
Освоение Crawl4AI: подготовка высококачественных веб-данных для LLM и RAG

Традиционные веб-краулеры универсальны, но часто требуют дополнительной очистки и форматирования при обработке данных, что делает их интеграцию с большими языковыми моделями (LLM) относительно сложной. Выходные данные многих инструментов (например, необработанные HTML или неструктурированный JSON) содержит много шума и не подходит для прямого использования в таких сценариях, как Retrieval Augmented Generation (RAG), поскольку это ухудшит LLM Эффективность и точность обработки.
Crawl4AI предлагает решение иного рода. Оно сосредоточено на непосредственной генерации чистой, структурированной Markdown Форматированный контент. Этот формат сохраняет смысловую структуру оригинального текста (например, заголовки, списки, блоки кода), при этом грамотно удаляя лишние элементы, такие как навигация, реклама, колонтитулы и т. д., что делает его идеальным для использования в качестве LLM входы или для создания высококачественных RAG Набор данных.Crawl4AI Это проект с полностью открытым исходным кодом, который не использует API Ключ также не установлен на пороге платного просмотра.
Установка и настройка
Рекомендации по применению uv Создайте и активируйте отдельный Python Виртуальная среда для управления зависимостями проекта.uv Он основан на Rust Развитые Развивающиеся Python Менеджер пакетов, обладающий значительным преимуществом в скорости (как правило, по сравнению с pip (в 3-5 раз быстрее) и эффективное параллельное разрешение зависимостей.
# 创建虚拟环境
uv venv crawl4ai-env
# 激活环境
# Windows
# crawl4ai-env\Scripts\activate
# macOS/Linux
source crawl4ai-env/bin/activate
После активации среды используйте uv монтаж Crawl4AI Основная библиотека:
uv pip install crawl4ai
После завершения установки выполните команду инициализации, которая позаботится об установке или обновлении Playwright Необходимые драйверы браузера (например. Chromium) и проводить экологические инспекции.Playwright Это одна из тех вещей, которые состоят из Microsoft библиотека автоматизации браузеров, разработаннаяCrawl4AI Используйте его для имитации реального взаимодействия с пользователем, чтобы иметь возможность обрабатывать динамически загружаемое содержимое JavaScript Тяжелый сайт.
crawl4ai-setup
Если у вас возникли проблемы с драйвером браузера, вы можете попробовать установить его вручную:
# 手动安装 Playwright 浏览器及依赖
python -m playwright install --with-deps chromium
При необходимости это можно сделать следующим образом uv Установка пакетов расширений, содержащих дополнительные функции:
# 安装文本聚类功能 (依赖 PyTorch)
uv pip install "crawl4ai[torch]"
# 安装 Transformers 支持 (用于本地 AI 模型)
uv pip install "crawl4ai[transformer]"
# 安装所有可选功能
uv pip install "crawl4ai[all]"
Пример базового ползания
столько или меньше Python Сценарий демонстрирует Crawl4AI Основное использование Markdown.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# 初始化异步爬虫
async with AsyncWebCrawler() as crawler:
# 执行爬取任务
result = await crawler.arun(
url="https://www.sitepoint.com/react-router-complete-guide/"
)
# 检查爬取是否成功
if result.success:
# 输出结果信息
print(f"标题: {result.title}")
print(f"提取的 Markdown ({len(result.markdown)} 字符):")
# 仅显示前 300 个字符作为预览
print(result.markdown[:300] + "...")
# 将完整的 Markdown 内容保存到文件
with open("example_content.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"内容已保存到 example_content.md")
else:
# 输出错误信息
print(f"爬取失败: {result.url}")
print(f"状态码: {result.status_code}")
print(f"错误信息: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())
После выполнения этого сценарияCrawl4AI активирует Playwright Контролируемый доступ браузера к определенным URLСтраница выполнения JavaScriptЗатем интеллектуально определяет и извлекает основные области контента, фильтрует отвлекающие элементы и в конечном итоге создает чистую Markdown Документация.
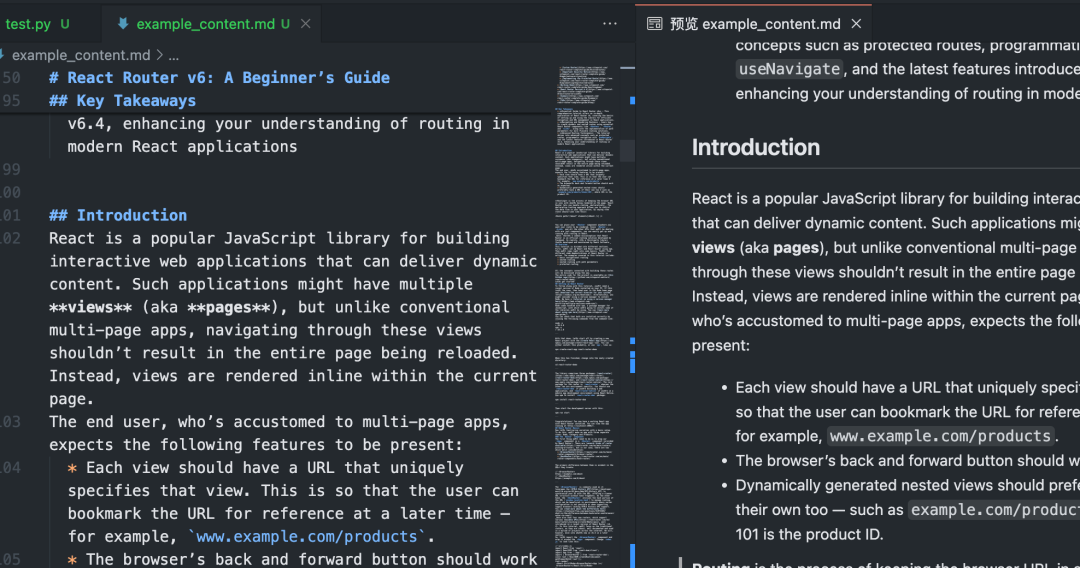
Пакетная и параллельная обработка
многократный процесс URL когдаCrawl4AI Параллельная обработка может значительно повысить эффективность. Настроив CrawlerRunConfig попал в точку concurrency параметр, который управляет количеством одновременно обрабатываемых страниц.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
# 添加更多 URL...
]
# 浏览器配置:无头模式,增加超时
browser_config = BrowserConfig(
headless=True,
timeout=45000, # 45秒超时
)
# 爬取运行配置:设置并发数,禁用缓存以获取最新内容
run_config = CrawlerRunConfig(
concurrency=5, # 同时处理 5 个页面
cache_mode=CacheMode.BYPASS # 禁用缓存
)
results = []
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
# 使用 arun_many 进行批量并行爬取
# 注意:arun_many 需要将 run_config 列表传递给 configs 参数
# 如果所有 URL 使用相同配置,可以创建一个配置列表
configs = [run_config.clone(url=url) for url in urls] # 为每个URL克隆配置并设置URL
# arun_many 返回一个异步生成器
async for result in crawler.arun_many(configs=configs):
if result.success:
results.append(result)
print(f"已完成: {result.url}, 获取了 {len(result.markdown)} 字符")
else:
print(f"失败: {result.url}, 错误: {result.error_message}")
# 将所有成功的结果合并到一个文件
with open("combined_results.md", "w", encoding="utf-8") as f:
for i, result in enumerate(results):
f.write(f"## {result.title}\n\n")
f.write(result.markdown)
f.write("\n\n---\n\n")
print(f"所有成功内容已合并保存到 combined_results.md")
if __name__ == "__main__":
asyncio.run(main())
принимать к сведению: В приведенном выше коде используется arun_many метод, который рекомендуется использовать для работы с большими списками URL, а не для циклического обращения к arun Более эффективно.arun_many Требуется список конфигураций, каждая из которых соответствует URL. Если все URL При использовании той же базовой конфигурации clone() метод создает копию и устанавливает определенный URL.
Извлечение структурированных данных (на основе селектора)
помимо Markdown(математика) родCrawl4AI Также в наличии CSS Селектор или XPath Извлекает структурированные данные, идеально подходит для сайтов с обычными форматами данных.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, ExtractorConfig
async def main():
# 定义提取规则 (CSS 选择器)
extractor_config = ExtractorConfig(
strategy="css", # 明确指定策略为 CSS
rules={
"products": {
"selector": "div.product-card", # 主选择器
"type": "list",
"properties": {
"name": {"selector": "h2.product-title", "type": "text"},
"price": {"selector": ".price span", "type": "text"},
"link": {"selector": "a.product-link", "type": "attribute", "attribute": "href"}
}
}
}
)
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://example-shop.com/products",
extractor_config=extractor_config
)
if result.success and result.extracted_data:
extracted_data = result.extracted_data
with open("products.json", "w", encoding="utf-8") as f:
json.dump(extracted_data, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(extracted_data.get('products', []))} 个产品信息")
print("数据已保存到 products.json")
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("未提取到数据或提取规则匹配失败")
if __name__ == "__main__":
asyncio.run(main())
Этот подход не требует LLM Недорогое и быстрое вмешательство подходит для сценариев, в которых целевой элемент очевиден.
Извлечение данных с помощью искусственного интеллекта
Для страниц со сложной структурой или без фиксированного шаблона можно использовать LLM Выполните интеллектуальное извлечение.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, BrowserConfig, AIExtractorConfig
async def main():
# 配置 AI 提取器
ai_config = AIExtractorConfig(
provider="openai", # 或 "local", "anthropic" 等
model="gpt-4o-mini", # 使用 OpenAI 的模型
# api_key="YOUR_OPENAI_API_KEY", # 如果环境变量未设置,在此提供
schema={
"type": "object",
"properties": {
"article_summary": {"type": "string", "description": "A brief summary of the article."},
"key_topics": {"type": "array", "items": {"type": "string"}, "description": "List of main topics discussed."},
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"], "description": "Overall sentiment of the article."}
},
"required": ["article_summary", "key_topics"]
},
instruction="Extract the summary, key topics, and sentiment from the provided article text."
)
browser_config = BrowserConfig(timeout=60000) # AI 处理可能需要更长时间
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(
url="https://example-news.com/article/complex-analysis",
ai_extractor_config=ai_config
)
if result.success and result.ai_extracted:
ai_extracted = result.ai_extracted
print("AI 提取的数据:")
print(json.dumps(ai_extracted, indent=2, ensure_ascii=False))
# 也可以选择保存到文件
# with open("ai_extracted_data.json", "w", encoding="utf-8") as f:
# json.dump(ai_extracted, f, ensure_ascii=False, indent=2)
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("AI 未能提取所需数据。")
if __name__ == "__main__":
asyncio.run(main())
Извлечение искусственного интеллекта обеспечивает большую гибкость в понимании контента и создании структурированных результатов по требованию, но требует дополнительных затрат. API Стоимость звонка (при использовании облачного сервиса) LLM) и время обработки. Выберите локальную модель (например. Mistral, Llama) позволяют сократить расходы и защитить конфиденциальность, но требуют локального оборудования.
Дополнительные настройки и советы
Crawl4AI Предоставляет множество вариантов конфигурации для решения сложных сценариев.
Конфигурация браузера (BrowserConfig)
BrowserConfig Управляет запуском и поведением самого браузера.
from crawl4ai import BrowserConfig
config = BrowserConfig(
browser_type="firefox", # 使用 Firefox 浏览器
headless=False, # 显示浏览器界面,方便调试
user_agent="MyCustomCrawler/1.0", # 设置自定义 User-Agent
proxy_config={ # 配置代理服务器
"server": "http://proxy.example.com:8080",
"username": "proxy_user",
"password": "proxy_password"
},
ignore_https_errors=True, # 忽略 HTTPS 证书错误 (开发环境常用)
use_persistent_context=True, # 启用持久化上下文
user_data_dir="./my_browser_profile", # 指定用户数据目录,用于保存 cookies, local storage 等
timeout=60000, # 全局浏览器操作超时 (毫秒)
verbose=True # 打印更详细的日志
)
# 在初始化 AsyncWebCrawler 时传入
# async with AsyncWebCrawler(browser_config=config) as crawler:
# ...
Просмотрите конфигурацию времени выполнения (CrawlerRunConfig)
CrawlerRunConfig Управление одиночное arun() возможно arun_many() Специфическое поведение вызова.
from crawl4ai import CrawlerRunConfig, CacheMode
run_config = CrawlerRunConfig(
cache_mode=CacheMode.READ_ONLY, # 只读缓存,不写入新缓存
check_robots_txt=True, # 检查并遵守 robots.txt 规则
wait_until="networkidle", # 等待网络空闲再提取,适合JS动态加载内容
wait_for="css:div#final-content", # 等待特定 CSS 选择器元素出现
js_code="window.scrollTo(0, document.body.scrollHeight);", # 页面加载后执行 JS 代码 (例如滚动到底部触发加载)
scan_full_page=True, # 尝试自动滚动页面以加载所有内容 (用于无限滚动)
screenshot=True, # 截取页面截图 (结果在 result.screenshot,Base64编码)
pdf=True, # 生成页面 PDF (结果在 result.pdf,Base64编码)
word_count_threshold=50, # 过滤掉少于 50 个单词的文本块
excluded_tags=["header", "nav", "footer", "aside"], # 从 Markdown 中排除特定 HTML 标签
exclude_external_links=True # 不提取外部链接
)
# 在调用 arun() 或创建配置列表给 arun_many() 时传入
# result = await crawler.arun(url="...", config=run_config)
Работа с JavaScript и динамическим содержимым
благодаря Playwright(математика) родCrawl4AI Хорошо справляется с зависимостями JavaScript Рендеринг сайта. Ключевая конфигурация:
wait_until: Установить на"networkidle"возможно"load"Обычно он немного эффективнее, чем используемый по умолчанию"domcontentloaded"Больше подходит для динамических страниц.wait_for: ожидание определенного элемента илиJavaScriptУсловия соблюдены.js_code: Выполнение настройки после загрузки страницыJavaScriptНапример, нажимать на кнопки и прокручивать страницы.scan_full_page:: Автоматическая обработка обычных страниц с бесконечной прокруткой.delay_before_return_html: Добавьте небольшую задержку перед извлечением, чтобы убедиться, что все скрипты выполнены.
Обработка ошибок и отладка
- зонд
result.success: Обязательно проверяйте это свойство после каждого ползания. - проверять
result.status_codeответить пениемresult.error_message:: Получите информацию о причине неудачи. - устанавливать
headless=False: ВBrowserConfigВы можете наблюдать за работой браузера и визуально диагностировать проблему. - начать использовать
verbose=True: ВBrowserConfigв настройках, чтобы получить более подробный журнал выполнения. - пользоваться
try...except: Посылкаarun()возможноarun_many()вызов, который фиксирует возможныйPythonИсключение.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def debug_crawl():
# 启用调试模式:显示浏览器,打印详细日志
debug_browser_config = BrowserConfig(headless=False, verbose=True)
async with AsyncWebCrawler(browser_config=debug_browser_config) as crawler:
try:
result = await crawler.arun(url="https://problematic-site.com")
if not result.success:
print(f"Crawl failed: {result.error_message} (Status: {result.status_code})")
else:
print("Crawl successful.")
# ... process result ...
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
asyncio.run(debug_crawl())
соблюдение robots.txt
При выполнении веб-ползания уважайте сайт robots.txt Документирование является основой сетевого этикета и предотвращает блокировку IP-адресов.Crawl4AI Он может быть обработан автоматически.
существовать CrawlerRunConfig устанавливать check_robots_txt=True::
respectful_config = CrawlerRunConfig(
check_robots_txt=True
)
# result = await crawler.arun(url="https://example.com", config=respectful_config)
# if not result.success and result.status_code == 403:
# print("Access denied by robots.txt")
Crawl4AI Автоматически загружается, кэшируется и разбирается robots.txt файл, если правило запрещает доступ к целевому URL(математика) родarun() потерпит неудачу.result.success из-за False(математика) родstatus_code Обычно это 403 сообщения об ошибке.
Управление сеансами (Session Management)
Для многоэтапных операций, требующих входа в систему или сохранения состояния (например, отправка формы, постраничная навигация), можно использовать управление сеансами. Этого можно добиться, добавив новый менеджер сессий в CrawlerRunConfig Укажите то же самое в session_idЭто можно сделать на нескольких arun() Один и тот же экземпляр страницы браузера повторно используется между вызовами, сохраняя cookies ответить пением JavaScript Статус.
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
async def session_example():
async with AsyncWebCrawler() as crawler:
session_id = "my_unique_session"
# Step 1: Load login page (hypothetical)
login_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
await crawler.arun(url="https://example.com/login", config=login_config)
print("Login page loaded.")
# Step 2: Execute JS to fill and submit login form (hypothetical)
login_js = """
document.getElementById('username').value = 'user';
document.getElementById('password').value = 'pass';
document.getElementById('loginButton').click();
"""
submit_config = CrawlerRunConfig(
session_id=session_id,
js_code=login_js,
js_only=True, # 只执行 JS,不重新加载页面
wait_until="networkidle" # 等待登录后跳转完成
)
await crawler.arun(config=submit_config) # 无需 URL,在当前页面执行 JS
print("Login submitted.")
# Step 3: Crawl a protected page within the same session
protected_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
result = await crawler.arun(url="https://example.com/dashboard", config=protected_config)
if result.success:
print("Successfully crawled protected page:")
print(result.markdown[:200] + "...")
else:
print(f"Failed to crawl protected page: {result.error_message}")
# 清理会话 (可选,但推荐)
# await crawler.crawler_strategy.kill_session(session_id)
if __name__ == "__main__":
asyncio.run(session_example())
Более продвинутое управление сеансами включает экспорт и импорт состояния хранилища браузера (cookies, localStorage), что позволяет сохранять логин между запусками скрипта.
Crawl4AI Мощный и гибкий набор функций, который при правильной настройке позволяет эффективно и надежно извлекать необходимую информацию с различных веб-сайтов и готовить высококачественные данные для последующих приложений искусственного интеллекта.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...