r1-reasoning-rag: новые идеи для RAG, основанные на рекурсивных рассуждениях на основе собранной информации

Недавно я обнаружил проект с открытым исходным кодом, который предоставляет отличную RAG Идея, что это будет DeepSeek-R1 Способность к рассуждениям в сочетании Agentic Workflow Применяется для поиска RAG
Адрес проекта
https://github.com/deansaco/r1-reasoning-rag.git
Проект реализуется благодаря сочетанию DeepSeek-R1, иTavily ответить пением LangGraphв котором реализован механизм динамического поиска и ответа на вопросы с помощью искусственного интеллекта, использующий deepseek (используется в форме номинального выражения) r1 Рассуждения, позволяющие активно извлекать, отбрасывать и синтезировать информацию из базы знаний для полного ответа на сложный вопрос
Старый и новый RAG
Традиционная RAG (Retrieval Augmented Generation) немного жесткая, обычно после обработки поиска часть контента находится с помощью поиска по сходству, затем упорядочивается по степени совпадения, и те части информации, которые выглядят надежными, передаются большой языковой модели (LLM) для генерации ответа. Но это особенно зависит от качества модели переупорядочивания, и если модель не сильна, то легко пропустить важную информацию или передать LLM не то, что нужно, и результирующий ответ не будет надежным.
настоящее LangGraph Команда внесла существенные изменения в этот процесс, используя DeepSeek-R1 Мощная способность ИИ к рассуждению превратила прежний неподвижный метод фильтрации в более гибкий и динамичный процесс, который можно корректировать в зависимости от ситуации. Они называют это "агентским поиском", который позволяет ИИ не только активно искать недостающую информацию, но и постоянно оптимизировать свою собственную стратегию в процессе поиска информации, формируя своего рода эффект циклической оптимизации, благодаря чему контент, передаваемый LLM, будет более точным.
Это улучшение фактически применяет концепции расширенного рассуждения о времени тестирования изнутри модели к поиску RAG, значительно повышая точность и эффективность поиска. Этот новый подход определенно заслуживает внимания тех, кто работает над методами поиска по RAG!
Основные технологии и основные моменты
Рассуждения DeepSeek-R1
обновлено DeepSeek-R1 является мощной моделью вывода
- Глубокий анализ содержания информации
- Оценка существующего содержания
- Выявление недостающего контента путем многократного анализа для повышения точности результатов поиска
Tavily Мгновенный поиск информации
Tavily Обеспечивает мгновенный поиск информации, что может заставить большую модель получать самую свежую информацию, расширяя объем знаний модели.
- Динамический поиск, позволяющий восполнить недостающую информацию, а не полагаться только на статические данные.
LangGraph Рекурсивный поиск (RR)
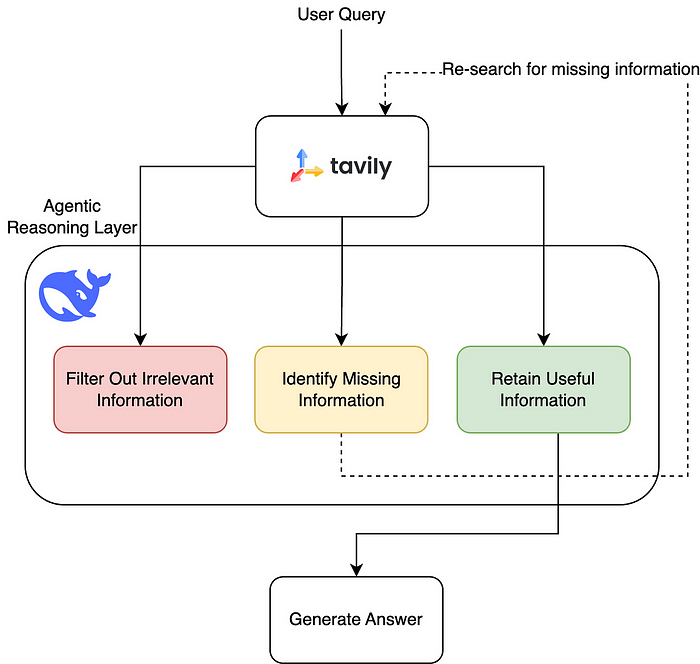
через Agentic AI механизм, позволяющий большой модели сформировать замкнутый цикл обучения после нескольких раундов поиска и умозаключений, со следующим общим процессом:
- Первый шаг - поиск информации о проблеме
- Второй шаг - анализ того, достаточно ли информации для ответа на вопрос.
- Шаг 3 Если информации недостаточно, наведите дополнительные справки
- Шаг 4 Отфильтруйте нерелевантный контент и сохраните только достоверную информацию
такие 递归式 Механизм поиска, обеспечивающий постоянную оптимизацию результатов запросов с помощью большой модели, что делает отфильтрованную информацию более полной и точной.
анализ исходного кода
Судя по исходному коду, это всего три файла:agent, иllm, иprompts
Агент
Основная идея этого раздела заключается в том, что create_workflow эта функция
 Он определяет это
Он определяет это workflow Узел add_conditional_edges Часть определения - это условный край, а вся идея обработки - это рекурсивная логика графа, показанная в начале
Если незнакомый LangGraph Если да, то вы можете ознакомиться с информацией.LangGraph Конструкция представляет собой графовую структуру данных с узлами и ребрами, причем ребра могут быть условными.
После каждого извлечения информации она проверяется с помощью большой модели, отсеивая бесполезную информацию (Filter Out Irrelevant Information), сохраняя полезную информацию (Retain Useful Information), а для недостающей информации (Identify Missing Information) она снова находится. Процесс повторяется до тех пор, пока не будет найден нужный ответ.
подсказывает
Здесь есть два основных признака.VALIDATE_RETRIEVAL : Используется для проверки того, что полученная информация может ответить на заданный вопрос. Шаблон имеет две входные переменные: retrieved_context и question. Его основная цель - сгенерировать ответ в формате JSON, который определяет, содержит ли он информацию, способную ответить на вопрос, на основе предоставленных текстовых блоков. 
ANSWER_QUESTION: Используется для указания агенту, отвечающему на вопросы, ответить на вопрос на основе предоставленного блока текста. Шаблон также имеет две входные переменные: retrieved_context и question. Его основная задача - предоставить прямой и лаконичный ответ на основе предоставленной контекстной информации.

llm
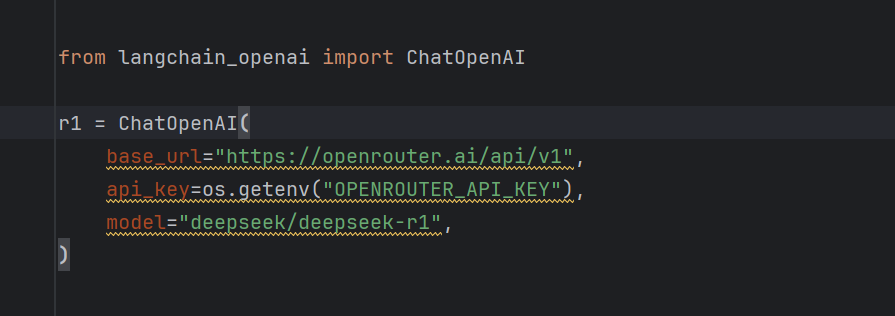
Здесь просто определить использование r1 моделирование
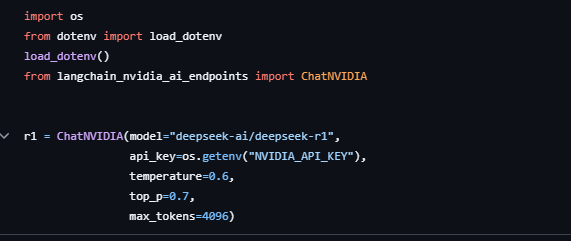
Можно переключиться на модели других производителей, например openrouter бесплатно r1 моделирование
тестовый эффект
Я написал здесь отдельный скрипт, который не использует тот, что в проекте, спрашивая о 《哪吒2》中哪吒的师傅的师傅是谁
Сначала он вызовет поиск, чтобы найти нужную информацию, а затем начнет проверять

Затем он начнет анализировать и получит 哪吒的师父是太乙真人 Это достоверная информация, но также обнаружена недостающая информация Конкретная личность или имя мастера Тайи (т.е. мастера Нежа)

Затем он начинает поиск недостающей информации и продолжает анализировать и проверять информацию, полученную в результате поиска.
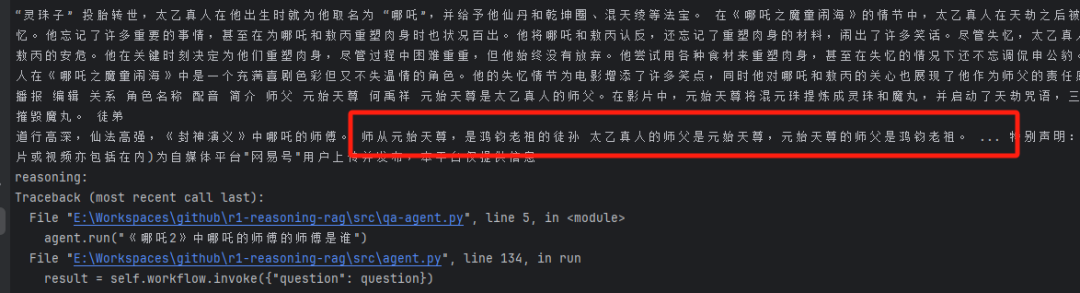
Позже он сообщил об ошибке, потому что сеть на моем конце была отключена, но, как видно из изображения выше, он должен был найти этот ключевой фрагмент информации
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...