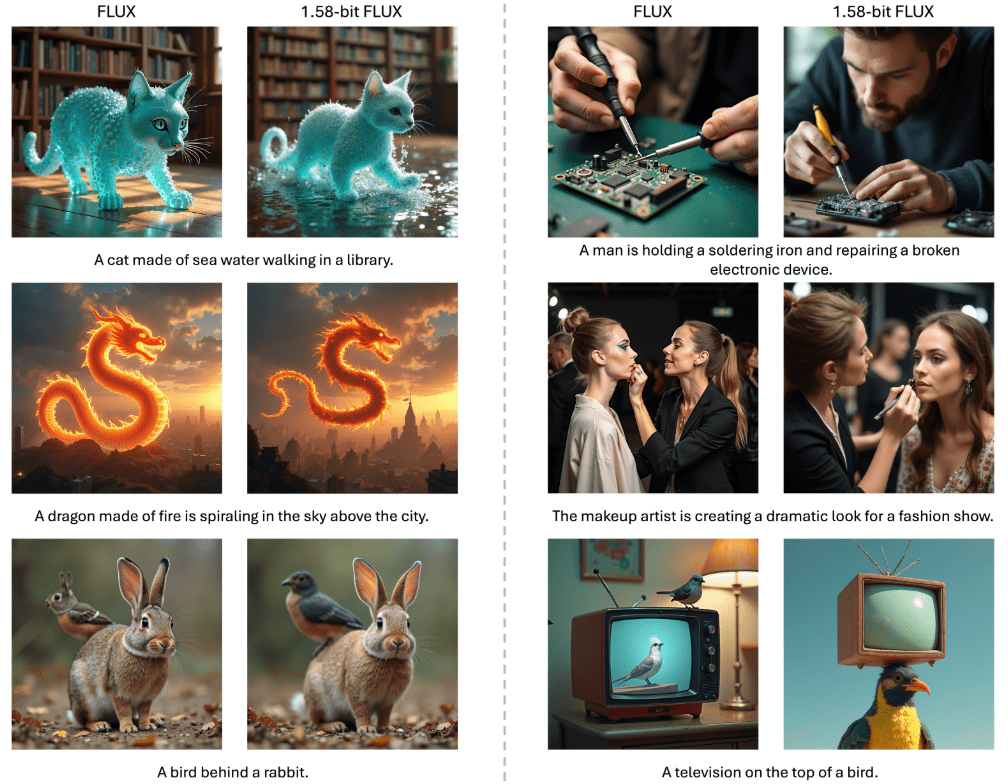
Подробные сведения о возможностях DeepSeek-R1 и китайский отчет об оценке

скорочтение
Опыт:DeepSeek Официальный сайт: chat.deepseek.com Общайтесь с DeepSeek-R1 и включайте кнопку "Глубокое мышление". Посетите API, совместимый с форматом OpenAI .
Благополучие:Развертывание модели DeepSeek-R1 с открытым исходным кодом в режиме онлайн с использованием бесплатных мощностей GPU , иРаздача 100$ кредитов DeepSeek-R1, иТоп-5 платформ для выводов ИИ, которые используют полнокровную версию DeepSeek-R1 бесплатно
Рецидив:Недавние попытки воспроизвести Проектов для DeepSeek-R1 довольно много, поэтому следите за следующими статьями:TinyZero: недорогая репликация эффекта прозрения DeepSeeK-R1 Zero , иOpen R1: обнимающееся лицо повторяет процесс обучения DeepSeek-R1 , иРепликация DeepSeek-R1: 8K математических примеров помогают маленьким моделям достичь прорыва в выводах благодаря обучению с подкреплением Это еще не все:R1 Overthinker: заставляем модели DeepSeek R1 думать дольше .
Резюме:Длина контекста: 128 К, $2,19 за миллион выходных токенов (Poundland в мире больших моделей), производительность на уровне OpenAI-o1, все модели с открытым исходным кодом свободно распространяются и используются на коммерческой основе, фантазийный функционал фронтэнда для написания текстов
Базовая модель: И DeepSeek-R1-Zero, и DeepSeek-R1 обучены на базе DeepSeek-V3-Base, а DeepSeek-R1 дополнен небольшим количеством длинных данных CoT, что делает вывод более структурированным и понятным.
Дистилляционные модели (общее усовершенствование существующих возможностей миниатюр с открытым исходным кодом): Разбивка DeepSeek-R1 на несколько небольших моделей, которые ( Оллама (доступно для скачивания)

Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, Llama-3.3-70B-Инструкция
Поток обучения DeepSeek-R1(-Zero)
- Холодный старт: тонкая настройка на примере CoT
- Разумное обучение с подкреплением: добавление вознаграждения за лингвистическую последовательность
- Генерация данных: создано 80 10 000 обучающих образцов
- Обучение с максимальным подкреплением: сбалансированные компетенции (как рассуждения, так и общие) с помощью смешанной обратной связи

Проблема в том, что длина контекста API может оказаться недостаточной для программирования

Оценка эталонов
Сильные навыки рассуждения:
Хорошо справляется с математическими задачами, достигая производительности, сравнимой с OpenAI-01-1217. Получил неожиданно высокий результат (97,3%) в бенчмарке MATH-500.
Сильные результаты в задачах на алгоритмы кодирования, таких как Codeforces и LiveCodeBench.
Демонстрирует сильные способности в задачах, требующих сложных рассуждений, таких как FRAMES.
Сильные возможности общего назначения:
Отличная производительность в таких основанных на знаниях бенчмарках, как MMLU, MMLU-Pro и GPQA Diamond.
Кроме того, он отлично справлялся с письменными заданиями, отвечал на открытые вопросы и выполнял множество других задач.
Отличные показатели победы в таких бенчмарках, как AlpacaEval 2.0 и ArenaHard, демонстрирующие, что он грамотно обрабатывает запросы, не связанные с экзаменами.
Способность составлять краткие резюме и избегать предвзятого отношения к объему информации.
Хорошая читаемость:При использовании данных холодного старта и особой конструкции в процессе обучения результаты DeepSeek-R1 легче читать, они имеют правильный формат и структуру.
Многоязычие:Хотя в настоящее время он оптимизирован в основном для китайского и английского языков, он демонстрирует некоторую способность обрабатывать запросы на нескольких языках.
Способность следовать инструкциям:Он показал отличные результаты в бенчмарке IF-Eval, продемонстрировав способность понимать и выполнять инструкции.
Способность к саморазвитию:Благодаря обучению с подкреплением модели могут автономно обучаться и улучшать свои способности к рассуждениям, а также решать сложные задачи, увеличивая время на обдумывание.
Отличный потенциал для дистилляции:DeepSeek-R1 можно использовать в качестве модели-учителя для дистилляции мощности выводов в более мелкие модели, и дистиллированные модели имеют отличную производительность, например, DeepSeek-R1-Distill-Qwen-32B, которая значительно превосходит другие модели в нескольких бенчмарках.
О возможностях местного программирования
Если вы считаете, что v3 достаточно хорош для программирования, то какая модель дистилляции является альтернативой настольной? По сравнению с DeepSeek V3, какая модель дистилляции сопоставима? Согласно оценке LiveCodeBench, DeepSeek V3 набирает 42,2 балла, а модель дистилляции Qwen 14B - 53,1 балла, которая обладает сопоставимой производительностью и сравнительно небольшим размером класса для настольных компьютеров, и рекомендуется использовать 14B на настольных компьютерах.
DeepSeek-R1: мотивация LLM-рассуждений с помощью обучения с подкреплением.
Опубликовано DeepSeek-AI
Оригинал: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
рефераты
Мы представляем наше первое поколение моделей вывода, DeepSeek-R1-Zero и DeepSeek-R1. DeepSeek-R1-Zero, модель, обученная с помощью крупномасштабного обучения с подкреплением (RL) без начального шага тонкой настройки под наблюдением (SFT), демонстрирует превосходный вывод. С помощью RL модель DeepSeek-R1-Zero естественным образом приобретает множество мощных и интересных моделей умозаключений. Однако он также сталкивается с некоторыми проблемами, такими как плохая читаемость и смешение языков. Для решения этих проблем и дальнейшего повышения эффективности умозаключений мы представляем DeepSeek-R1, который сочетает в себе многоступенчатое обучение и холодный старт данных перед RL. DeepSeek-R1 достигает производительности, сравнимой с OpenAI-01-1217 в задачах вывода. Для поддержки исследовательского сообщества мы открыли исходный код DeepSeek-R1-Zero, DeepSeek-R1 и шести плотных моделей (1.5B, 7B, 8B, 14B, 32B, 70B), основанных на доработках Qwen и Llama.

Рис. 1 | Производительность бенчмарка DeepSeek-R1.
каталог (на жестком диске компьютера)
1 Введение
1.1 Взносы
1.2 Краткое изложение результатов оценки
2 Методология
2.1 Обзор
2.2 DeepSeek-R1-Zero: обучение с подкреплением на основе фундаментальных моделей
2.2.1 Улучшенный алгоритм обучения
2.2.2 Моделирование стимулов
2.2.3 Шаблоны для обучения
2.2.4 Производительность DeepSeek-R1-Zero, процессы самоэволюции и моменты прозрения
2.3 DeepSeek-R1: обучение с подкреплением с холодного старта
2.3.1 Холодный запуск
2.3.2 Разумно-ориентированное обучение с подкреплением
2.3.3 Отказ от отбора проб и контроль за тонкой настройкой
2.3.4 Обучение с подкреплением для всех сценариев
2.4 Дистилляция: расширение небольших моделей с помощью рассуждений
3 эксперимента
3.1 Оценка DeepSeek-R1
3.2 Оценка моделирования дистилляции
4 Обсуждение
4.1 Дистилляция против интенсивного обучения
4.2 Неудачные попытки
5 Выводы, ограничения и будущая работа
1. Введение
В последние годы крупномасштабные языковые модели (LLM) подвергаются быстрой итерации и развитию (Anthropic, 2024; Google, 2024; OpenAI, 2024a), постепенно закрывая брешь, ведущую к искусственному общему интеллекту (AGI).
В последнее время посттренинг стал важной частью полного процесса обучения. Было показано, что оно повышает точность задач рассуждения, согласуется с общественными ценностями и адаптируется к предпочтениям пользователя, при этом требуя относительно мало вычислительных ресурсов по сравнению с предварительным обучением. Что касается мощности рассуждений, то в семействе моделей o1 (OpenAI, 2024b) OpenAI впервые ввел масштабирование при рассуждениях за счет увеличения длины цепочки рассуждений. Этот подход привел к значительному прогрессу в различных задачах рассуждений, таких как математические, кодовые и научные рассуждения. Однако проблема эффективного масштабирования времени тестирования остается открытым вопросом для исследовательского сообщества. В некоторых предыдущих работах исследовались различные подходы, включая модели вознаграждения на основе процессов (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023), обучение с подкреплением (Kumar et al., 2024) и алгоритмы поиска, такие как поиск по дереву Монте-Карло и поиск по пучкам (Feng et al., 2024; Trinh et al., 2024). 2024; Trinh et al.). Однако ни один из этих методов не смог достичь производительности обобщенного вывода, сравнимой с семейством моделей o1 в OpenAI.
В этой статье мы делаем первый шаг к улучшению способности языковых моделей к рассуждениям с помощью чистого обучения с подкреплением (RL). Наша цель - исследовать потенциал LLM для развития способности рассуждать без каких-либо контролируемых данных, сосредоточившись на саморазвитии с помощью чистого RL-процесса. В частности, мы используем DeepSeek-V3-Base в качестве базовой модели и GRPO (Shao et al., 2024) в качестве RL-фреймворка для улучшения производительности модели в рассуждениях. В процессе обучения в DeepSeek-R1-Zero естественным образом возникает множество мощных и интересных моделей умозаключений. После тысяч шагов RL DeepSeek-R1-Zero демонстрирует отличную производительность в эталонных тестах на умозаключения. Например, AIME 2024的pass@1得分从15.6%提高到71.0%, и путем голосования большинством голосов оценка была улучшена до 86.7%, достигнув уровня OpenAI-01-0912.
Однако DeepSeek-R1-Zero сталкивается с такими проблемами, как плохая читаемость и смешение языков. Для решения этих проблем и дальнейшего повышения эффективности умозаключений мы представляем DeepSeek-R1, который сочетает в себе небольшой объем данных холодного старта и многоступенчатый процесс обучения. В частности, сначала мы собираем тысячи данных холодного старта для точной настройки модели DeepSeek-V3-Base. После этого мы выполняем ориентированную на выводы RL, аналогичную DeepSeek-R1-Zero. Когда процесс RL приближается к сходимости, мы создаем новые данные SFT путем отбраковки контрольных точек RL, объединяем их с контролируемыми данными из DeepSeek-V3 в областях письма, фактологического опроса и самоанализа, а затем повторно обучаем модель DeepSeek- V3-Base. После тонкой настройки с учетом новых данных эта контрольная точка проходит дополнительный RL-процесс, который учитывает сигналы из всех сценариев. После этих шагов мы получаем контрольную точку под названием DeepSeek-R1, которая по производительности сопоставима с OpenAI-01-1217.
Далее мы исследовали дистилляцию из DeepSeek-R1 на более мелких плотных моделях. Используя Qwen 2.5-32B (Qwen, 2024b) в качестве базовой модели, дистилляция непосредственно из DeepSeek-R1 превзошла применение RL поверх нее, что говорит о том, что паттерны вывода, найденные в более крупной базовой модели, являются критическими для улучшения вывода. Для дистилляции мы открыли семейство моделей Qwen и Llama (Dubey et al., 2024). Примечательно, что наша дистиллированная модель 14B существенно превосходит современную модель с открытым исходным кодом QwQ-32B-Preview (Qwen, 2024a), а дистиллированные модели 32B и 70B устанавливают новый рекорд по показателям умозаключений в плотных моделях.
1.1 Взносы
Посттренинг: крупномасштабное обучение с подкреплением на основе базовых моделей
- Мы применяем Reinforcement Learning (RL) непосредственно к базовой модели, не полагаясь на Supervised Fine-Tuning (SFT) в качестве предварительного шага. Такой подход позволяет модели исследовать цепочки мышления (ЦМ) для решения сложных задач, что приводит к разработке DeepSeek-R1-Zero. DeepSeek-R1-Zero демонстрирует способность к самооценке, рефлексии и развитию ЦМ, что является важной вехой для исследовательского сообщества. В частности, это первое публичное исследование, подтверждающее, что способность к рассуждениям LLM может быть мотивирована чистым RL без необходимости в SFT.
- Мы описываем процесс, использованный для разработки DeepSeek-R1. Процесс состоит из двух этапов RL, направленных на обнаружение улучшенных моделей рассуждений и их согласование с предпочтениями человека, и двух этапов SFT, которые служат исходными данными для создания рассуждающих и не рассуждающих возможностей модели. Мы считаем, что этот процесс принесет пользу отрасли благодаря созданию более совершенных моделей.
Дистилляция: маленькие модели могут быть мощными
- Мы демонстрируем, что шаблоны выводов из больших моделей могут быть дистиллированы в меньшие модели, что обеспечивает лучшую производительность по сравнению с шаблонами выводов, обнаруженными с помощью RL на малых моделях. DeepSeek-R1 с открытым исходным кодом и его API помогут исследовательскому сообществу в будущем создавать более совершенные небольшие модели.
- Используя данные для выводов, сгенерированные DeepSeek-R1, мы провели тонкую настройку нескольких плотных моделей, широко используемых в исследовательском сообществе. Результаты оценки показывают, что отобранные небольшие плотные модели показывают хорошие результаты в бенчмарках.DeepSeek-R1-Distill-Qwen-7B достигает 55.51 TP3T на AIME 2024, превосходя QwQ-32B-Preview.Кроме того, DeepSeek-R1-Distill-Qwen-32B набрал 72.6% на AIME 2024, 94.3% на MATH-500 и 57.2% на LiveCodeBench. Эти результаты значительно лучше, чем у предыдущих моделей с открытым исходным кодом, и сравнимы с o1-mini. Мы предоставили сообществу открытый доступ к контрольным точкам дистилляции 1.5B, 7B, 8B, 14B, 32B и 70B, основанным на сериях Qwen2.5 и Llama3.
1.2 Краткое изложение результатов оценки
- Задачи на вывод: (1) DeepSeek-R1 получил оценку pass@1 79,81 TP3T на AIME 2024, немного превзойдя OpenAI-o1-1217. На MATH-500 он получил впечатляющую оценку 97,31 TP3T, что сравнимо с результатами OpenAI-o1-1217 и значительно лучше, чем у других моделей. моделей. (2) В задачах, связанных с кодированием, DeepSeek-R1 продемонстрировал экспертный уровень в задаче соревнования по коду: он набрал 2 029 баллов Elo на Codeforces, превзойдя по этому показателю человека, участвовавшего в соревновании с результатом 96,31 TP3T. В инженерных задачах DeepSeek-R1 показал себя немного лучше, чем DeepSeek-V3, который помогает разработчикам работать в реальном мире.
- **** знаний: в таких бенчмарках, как MMLU, MMLU-Pro и GPQA Diamond, DeepSeek-R1 достигает выдающихся результатов, значительно превосходя DeepSeek-V3, набрав 90.8% в MMLU, 84.0% в MMLU-Pro и GPQA Diamond. Несмотря на то, что в этих бенчмарках DeepSeek-R1 немного уступает OpenAI-01-1217, он превосходит другие закрытые модели, демонстрируя свое конкурентное преимущество в образовательных задачах. В фактологическом бенчмарке SimpleQA DeepSeek-R1 превосходит DeepSeek-V3, демонстрируя свою способность обрабатывать запросы, основанные на фактах. Аналогичная тенденция наблюдается и в OpenAI-o1 и 4o для этого бенчмарка.
- Прочее: DeepSeek-R1 также отлично справился с различными заданиями, включая творческое письмо, ответы на общие вопросы, редактирование, подведение итогов и другие. В AlpacaEval 2.0 он показал результат 87,61 TP3T, а в ArenaHard - 92,31 TP3T, продемонстрировав способность интеллектуально обрабатывать запросы, не связанные с экзаменами. Кроме того, DeepSeek-R1 отлично справляется с задачами, требующими понимания длинного контекста, и значительно превосходит DeepSeek-V3 в бенчмарках с длинным контекстом.
2. Методология
2.1 Обзор
Предыдущие работы в значительной степени опирались на большие объемы контролируемых данных для улучшения производительности модели. В этом исследовании мы демонстрируем, что вывод может быть значительно улучшен с помощью крупномасштабного обучения с подкреплением (RL), даже без использования контролируемой тонкой настройки (SFT) в качестве холодного старта. Более того, производительность может быть еще больше увеличена за счет включения небольшого количества данных холодного старта. В следующих разделах мы представляем (1) DeepSeek-R1-Zero, который применяет RL непосредственно к базовой модели без каких-либо данных SFT, и (2) DeepSeek-R1, который применяет RL, начиная с контрольных точек, точно настроенных с помощью тысяч длинных примеров Цепочки Мыслей (CoT). и (3) распределение мощности вывода DeepSeek-R1 в небольшие плотные модели.
2.2 DeepSeek-R1-Zero: обучение с подкреплением на основе фундаментальных моделей
Обучение с подкреплением показало значительную эффективность в задачах вывода, что было продемонстрировано в наших предыдущих работах (Shao et al., 2024; Wang et al., 2023). Однако эти задачи в значительной степени зависят от контролируемых данных, сбор которых занимает много времени. В этом разделе мы исследуем потенциал LLM для развития способностей к рассуждениям без каких-либо контролируемых данных, сосредоточившись на саморазвитии с помощью чистого процесса обучения с подкреплением. Мы начнем с краткого обзора нашего алгоритма обучения с подкреплением, а затем представим несколько интересных результатов, которые, как мы надеемся, станут ценным вкладом в развитие сообщества.
Групповая относительная оптимизация стратегии Чтобы сократить затраты на обучение RL, мы используем групповую относительную оптимизацию стратегии (GRPO) (Shao et al., 2024), которая отказывается от модели критики, которая обычно имеет тот же размер, что и модель стратегии, и вместо этого оценивает базовую линию по групповым оценкам. В частности, для каждой задачи q GRPO выбирает набор выходов {o1, o2,..., oG} из старой стратегии πθold и затем оптимизирует модель стратегии πθ, максимизируя следующую цель:

где ɛ и β - гиперпараметры, а Ai - доминирование, используя вознаграждения, соответствующие выходам в каждой группе {r1,r2, . . . , rG} для вычислений:

Вознаграждение - это источник обучающего сигнала, который определяет направление оптимизации RL. Для обучения DeepSeek-R1-Zero мы используем систему вознаграждений, основанную на правилах, которая состоит из следующих двух основных типов вознаграждений:
- Вознаграждение за точность: модели вознаграждения за точность оценивают правильность ответа. Например, для математических задач с детерминированными результатами модель должна предоставлять окончательный ответ в определенном формате (например, в рамке), чтобы можно было надежно проверить правильность ответа на основе правил. Аналогично, для задач LeetCode компилятор можно использовать для генерации обратной связи на основе заранее определенных тестовых примеров.
- Вознаграждение за формат: в дополнение к модели вознаграждения за точность мы использовали модель вознаграждения за формат, которая заставляет модель поместить мыслительный процесс между метками '' и ''.
Мы не использовали нейронные модели вознаграждения результатов или процессов при разработке DeepSeek-R1-Zero, потому что обнаружили, что нейронные модели вознаграждения могут страдать от "взлома" вознаграждения во время крупномасштабного обучения с подкреплением, и что переобучение модели вознаграждения требует дополнительных ресурсов для обучения, что может усложнить общий процесс обучения.
Для обучения DeepSeek-R1-Zero мы сначала разработали простой шаблон, который предписывает базовой модели следовать указанным нами инструкциям. Как показано в таблице 1, этот шаблон требует от DeepSeek-R1-Zero сначала сгенерировать процесс рассуждения, а затем окончательный ответ. Мы намеренно ограничили ограничения этим структурным форматом, чтобы избежать любых специфических для содержания предубеждений, таких как принуждение к рефлексивным рассуждениям или поощрение конкретных стратегий решения проблем, и обеспечить точное наблюдение за естественным развитием модели в процессе обучения с подкреплением (RL).
用户与助手之间的对话。用户提出一个问题,助手解决该问题。
助手首先在脑海中思考推理过程,然后为用户提供答案。
推理过程和答案分别用 <think> </think> 和 <answer> </answer> 标签括起来,即:
<think> 此处为推理过程 </think>
<answer> 此处为答案 </answer>。
用户:提示。助手:
Таблица 1 | Шаблоны для DeepSeek-R1-Zero. Во время обученияпривлекать внимание к чему-л.будет заменена конкретной проблемой рассуждения.
Производительность DeepSeek-R1-Zero На рисунке 2 показана траектория производительности DeepSeek-R1-Zero на эталоне AIME 2024 в процессе обучения с применением подкрепления (RL). Как видно, производительность DeepSeek-R1-Zero постоянно растет по мере обучения RL. Примечательно, что средний балл pass@1 в AIME 2024 демонстрирует значительный рост: с первоначальных 15,61 TP3T до впечатляющих 71,01 TP3T, достигнув уровня производительности, сопоставимого с OpenAI-01-0912. Это значительное улучшение подчеркивает эффективность нашего алгоритма RL в оптимизации производительности модели.
В таблице 2 представлен сравнительный анализ модели DeepSeek-R1-Zero и модели OpenAI o1-0912 на различных эталонах, связанных с умозаключениями. Результаты показывают, что RL делает

Таблица 2 | Сравнение моделей DeepSeek-R1-Zero и OpenAI o1 на бенчмарках, связанных с выводами.

Рис. 2 | Точность AIME для DeepSeek-R1-Zero во время обучения. Для каждой задачи мы выбирали 16 ответов и рассчитывали общую среднюю точность, чтобы обеспечить стабильность оценки.
DeepSeek-R1-Zero достигает мощных выводов без какой-либо контролируемой тонкой настройки данных. Это значительное достижение, поскольку оно подчеркивает способность модели эффективно обучаться и обобщать данные только с помощью RL. Более того, производительность DeepSeek-R1-Zero может быть еще больше увеличена за счет применения голосования по большинству голосов. Например, при использовании голосования по большинству голосов в бенчмарках AIME производительность DeepSeek-R1-Zero повышается с 71,01 TP3T до 86,71 TP3T, что превосходит производительность OpenAI-01-0912. подчеркивает ее сильные базовые возможности и потенциал для дальнейшего развития в задачах рассуждения.
Самоэволюционный процесс DeepSeek-R1-Zero Самоэволюционный процесс DeepSeek-R1-Zero - это захватывающая демонстрация того, как RL может побудить модели к автономному улучшению своих рассуждений. Запуская RL непосредственно из базовой модели, мы можем внимательно следить за прогрессом модели, не подвергая ее контролируемой фазе тонкой настройки. Такой подход позволяет получить четкое представление о том, как модель развивается со временем, особенно в плане ее способности решать сложные задачи рассуждения.
Как показано на рисунке 3, время мышления DeepSeek-R1-Zero постоянно улучшается на протяжении всего процесса обучения. Это улучшение не является результатом внешней настройки, а скорее внутренним развитием модели. DeepSeek-R1-Zero естественным образом приобретает способность решать все более сложные задачи рассуждения, используя расширенные вычисления в тестовом времени. Эти вычисления варьируются от генерации сотен до тысяч лексем, что позволяет модели глубже исследовать и совершенствовать свои мыслительные процессы.
Один из наиболее поразительных аспектов этой самоэволюции - появление сложных моделей поведения по мере увеличения вычислений в процессе тестирования. Рефлексия - то есть пересмотр и переоценка моделью своих предыдущих шагов - а также исследование альтернативных подходов к решению задач - возникают спонтанно. Это поведение не запрограммировано явно, а возникает в результате взаимодействия модели со средой обучения с подкреплением. Такое спонтанное развитие значительно расширяет возможности DeepSeek-R1-Zero в области рассуждений, позволяя ей решать более сложные задачи с большей эффективностью и точностью.

Рис. 3 | Средняя длина ответа DeepSeek-R1-Zero на обучающем наборе RL-процессов. DeepSeek-R1-Zero естественным образом учится решать задачи умозаключения, затрачивая больше времени на обдумывание.
Моменты прозрения в DeepSeek-R1-Zero Особенно интересным явлением, наблюдаемым во время обучения DeepSeek-R1-Zero, является возникновение "моментов прозрения". Как показано в таблице 3, этот момент возникает в промежуточной версии модели. На этом этапе DeepSeek-R1-Zero учится выделять больше времени на обдумывание проблемы, переоценивая свой первоначальный подход. Такое поведение - не только свидетельство растущих возможностей модели в области умозаключений, но и интересный пример того, как обучение с подкреплением может приводить к неожиданным и сложным результатам.

Таблица 3 | Интересный "момент прозрения" в промежуточной версии DeepSeek-R1-Zero. Модель учится переосмысливать, используя антропоморфный тон. Это был и наш собственный момент прозрения, позволивший нам убедиться в силе и красоте обучения с подкреплением.
Этот момент стал "прозрением" не только для модели, но и для исследователей, наблюдавших за ее поведением. Он подчеркивает силу и красоту обучения с подкреплением: вместо того чтобы явно учить модель, как решать проблему, мы просто даем ей нужные стимулы, и она автономно разрабатывает передовые стратегии решения проблем. Этот "момент прозрения" - мощное напоминание о потенциале RL для раскрытия новых уровней интеллекта в системах ИИ, прокладывая путь к созданию более автономных и адаптивных моделей в будущем.
Недостатки DeepSeek-R1-Zero Хотя DeepSeek-R1-Zero демонстрирует сильные способности к рассуждениям и автономно разрабатывает неожиданные и мощные модели поведения, он также сталкивается с некоторыми проблемами. Например, DeepSeek-R1-Zero сталкивается с проблемой плохой читаемости и смешения языков. Чтобы сделать процесс рассуждений более читаемым и поделиться им с открытым сообществом, мы исследовали DeepSeek-R1 - подход, использующий RL с удобными для человека данными холодного старта.
2.3 DeepSeek-R1: обучение с подкреплением с холодного старта
Вдохновленные многообещающими результатами DeepSeek-R1-Zero, мы задались двумя естественными вопросами: 1) Можно ли еще больше повысить эффективность выводов или ускорить сходимость, используя небольшой объем высококачественных данных в качестве "холодного старта"? и 2) Как обучить удобную модель, которая не только создает четкие и последовательные цепочки мыслей (CoTs), но и демонстрирует сильные способности к обобщению? Чтобы ответить на эти вопросы, мы разработали процесс обучения DeepSeek-R1. Процесс состоит из четырех этапов, описанных ниже.
В отличие от DeepSeek-R1-Zero, чтобы предотвратить раннюю нестабильную фазу холодного старта, когда обучение RL начинается с базовой модели, для DeepSeek-R1 мы создали и собрали небольшое количество длинных CoT-данных для точной настройки модели в качестве начального участника RL. Для сбора таких данных мы исследовали несколько подходов: использование нескольких примеров подсказок с длинными CoT в качестве примеров, прямое побуждение модели к генерированию подробных ответов с размышлением и проверкой, сбор выходных данных DeepSeek-R1-Zero в читаемом формате и постобработка результатов с помощью человеческих аннотаторов.
В этой работе мы собрали тысячи данных холодного старта для точной настройки DeepSeek-V3-Base в качестве отправной точки для RL. Преимущества данных холодного старта по сравнению с DeepSeek-R1-Zero включают:
- Читабельность: основным ограничением DeepSeek-R1-Zero является то, что его содержимое часто не читается. В ответах может смешиваться несколько языков или отсутствовать форматирование разметки, используемое для выделения ответов пользователя. Поэтому при создании данных холодного старта для DeepSeek-R1 мы разработали удобную для чтения схему, которая включает резюме в конце каждого ответа и отсеивает ответы, не поддающиеся прочтению. Здесь мы определяем формат вывода как | special_token | | special_token |
, где процесс рассуждения - это CoT запроса, а резюме используется для обобщения результатов рассуждения. - Потенциал: Используя человеческий фактор для создания модели для данных холодного старта, мы наблюдаем лучшую производительность по сравнению с DeepSeek-R1-Zero. Мы утверждаем, что итеративное обучение - лучший способ рассуждать о моделях.
После тонкой настройки DeepSeek-V3-Base на данных холодного старта мы применили тот же крупномасштабный процесс обучения с подкреплением, который использовался в DeepSeek-R1-Zero. Основное внимание на этом этапе было уделено расширению возможностей модели в области умозаключений, особенно в задачах, требующих умозаключений, таких как кодирование, математические, научные и логические рассуждения с явными вопросами. В процессе обучения мы заметили, что CoT часто демонстрирует смешение языков, особенно когда сигналы RL включают несколько языков. Чтобы смягчить проблему смешения языков, мы ввели вознаграждение за лингвистическое выравнивание в процессе обучения РЛ, которое рассчитывалось как доля слов на целевом языке в КоТ. Хотя эксперименты по выравниванию показывают, что такое выравнивание приводит к небольшому снижению производительности модели, это вознаграждение соответствует предпочтениям человека и делает ее более читабельной. Наконец, мы объединяем вознаграждения за точность и лингвистическую согласованность в задаче рассуждения, непосредственно суммируя их, чтобы сформировать окончательное вознаграждение. Затем мы применяем обучение с применением подкрепления (RL) к точно настроенной модели до тех пор, пока она не достигнет сходимости в задаче умозаключения.
Когда RL, ориентированная на вывод, сходится, мы используем сгенерированные контрольные точки для сбора данных SFT (supervised fine-tuning) для последующих раундов. В отличие от начального холодного старта, который фокусируется в основном на рассуждениях, на этом этапе мы используем данные из других областей, чтобы расширить возможности модели в написании текстов, ролевых играх и других задачах общего назначения. В частности, мы генерировали данные и настраивали модель, как описано ниже.
Данные для умозаключений Мы собирали сигналы для умозаключений и генерировали траектории умозаключений, выполняя выборку отклонений из контрольных точек, обученных RL, как описано выше. На предыдущем этапе мы включали только те данные, которые можно было оценить с помощью вознаграждений, основанных на правилах. Однако на этом этапе мы расширяем набор данных, объединяя больше данных, некоторые из которых используют генеративные модели вознаграждения, подавая реальные метки и предсказания модели в DeepSeek-V3 для оценки. Кроме того, поскольку вывод модели иногда бывает запутанным и сложным для чтения, мы отфильтровали цепочки мыслей со смешанным языком, длинные абзацы и куски кода. Для каждой подсказки мы отбирали несколько ответов и сохраняли только правильные. В общей сложности мы собрали около 600 000 обучающих примеров, связанных с рассуждениями.
Неразумные данные Для неразумных данных, таких как письмо, опрос по фактам, самоанализ и перевод, мы используем процесс DeepSeek-V3 и повторно используем части набора данных SFT DeepSeek-V3. Для некоторых задач, не связанных с рассуждениями, мы привлекаем DeepSeek-V3 для создания потенциальных цепочек мыслей путем подсказки перед ответом на вопрос. Однако для простых запросов (например, "привет") мы не предоставляем CoT в ответе. Наконец, мы собрали в общей сложности около 200 000 обучающих образцов, не связанных с выводами.
Мы проводили тонкую настройку DeepSeek-V3-Base в течение двух периодов, используя вышеупомянутый набор данных, включающий около 800 000 образцов.
Чтобы еще больше согласовать модель с предпочтениями человека, мы реализовали второй этап обучения с подкреплением, направленный на повышение полезности и безвредности модели при постоянном улучшении ее умозаключений. В частности, мы обучаем модель, используя комбинацию сигналов вознаграждения и различных распределений подсказок. Для данных, связанных с выводами, мы придерживаемся подхода, описанного в DeepSeek-R1-Zero, который использует вознаграждения, основанные на правилах, чтобы направлять процесс обучения в областях математических, кодовых и логических рассуждений. Для общих данных мы полагаемся на модели вознаграждений, чтобы отразить предпочтения человека в сложных и детальных сценариях. Мы опираемся на процесс DeepSeek-V3 и используем схожие пары предпочтений и распределения обучающих подсказок. Чтобы быть полезными, мы фокусируемся исключительно на итоговом резюме, гарантируя, что оценка подчеркивает полезность и релевантность ответа для пользователя, сводя к минимуму вмешательство в основной процесс рассуждений. Чтобы обеспечить безвредность, мы оцениваем весь ответ модели, включая процесс рассуждения и резюме, чтобы выявить и смягчить любые потенциальные риски, предубеждения или вредное содержание, которые могли возникнуть в процессе генерации. В конечном итоге интеграция сигналов вознаграждения и различных распределений данных позволяет нам обучить модель, которая отлично справляется с рассуждениями и определяет приоритеты как полезности, так и безвредности.
2.4 Дистилляция: расширение небольших моделей с помощью рассуждений
Для того чтобы сделать более эффективными небольшие модели с возможностями вывода, как у DeepSeek-R1, мы напрямую доработали модели с открытым исходным кодом, такие как Qwen (Qwen, 2024b) и Llama (AI@Meta, 2024), используя 800 000 образцов, собранных DeepSeek-R1 (как подробно описано в §2.3.3). Наши результаты показывают, что этот простой метод дистилляции может значительно улучшить вывод небольших моделей. В качестве базовых моделей мы используем Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B и Llama-3.3-70B-Instruct. Мы выбрали Llama-3.3 из-за ее немного лучшей способности к рассуждению, чем у Llama-3.1. Llama-3.1.
Для дистилляционной модели мы применяем только SFT и не включаем этап RL, хотя объединение RL может значительно улучшить производительность модели. Наша основная цель - продемонстрировать эффективность метода дистилляции, оставив изучение этапа RL на усмотрение более широкого круга исследователей.
3. Эксперименты
бенчмаркинг Мы опубликовали результаты в MMLU (Hendrycks et al., 2020), MMLU-Redux (Gema et al., 2024), MMLU-Pro (Wang et al., 2024), C-Eval (Huang et al., 2023) и CMMLU (Li et al., 2023), IFEval (Zhou et al., 2023), FRAMES (Krishna et al., 2024), GPQA Diamond (OpenAI Diamond) (Rein et al., 2023), и IFEval (Zhou et al., 2023), FRAMES (Krishna et al., 2024), GPQA Diamond (Rein et al., 2023), SimpleQA (OpenAI, 2024c), C-SimpleQA (He et al., 2024), SWE-. Bench Verified (OpenAI, 2024d), Aider¹ , LiveCodeBench (Jain et al., 2024) (2024-08 - 2025-01), Codeforces², Chinese National High School Mathematics Olympiad (CNHSMOA) Школьная математическая олимпиада (CNMO 2024)³, и Американский пригласительный экзамен по математике 2024 (AIME 2024) (MAA, 2024). В дополнение к стандартным эталонным тестам мы используем LLM в качестве жюри для оценки производительности наших моделей в открытых генеративных задачах. В частности, мы следуем оригинальным конфигурациям AlpacaEval 2.0 (Dubois et al., 2024) и Arena-Hard (Li et al., 2024), которые используют GPT-4-Turbo-1106 в качестве жюри для парных сравнений. Здесь мы приводим только итоговые резюме для оценки, чтобы избежать предвзятости в отношении длины. Для моделей дистилляции мы приводим репрезентативные результаты на AIME 2024, MATH-500, GPQA Diamond, Codeforces и LiveCodeBench.
Советы по оценке Следуя настройкам DeepSeek-V3, стандартные бенчмарки, такие как MMLU, DROP, GPQA Diamond и SimpleQA, оцениваются с помощью подсказок из фреймворка simple-evals. Для MMLU-Redux мы используем формат подсказок Zero-Eval (Lin, 2024) в условиях нулевой выборки. Для MMLU-Pro, C-Eval и CLUE-WSC, поскольку исходные подсказки были недовыбраны, мы немного изменили их для работы с нулевой выборкой. CoT в нескольких выборках может ухудшить производительность DeepSeek-R1. Остальные наборы данных соответствуют оригинальному протоколу оценки с подсказками по умолчанию, предоставленными их создателями. Для бенчмаркинга кода и математики используется набор данных HumanEval-Mul, охватывающий восемь основных языков программирования (Python, Java, C++, C#, JavaScript, TypeScript, PHP и Bash). Производительность модели в LiveCodeBench оценивается с помощью формата CoT, а данные собираются с августа 2024 по январь 2025 года. Для оценки набора данных Codeforces использовались вопросы из 10 конкурсов Div.2, а также тестовые примеры, подготовленные экспертами, после чего были рассчитаны ожидаемые рейтинги и процентное соотношение участников. Результаты проверки SWE-Bench были получены с помощью безагентного фреймворка (Xia et al., 2024). Бенчмарки, связанные с AIDER, измерялись с помощью формата "diff", а объем вычислений DeepSeek-R1 был ограничен 32 768 токенами для каждого бенчмарка.
базовая линия (в геодезической съемке) Мы провели комплексную оценку в сравнении с несколькими мощными базовыми системами, включая DeepSeek-V3, Claude-Sonnet-3.5-1022, GPT-40-0513, OpenAI-01-mini и OpenAI-01-1217. В связи с труднодоступностью API OpenAI-01-1217 в континентальном Китае мы приводим данные о его производительности на основе официальных отчетов. Для модели дистилляции мы также сравнили модель с открытым исходным кодом QwQ-32B-Preview (Qwen, 2024a).
Создание настроек Для всех наших моделей максимальная длина генерации установлена на 32 768 лексем. Для бенчмарков, требующих выборки, мы используем температуру 0,6, значение top-p 0,95 и генерируем 64 ответа на каждый запрос, чтобы оценить pass@1.
3.1 Оценка DeepSeek-R1
Для ориентированных на образование эталонов знаний, таких как MMLU, MMLU-Pro и GPQA Diamond, DeepSeek-R1 демонстрирует более высокую производительность, чем DeepSeek-V3. Это улучшение в основном объясняется повышением точности в задачах, связанных с STEM, где значительный выигрыш достигается за счет крупномасштабного обучения с подкреплением (RL). Кроме того, DeepSeek-R1 отлично справляется с FRAMES, длинной контекстно-зависимой задачей QA, демонстрируя свои сильные возможности анализа документов. Это подчеркивает потенциал моделей вывода в задачах поиска и анализа данных, управляемых ИИ. В фактологическом бенчмарке SimpleQA DeepSeek-R1 превосходит DeepSeek-V3, демонстрируя способность обрабатывать запросы, основанные на фактах. Аналогичная тенденция наблюдалась, когда OpenAI-01 превзошел GPT-40 в этом бенчмарке. Однако в китайском бенчмарке SimpleQA DeepSeek-R1 работает не так хорошо, как DeepSeek-V3, в основном из-за своей склонности отказываться отвечать на некоторые запросы после безопасного RL. В отсутствие безопасного RL DeepSeek-R1 может достичь точности более 70%.

Таблица 4 | Сравнение DeepSeek-R1 с другими репрезентативными моделями.
DeepSeek-R1 также показал впечатляющие результаты в IF-Eval - эталонном тесте, предназначенном для оценки способности модели следовать инструкциям формата. Эти улучшения могут быть связаны с данными о следовании инструкциям, включенными в заключительные этапы контролируемой тонкой настройки (SFT) и обучения RL. Кроме того, была отмечена более высокая производительность в тестах AlpacaEval2.0 и ArenaHard, что свидетельствует о преимуществе DeepSeek-R1 в письменных задачах и ответах на вопросы в открытой области. Значительно более высокая производительность по сравнению с DeepSeek-V3 подчеркивает обобщающие преимущества крупномасштабной RL, которая не только улучшает вывод, но и производительность в различных доменах. Кроме того, DeepSeek-R1 генерирует краткие резюме, а среднее значение на ArenaHard жетон 689 и в среднем 2 218 символов на AlpacaEval 2.0. Это говорит о том, что DeepSeek-R1 избегает смещения длины при оценке на основе GPT, что еще больше подтверждает его надежность при решении различных задач.
В математических задачах производительность DeepSeek-R1 сопоставима с OpenAI-01-1217 и значительно превосходит другие модели. Аналогичная тенденция наблюдается в задачах алгоритмов кодирования, таких как LiveCodeBench и Codeforces, где модели, ориентированные на вывод, доминируют в этих бенчмарках. В инженерно-ориентированных задачах кодирования OpenAI-01-1217 превосходит DeepSeek-R1 на Aider, но достигает сопоставимой производительности на SWE Verified. Мы считаем, что производительность DeepSeek-R1 для инженерных задач будет улучшена в следующем выпуске, так как количество соответствующих обучающих данных RL на данный момент все еще очень ограничено.
3.2 Оценка моделирования дистилляции

Таблица 5 | Сравнение модели дистилляции DeepSeek-R1 с другими моделями, сопоставимыми по эталонному тесту корреляции выводов.
Как показано в таблице 5, простая дистилляция вывода DeepSeek-R1 позволяет эффективной модели DeepSeek-R1-7B (т. е. DeepSeek-R1-Distill-Qwen-7B, далее будем называть ее так) превзойти по всем параметрам неинференционные модели, такие как GPT-40-0513. DeepSeek-R1-14B превосходит QwQ-32B-Preview по всем метрикам оценки, а DeepSeek-R1-32B и DeepSeek-R1-70B значительно превосходят o1-mini в большинстве бенчмарков. Эти результаты демонстрируют большой потенциал distill. Кроме того, мы обнаружили, что применение RL к этим моделям дистилляции приводит к значительному дальнейшему улучшению. Мы считаем, что это заслуживает дальнейшего изучения, и поэтому приводим здесь только результаты для простой модели дистилляции SFT.
4. Обсуждение
4.1 Дистилляция против интенсивного обучения

Таблица 6 | Сравнение между дистилляционной моделью и моделью RL на эталоне корреляции выводов.
В разделе 3.2 мы видим, что с помощью дистилляции DeepSeek-R1 небольшие модели могут достичь впечатляющих результатов. Однако остается вопрос: можно ли обучать модели с помощью крупномасштабной RL, рассматриваемой в данной статье (без дистилляции), чтобы достичь сопоставимой производительности?
Чтобы ответить на этот вопрос, мы провели масштабное RL-обучение Qwen-32B-Base с использованием математики, кода и STEM-данных на более чем 10 000 шагов, в результате чего была создана модель DeepSeek-R1-Zero-Qwen-32B. Экспериментальные результаты (показаны на рис. 6) показывают, что базовая модель 32B после масштабного RL-обучения достигает производительности, сравнимой с производительностью QwQ-32B-Preview на сопоставимом уровне. Однако DeepSeek-R1-Distill-Qwen-32B, полученная из DeepSeek-R1, значительно превосходит DeepSeek-R1-Zero-Qwen-32B во всех бенчмарках. Таким образом, мы можем сделать два вывода: во-первых, дистилляция более мощной модели в меньшую модель дает отличные результаты В то время как более мелкие модели, опирающиеся на крупномасштабные RL, упомянутые в этой статье, требуют огромных вычислительных мощностей и могут даже не достичь эффективности дистилляции. Во-вторых, хотя стратегия дистилляции является экономичной и эффективной, для выхода за границы интеллекта могут потребоваться более мощные базовые модели и более масштабное обучение с подкреплением.
4.2 Неудачные попытки
На ранних этапах разработки DeepSeek-R1 мы также столкнулись с некоторыми неудачами и провалами. Мы рассказываем о наших неудачах здесь, чтобы сделать выводы, но это не означает, что эти методы неспособны разрабатывать эффективные модели вывода.
Моделирование вознаграждения за процесс (PRM) PRM - это разумный способ направить модели на принятие лучших методов решения задач рассуждения (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023). На практике, однако, существуют три основных ограничения PRM, которые могут помешать его окончательному успеху. Во-первых, сложно явно определить тонкие шаги в общих рассуждениях. Во-вторых, определение того, является ли текущий промежуточный шаг правильным, представляет собой сложную задачу. Автоматическое аннотирование с помощью моделей может не дать удовлетворительных результатов, а ручное аннотирование не способствует масштабированию. В-третьих, после внедрения PRM на основе моделей это неизбежно приведет к взлому модели вознаграждения (Gao et al., 2022), а переобучение модели вознаграждения требует дополнительных ресурсов для обучения, что может усложнить весь процесс обучения. В итоге, хотя PRM демонстрирует хорошие возможности по упорядочиванию сгенерированных моделью ответов top-N или помощи в направленном поиске (Snell et al., 2024), его преимущества ограничены по сравнению с дополнительными вычислительными затратами, возникающими при крупномасштабном обучении с подкреплением в наших экспериментах.
Вдохновленные AlphaGo (Silver et al., 2017b) и AlphaZero (Silver et al., 2017a), мы исследовали использование Monte Carlo Tree Search (MCTS) для повышения масштабируемости вычислений во время тестирования. Этот подход предполагает декомпозицию ответа на более мелкие части, чтобы модель могла систематически исследовать пространство решений. Чтобы облегчить этот процесс, мы побуждаем модель генерировать несколько меток, которые соответствуют определенным шагам вывода, необходимым для поиска. Для обучения мы сначала используем собранные подсказки для поиска ответов с помощью MCTS, руководствуясь предварительно обученной моделью значений. Затем мы используем сгенерированные пары вопрос-ответ для обучения модели актора и модели ценности, таким образом итеративно улучшая процесс.
Однако при расширении масштабов обучения этот подход сталкивается с рядом проблем. Во-первых, в отличие от шахмат, где пространство поиска относительно хорошо определено, генерация жетонов представляет собой экспоненциально большее пространство поиска. Чтобы решить эту проблему, мы установили максимальный предел расширения для каждого узла, но это может привести к тому, что модель попадет в локальный оптимум. Во-вторых, модель значений напрямую влияет на качество генерации, поскольку она направляет каждый шаг процесса поиска. Обучение тонкой модели ценностей по своей сути сложно, что затрудняет итеративное улучшение модели. Хотя основной успех AlphaGo основан на обучении ценностных моделей для постепенного улучшения производительности, этот принцип трудно воспроизвести в наших условиях из-за сложности генерации маркеров.
В заключение следует отметить, что, хотя MCTS может улучшить производительность в процессе вывода при использовании предварительно обученных моделей значений, итеративное улучшение производительности модели в процессе самостоятельного поиска остается сложной задачей.
5. Выводы, ограничения и дальнейшая работа
DeepSeek-R1-Zero представляет собой чистый RL-подход, который не полагается на данные холодного старта и достигает высокой производительности в различных задачах. DeepSeek-R1 еще более мощный, поскольку он использует данные холодного старта и итеративную тонкую настройку RL. В итоге DeepSeek-R1 достигает производительности, сравнимой с OpenAI-01-1217, в различных задачах.
Далее мы исследовали возможность дистиллировать силу рассуждений в небольшие плотные модели. Мы использовали DeepSeek-R1 в качестве модели-учителя для генерации 800 тыс. данных и тонкой настройки нескольких небольших плотных моделей. Результаты многообещающие: DeepSeek-R1-Distill-Qwen-1.5B превосходит GPT-40 и Claude-3.5-Sonnet в тесте Maths Benchmarking Test, получая оценку AIME 28.91 TP3T и оценку MATH 83.91 TP3T. Другие плотные модели также достигли впечатляющих результатов, значительно превосходя другие модели тонкой настройки инструкций. Другие плотные модели также достигли впечатляющих результатов, значительно превосходя другие модели тонкой настройки инструкций, основанные на тех же базовых контрольных точках.
В будущем мы планируем исследовать DeepSeek-R1 в следующих областях:
- Общие возможности: в настоящее время DeepSeek-R1 менее способен, чем DeepSeek-V3, в таких задачах, как вызов функций, многораундовые диалоги, сложные ролевые игры и вывод json. В дальнейшем мы планируем изучить, как можно использовать длинные CoT для расширения задач в этих областях.
- Смешение языков: в настоящее время DeepSeek-R1 оптимизирован для китайского и английского языков, что может привести к проблемам смешения языков при обработке запросов на других языках. Например, DeepSeek-R1 может рассуждать и отвечать на английском, даже если запрос составлен на языке, отличном от английского или китайского. Мы планируем устранить это ограничение в одном из будущих обновлений.
- Разработка подсказок: Оценивая DeepSeek-R1, мы обнаружили, что он чувствителен к подсказкам. Подсказки с меньшей выборкой постоянно снижают его производительность. Поэтому мы рекомендуем пользователям напрямую описывать проблему и указывать формат вывода, используя настройку нулевой выборки для достижения наилучших результатов.
- Задачи программной инженерии: Крупномасштабная RL не нашла широкого применения в задачах программной инженерии из-за длительного времени оценки, которое влияет на эффективность процесса RL. В результате DeepSeek-R1 пока не показал значительного улучшения производительности на бенчмарках программной инженерии по сравнению с DeepSeek-V3. В будущих версиях эта проблема будет решена путем реализации выборки отбраковки на данных программной инженерии или объединения асинхронных оценок в процессе RL для повышения эффективности.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...