Практическая работа с DeepSeek: построение графа знаний в три этапа - одиночное извлечение, множественное объединение, генерация тем

Вопрос: Графы знаний очень важны, языковая модель DeepSeek очень популярна, можно ли с ее помощью быстро строить графы знаний? Я хочу попробовать. DeepSeek чтобы проверить, насколько хорошо он справляется с извлечением информации, интеграцией знаний и созданием графиков из воздуха.
Методы: Я провел три эксперимента, чтобы проверить возможности DeepSeek по построению графов знаний:
- Картографирование сборки одной статьи: Дайте DeepSeek статью и посмотрите, сможет ли он точно захватить информацию и построить график.
- Сопоставление нескольких статей: Дайте DeepSeek несколько статей, чтобы проверить, сможет ли он добавить новые знания в существующий граф.
- Картографирование тематического поколения: Просто укажите DeepSeek тему атласа, а не статью, и посмотрите, сможет ли он самостоятельно разработать атлас.
Результаты: Эксперименты показали, что DeepSeek хорошо строит и объединяет графы знаний, но еще есть возможности для улучшения.
Вот точный процесс и результаты эксперимента, которые я изложу более простым языком.
I. Извлечение знаний из одной статьи для построения карты
Цель: Тестирование способности DeepSeek извлекать знания из статьи и строить граф знаний.
Процесс: Я нашел статью о графовых базах данных NebulaGraph и попросил DeepSeek прочитать статью, извлечь ключевую информацию, а затем сгенерировать код базы данных NebulaGraph (nGQL) для создания графа знаний.
Инструкции: "Можете ли вы помочь мне создать граф знаний? Я дам вам статью, вы извлечете из нее ключевую информацию и построите граф знаний с помощью кода nGQL".
Операция: Скопируйте и вставьте содержимое статьи прямо в DeepSeek.
Сгенерированный DeepSeek код на языке nGQL:
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
Результаты: Код DeepSeek в порядке, синтаксис правильный, и он эффективен, поскольку объединяет несколько частей данных в одном операторе. Код помещается в NebulaGraph для запуска, график выглядит следующим образом:
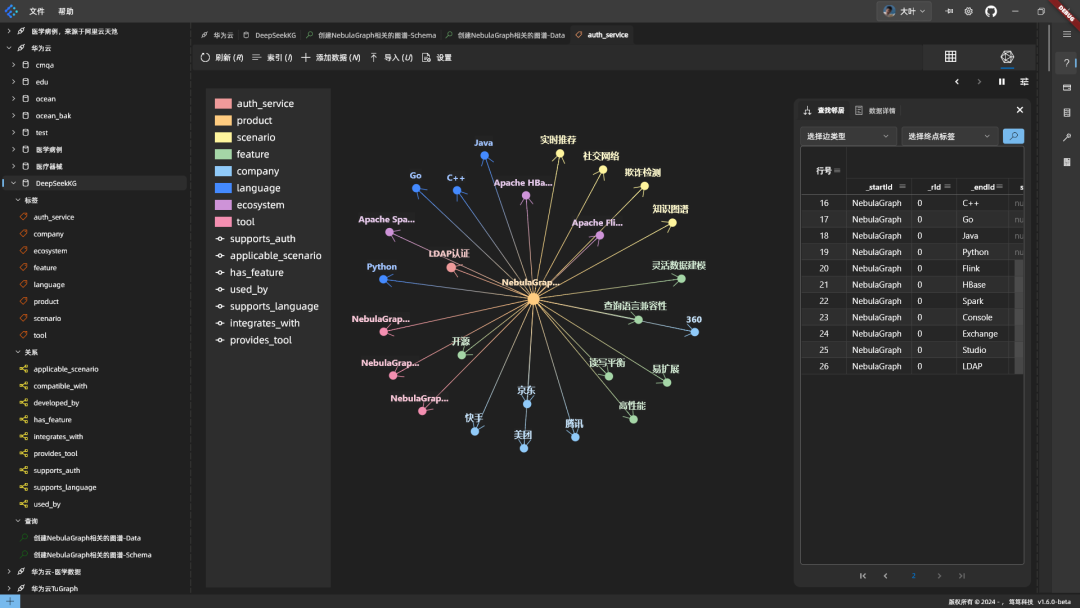
График центрируется на NebulaGraph и отображает соответствующую информацию.
II. Интеграция знаний по нескольким статьям
Цель: Проверка способности DeepSeek объединять знания из нескольких статей для расширения существующего графа.
Процесс: Сначала постройте граф с помощью одной статьи, затем дайте DeepSeek больше статей о NebulaGraph (из энциклопедии Baidu), чтобы объединить новые знания с существующим графом.
Инструкции: "Далее, еще одна статья для вас. Попробуйте совместить отображение с текущей структурой таблицы. Для изменения структуры таблицы используйте команду ALTER".
Операция: Аннотации записей в NebulaGraph и 360 Encyclopedia были переданы в DeepSeek, соответственно.
Код nGQL, сгенерированный DeepSeek (запись NebulaGraph):
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
Сгенерированный DeepSeek код на языке nGQL (360 слов):
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
Результаты: DeepSeek может изменить структуру таблицы на основе новой статьи (например, предоставив продукт ответить пением компания таблица плюс поля), а также добавляет новый тип отношения. Это делается по мере необходимости с помощью ALTER чтобы изменить структуру таблицы. Небольшая проблема заключается в том, что в комментарии используется --nGQL не распознан, измените его вручную. # На линии.
Код помещается в базу данных для выполнения, и слитое отображение работает:
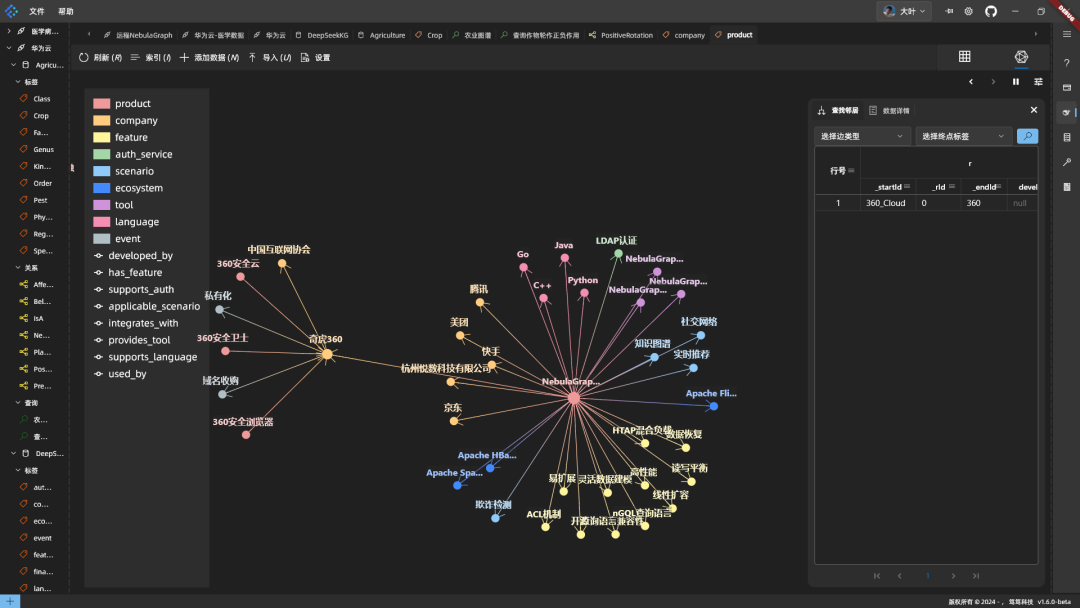
Резюме: DeepSeek хорошо подходит для построения графов и объединения знаний. Однако сервер иногда работает медленно, а NebulaGraph изменяет схему асинхронно и требует времени для вступления в силу.
III. Создание темы: сельскохозяйственное картографирование из ничего
Цель: Тестирование способности DeepSeek генерировать графы знаний на основе тем без статей.
Процесс: Создайте новый диалог и позвольте DeepSeek сгенерировать картографический код непосредственно по теме "Сельское хозяйство". Статьи не задаются, это "свободный выбор".
Инструкции: "Я хочу построить граф знаний о сельском хозяйстве. Использую базу данных NebulaGraph и генерирую скрипт nGQL. Имена таблиц - большой горб, имена атрибутов - маленький горб. Имена схем обернуты ``, чтобы избежать конфликтов. Сгенерируйте не менее 3000 узлов".
Код nGQL, сгенерированный DeepSeek (частично):
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
Проблемы и улучшения:
- Ограничение количества узлов: Начав с 3000 узлов, DeepSeek отказался и предоставил Python для импорта CSV-кода. Я не хотел использовать Python, поэтому уменьшил количество узлов.
- Снова встает вопрос об аннотации: Комментарии к коду снова --Вопрос снова был задан.
Инструкции по улучшению: "Используйте # для комментариев, никакого Python-кода, 3000 узлов - это слишком много. Просто дайте мне ngql-скрипт для 50 узлов".
Последующий диалог и инструкции: Чтобы доработать карту, я продолжал общаться с DeepSeek, прося его добавить данные, усилить ассоциации, организовать карту по классификации (филум, порядок, семейство, род и вид), а также попросить его сгенерировать данные о севообороте.
Например, мои инструкции:
- "Дополнительные данные для более тесной связи данных".
- "Составьте атлас этих классификаций [филумов, порядков, семейств, родов и видов]".
- "Определите противопоказания и вводите культуры в севооборот с существующими культурами".
- "Объединение картографических данных о тканях сельскохозяйственных культур для создания скриптов nGQL в прежнем формате".
Экспериментальная интерлюдия: DeepSeek, один раз. INSERT Оператор использует синтаксис Cypher, который не поддерживается nGQL, и это было отмечено и изменено.
Инструкции: "Этот оператор вставки не соответствует синтаксису nGQL. Измените его так, чтобы DDL был на первом месте, а DML - на втором".
Окончательный объем данных: После нескольких раундов диалога отображается количество данных:

Картографические эффекты: Разверните несколько случайных узлов, чтобы посмотреть:
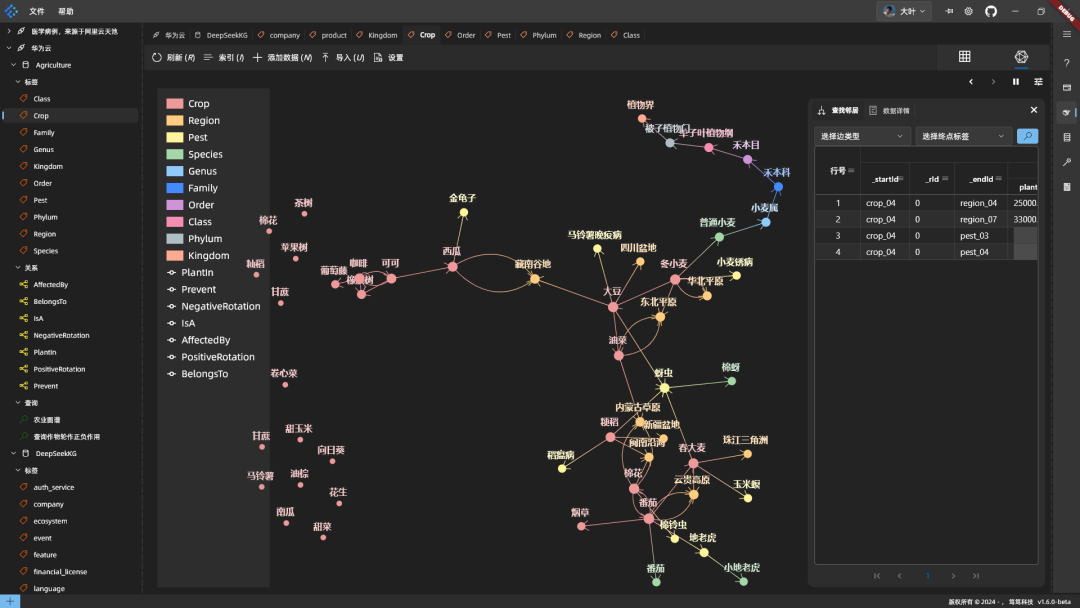
Примеры сочетаний видов, повышающих урожайность: Комбинационные эффекты адвентивной посадки, повышающие урожайность:
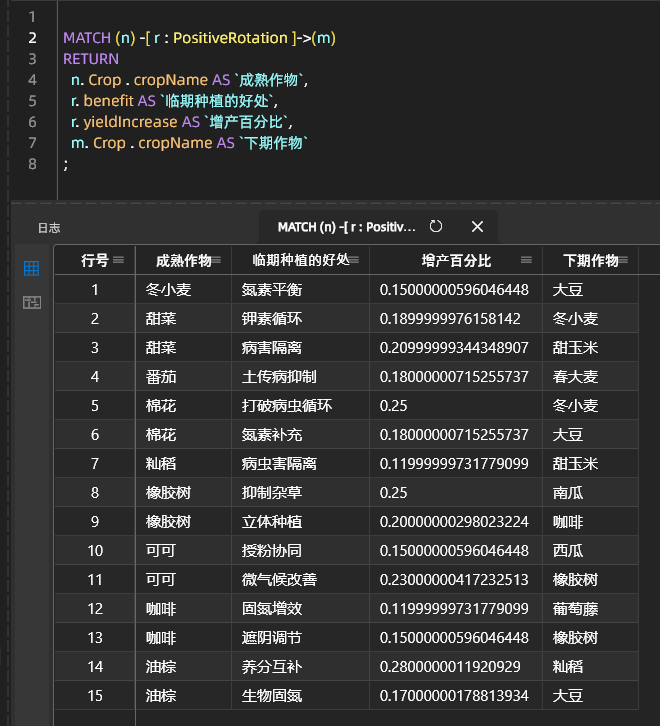
IV. Резюме
Заключение: DeepSeek отлично справляется с построением и объединением графов знаний, и эксперименты демонстрируют его возможности:
- Извлечение информации происходит быстро и точно: DeepSeek быстро извлекает ключевую информацию из текста, генерирует совместимые скрипты nGQL и обладает сильным языковым восприятием для распознавания сущностей, отношений и событий.
- Сильная способность интегрировать знания: DeepSeek хорошо объединяет знания из множества статей, расширяет и обновляет граф на основе новых статей, а также обеспечивает полноту и точность графа.
- Вы можете построить карту из ничего: Ни одна статья не может генерировать диаграммы по темам. В процессе генерации есть некоторые синтаксические заминки, но корректировки создают приемлемые скрипты.
- Детали должны быть оптимизированы: В скриптах, генерируемых DeepSeek, иногда возникают проблемы с синтаксисом, например, некорректные комментарии. При генерации большого количества узлов сервер может медленно отвечать на запросы. Обращайте внимание на эти проблемы при реальном использовании.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...