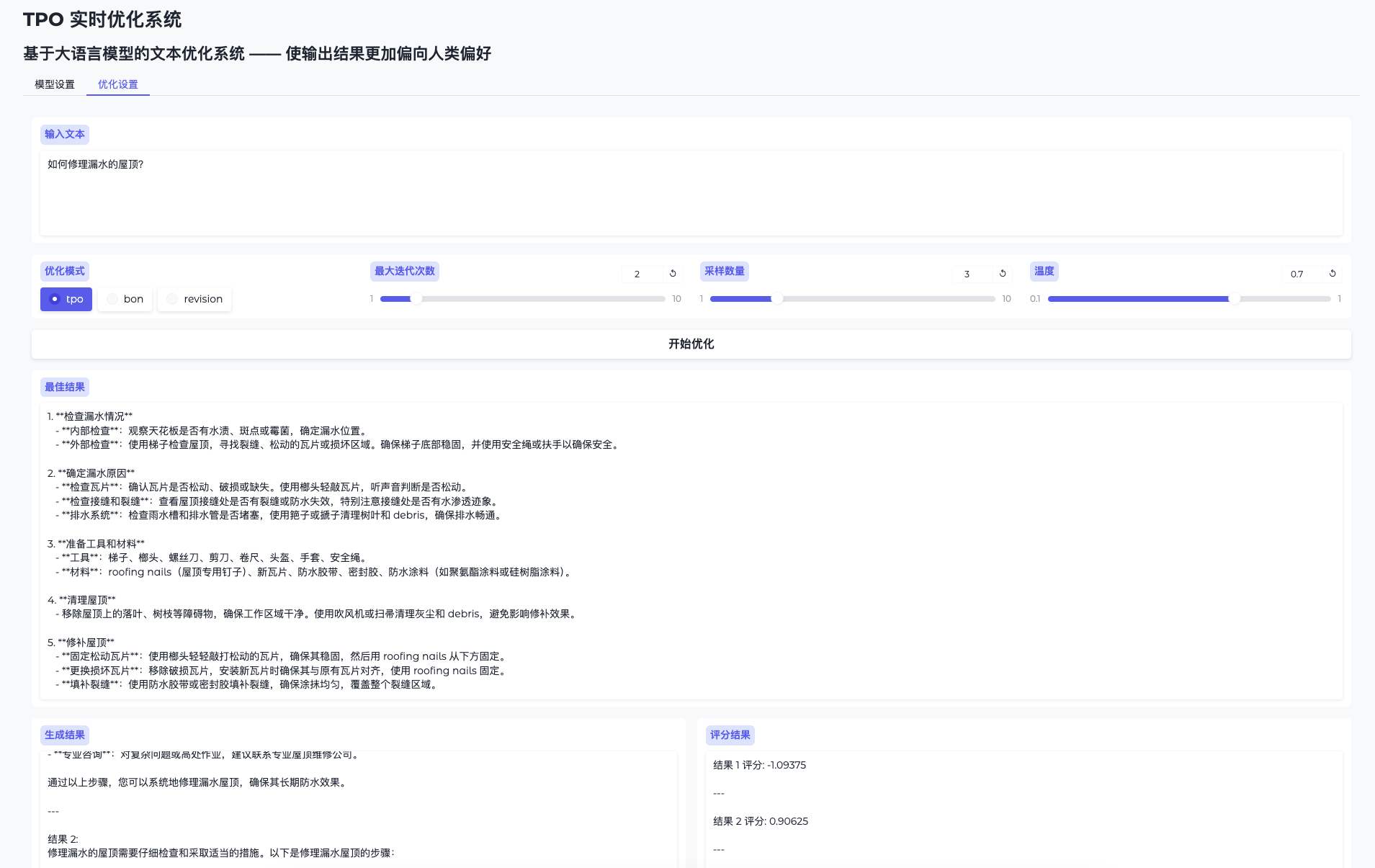
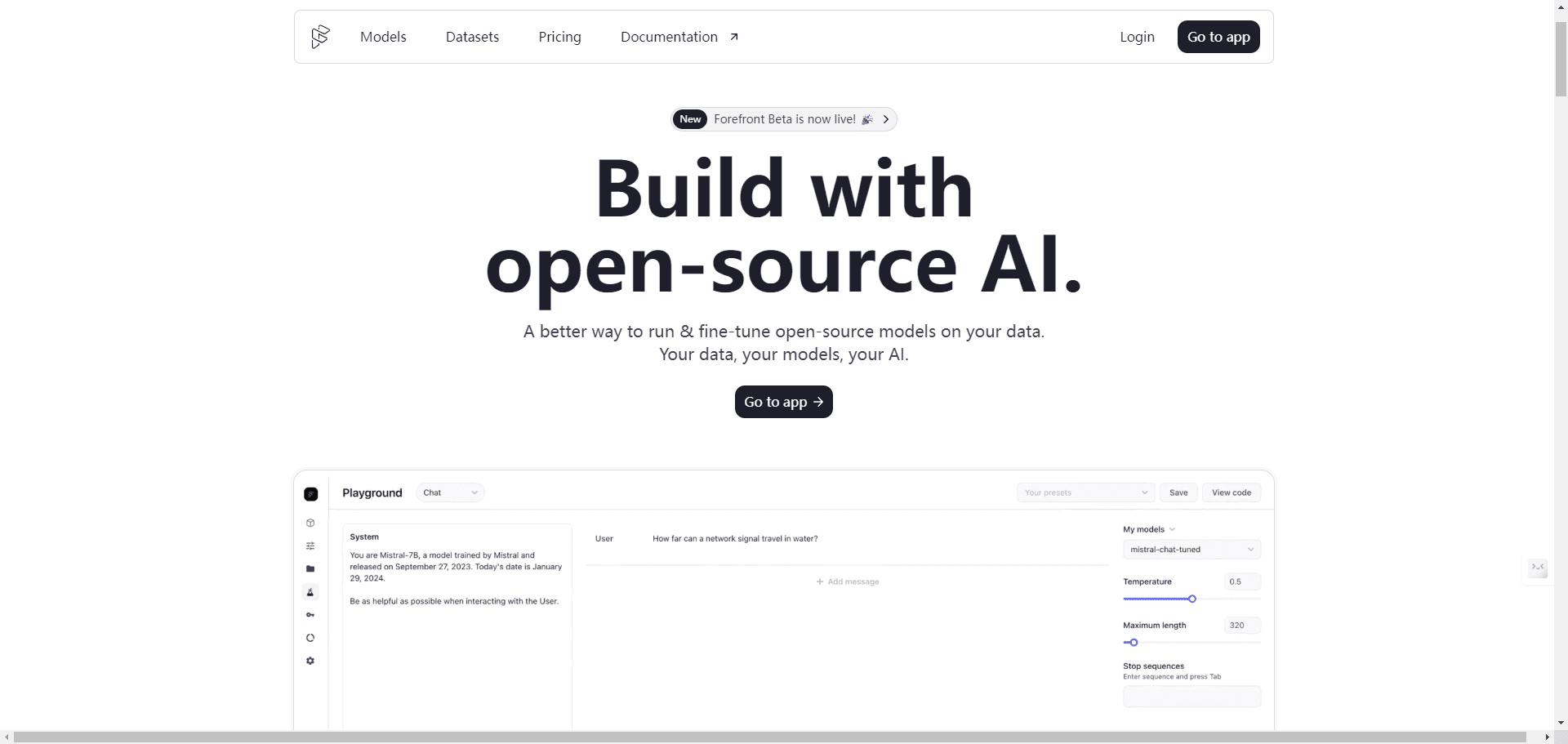
AI Toolkit de Ostris: Difusión estable con FLUX.1 Kit de herramientas de formación de modelos
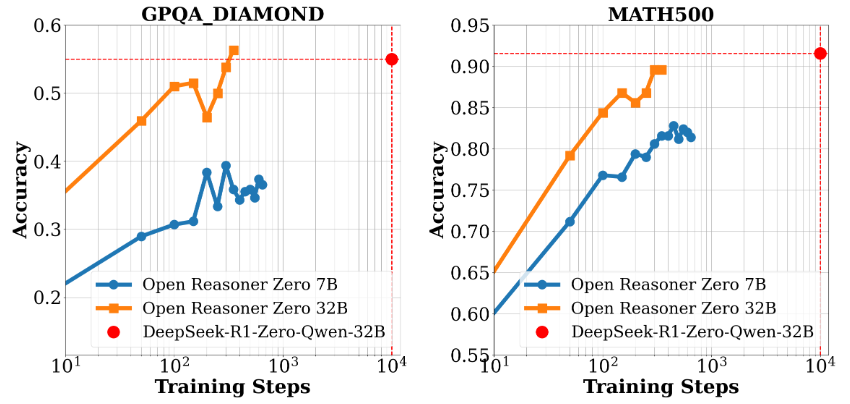
Introducción general AI Toolkit de Ostris es un conjunto de herramientas de IA de código abierto centrado en el soporte de los modelos Stable Diffusion y FLUX.1 para tareas de entrenamiento y generación de imágenes. El conjunto de herramientas es creado y mantenido por el desarrollador Ostris, tor...