
Иллюзия большой модели: рейтинги HHEM дают представление о состоянии фактической последовательности в LLM

Хотя возможности больших языковых моделей (LLM) постоянно развиваются, феномен фактических ошибок или "иллюзий" информации, не связанной с оригинальным текстом, в их результатах всегда был серьезной проблемой, которая препятствовала их более широкому использованию и более глубокому доверию. Для того чтобы количественно оценить эту проблему, в статьеРейтинг модели оценки галлюцинаций Хьюза (HHEM)В ходе работы был создан проект, направленный на измерение частоты использования фантомных слов в основных LLM при составлении резюме документов.
Термин "иллюзия" относится к тому, что модель вносит в резюме "факты", которые не содержатся в исходном документе или даже противоречат ему. Это критическое узкое место качества для сценариев обработки информации, опирающихся на LLM, особенно тех, которые основаны на Retrieval Augmented Generation (RAG). Ведь если модель не соответствует заданной информации, доверие к ее результату значительно снижается.
Как работает HHEM?
В рейтинге используется модель оценки галлюцинаций HHEM-2.1, разработанная компанией Vectara. Принцип ее работы заключается в том, что для исходного документа и резюме, подготовленного конкретным LLM, модель HHEM выводит оценку галлюцинаций в диапазоне от 0 до 1. Чем ближе оценка к 1, тем выше фактическое соответствие резюме исходному документу; чем ближе к 0, тем сильнее галлюцинации или даже полностью сфабрикованный контент. Vectara также предоставляет версию с открытым исходным кодом, HHEM-2.1-Open, для исследователей и разработчиков, чтобы проводить оценку на месте, а карточки модели опубликованы на платформе Hugging Face.
Контрольные показатели оценки
Для оценки использовался набор данных из 1006 документов, в основном из общедоступных наборов данных, таких как классический корпус CNN/Daily Mail Corpus. Команда проекта создала резюме для каждого документа, используя отдельные LLM, участвующие в оценке, а затем вычислила оценку HHEM для каждой пары (исходный документ, созданное резюме). Для обеспечения стандартизации оценки все вызовы модели были установлены на temperature Параметр равен 0 и предназначен для получения наиболее детерминированного результата модели.
Показатели оценки включают, в частности, следующее:
- Скорость галлюцинаций. Процент рефератов с оценкой HHEM ниже 0,5. Чем ниже значение, тем лучше.
- Коэффициент соответствия фактам. 100% минус процент галлюцинаций, отражающий долю рефератов, содержание которых соответствует оригиналу.
- Скорость ответа. Процент моделей, успешно генерирующих непустые резюме. Некоторые модели могут отказываться отвечать или делать ошибки из-за политик безопасности контента или по другим причинам.
- Средняя длина резюме. Среднее количество слов в сгенерированных резюме дает представление о стиле вывода модели.
Иллюзорные рейтинги LLM объясняются
Ниже представлены рейтинги галлюцинаций LLM, основанные на оценке модели HHEM-2.1 (данные по состоянию на 25 марта 2025 года, см. актуальное обновление):
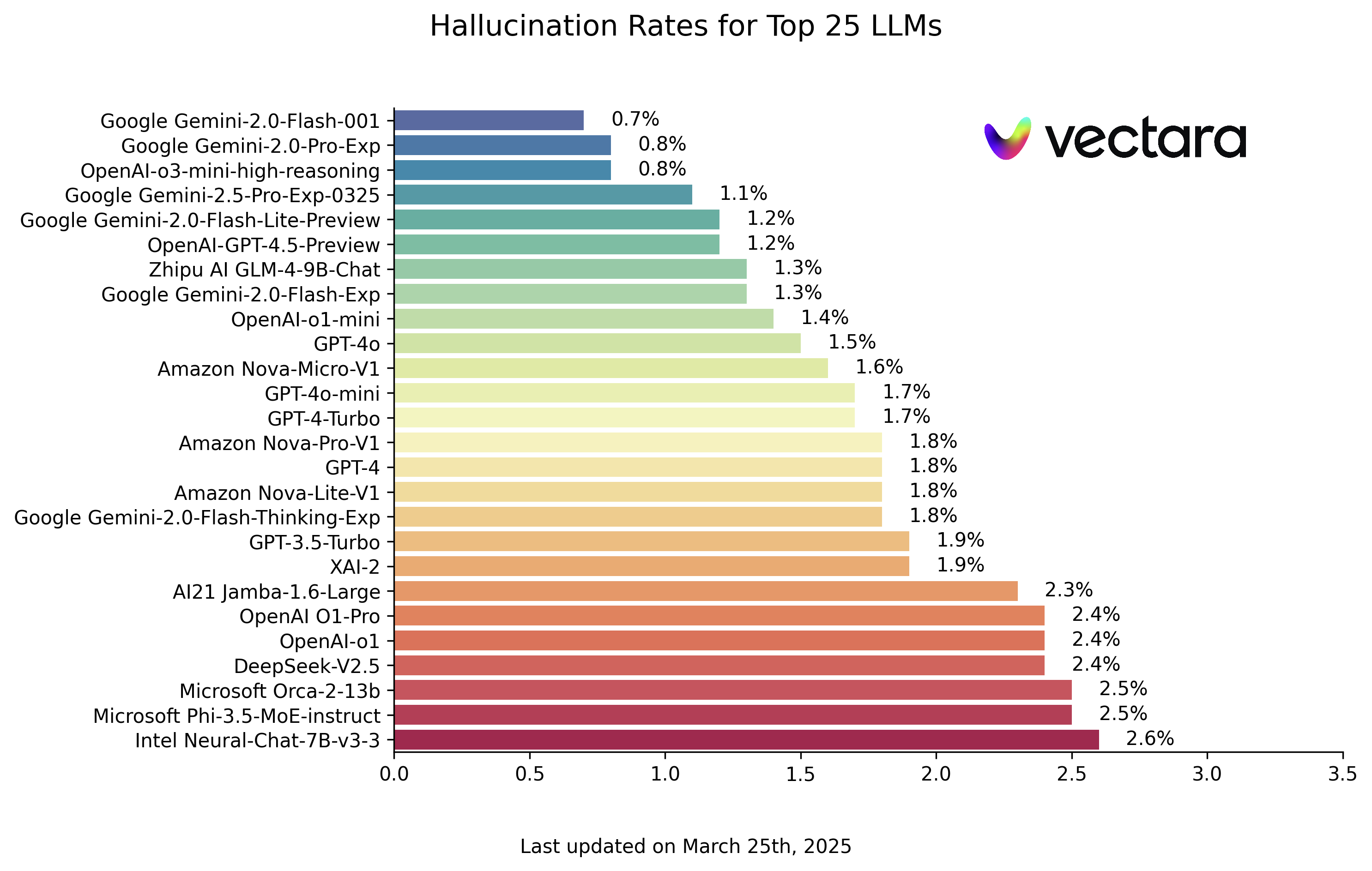
| Модель | Частота галлюцинаций | Коэффициент соответствия фактам | Скорость ответа | Средняя длина резюме (слов) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-mini-high-reasoning | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| Google Gemini-2.5-Pro-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| Google Gemini-2.0-Flash-Lite-Preview | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-Preview | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Google Gemini-2.0-Flash-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| Amazon Nova-Micro-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Flash-Thinking-Exp | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| Amazon Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| Amazon Nova-Pro-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 Jamba-1.6-Large | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| OpenAI O1-Pro | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-instruct | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Google Gemma-3-12B-Instruct | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-Инструкция | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| XAI-2-Vision | 2.9 % | 97.1 | 100.0 % | 79.8 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| Google Gemma-3-27B-Instruct | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| Снежинка-Арктика-Инструкция | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Инструкция | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| Мистраль Small3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| Microsoft Phi-4-мини-инструкция | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| Google Gemma-3-4B-Instruct | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| СтажерLM3-8B-Инструктор | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| Microsoft Phi-3.5 - мини-инструкция | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Мистраль-большой2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Instruct | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Инструкция | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Инструкция | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Клод-3.7-Соннет | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| Клод-3.7-Соннет-Размышления | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| Cohere Команда-А | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21 Jamba-1.6-Mini | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Антропология Клод-3-5-соннет | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Инструкция | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Антропный Клод-3-5-хайку | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Google Gemma-3-1B-Instruct | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| Llama-3.1-8B-Инструкция | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Command-R-Plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Мистраль-Малый-3.1-24B-Инструкция | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| Llama-3.2-11B-Vision-Instruct | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Мистраль-Пикстраль | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Инструкция | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Мистраль-Министраль-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Ллама-3.2-3B-Инструкция | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DeepSeek-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| Мистраль-Министраль-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| databricks dbrx-instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Instruct | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expanse 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| Мистраль-маленький2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBM Granite-3.2-8B-Instruct | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instruct-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Антропный Клод-3-опус | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instruct | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instruct | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| Мистраль-Немо-Инструкция | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft WizardLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Коэр Айя Экспансия 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| DeepSeek-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granite-3.1-2B-Instruct | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Инструкция | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-Preview | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Антропный сонет Клод-3 | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBM Granite-3.2-2B-Instruct | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| Google Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Антропный Клод-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-large | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Instruct-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Ллама-3.2-1B-Инструкция | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-Инструкция | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| ТИИ сокол-7Б-инструкция | 29.9 % | 70.1 % | 90.0 % | 75.5 |
Примечание: Модели ранжированы в порядке убывания на основе показателя фантомности. Полный список и информацию о доступе к моделям можно посмотреть в оригинальном репозитории HHEM Leaderboard на GitHub.
Взгляд на таблицу лидеров показывает, что Google Gemini серия моделей и некоторые из новых моделей OpenAI (например, модель o3-mini-high-reasoning) показали впечатляющие результаты, а количество галлюцинаций осталось на очень низком уровне. Это свидетельствует о прогрессе, достигнутом производителями головок в улучшении факториальности их моделей. В то же время заметны существенные различия между моделями разных размеров и архитектур. Некоторые небольшие модели, такие как Microsoft Phi серия или Google Gemma В этой серии также были получены хорошие результаты, что говорит о том, что количество параметров модели не является единственным фактором, определяющим согласованность фактов. Однако некоторые ранние или специально оптимизированные модели имеют относительно высокие показатели иллюзий.
Несоответствие между сильными моделями умозаключений и базами знаний: случай DeepSeek-R1
чарты (бестселлеры) DeepSeek-R1 Относительно высокий уровень галлюцинаций (14,31 TP3T) поднимает вопрос, который стоит изучить: почему некоторые модели, которые хорошо справляются с задачами на рассуждение, склонны к галлюцинациям в задачах на обобщение фактов?
DeepSeek-R1 Такие модели часто рассчитаны на сложные логические рассуждения, следование командам и многоступенчатое мышление. Их основная сила - в "дедукции" и "выведении", а не просто в "повторении" или "перефразировании". Однако базы знаний (особенно RAG (база знаний в сценариях), основным требованием является именно последнее: модель должна отвечать или обобщать строго на основе предоставленной текстовой информации, сводя к минимуму внедрение внешних знаний или чрезмерное извлечение.
Когда сильная модель рассуждений ограничивается подведением итогов только по данному документу, ее "рассуждающий" инстинкт может стать обоюдоострым мечом. Это может:
- Излишняя интерпретация. Неоправданно глубокая экстраполяция информации из оригинального текста и выводы, не указанные в оригинальном тексте.
- Информация о швах. Попытка связать разрозненную информацию в оригинальном тексте с помощью "разумной" логической цепочки, которая может не поддерживаться оригинальным текстом.
- Внешние знания по умолчанию. Даже когда их просят опираться только на оригинальный текст, обширные знания о мире, приобретенные в процессе обучения, все равно могут просочиться бессознательно, что приведет к отклонениям от фактов оригинального текста.
Проще говоря, такие модели могут "слишком много думать", и в сценариях, требующих точного и достоверного воспроизведения информации, они склонны быть "слишком умными для собственного блага", создавая контент, который кажется разумным, но на самом деле является иллюзией. Это показывает, что способность моделей к рассуждению и согласованность фактов (особенно в случае ограниченных источников информации) - это два разных измерения способностей. Для таких сценариев, как базы знаний и RAGs, может быть более важно выбрать модели с низким уровнем галлюцинаций, которые точно отражают входную информацию, чем просто стремиться к получению баллов за рассуждения.
Методология и история вопроса
Рейтинг HHEM появился не на пустом месте и опирается на ряд предыдущих работ в области исследования фактической последовательности, таких как SUMMAC, TRUE, TrueTeacher Методология, разработанная в работах et al. Основная идея заключается в обучении модели, специально предназначенной для обнаружения галлюцинаций, которая достигает высокого уровня корреляции с человеческими оценщиками в плане оценки соответствия резюме оригинальному тексту.
Задача обобщения была выбрана в процессе оценки в качестве косвенного показателя фактологичности LLM. Это объясняется не только тем, что задача обобщения сама по себе требует высокой степени фактологической согласованности, но и тем, что она очень похожа на рабочую модель системы RAG - в RAG именно LLM играет роль интеграции и обобщения полученной информации. Таким образом, результаты этого ранжирования являются информативными для оценки надежности модели в приложениях RAG.
Важно отметить, что команда оценки исключила документы, на которые модели отказались отвечать или дали очень короткие и недействительные ответы, и в итоге для обеспечения справедливости использовала 831 документ (из первоначальных 1006), по которым все модели смогли успешно составить резюме для окончательного расчета рейтинга. Показатели частоты ответов и средней длины резюме также отражают поведение моделей при обработке этих запросов.
Шаблон подсказки, использованный для оценки, выглядит следующим образом:
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
Во время фактического вызова<PASSAGE> будет заменено содержимым конкретного исходного документа.
с нетерпением жду
Программа рейтинга HHEM сообщила, что в будущем планирует расширить рамки оценки:
- Точность цитирования. Добавьте оценку точности цитирования источников LLM в сценарии RAG.
- Другие задачи RAG. Охватите больше задач, связанных с RAG, например, обобщение нескольких документов.
- Поддержка нескольких языков. Распространите оценку на другие языки, кроме английского.
Рейтинг HHEM - это ценное окно для наблюдения и сравнения способности различных LLM контролировать иллюзии и поддерживать последовательность фактов. Хотя это не единственная мера качества модели и не охватывает все типы иллюзий, он, безусловно, привлек внимание индустрии к вопросу надежности LLM и служит важной точкой отсчета для разработчиков при выборе и оптимизации моделей. По мере совершенствования моделей и методов оценки мы можем ожидать еще большего прогресса в предоставлении точной и достоверной информации от LLM.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...