Команда R7B: улучшенный поиск и обоснование, многоязыковая поддержка, быстрый и эффективный генеративный ИИ


Самая маленькая модель в нашем семействе R обеспечивает высочайшую скорость, эффективность и качество для создания мощных приложений ИИ на распространенных GPU и граничных устройствах.
Сегодня мы рады выпустить Команда R7B - самая маленькая, самая быстрая и последняя модель в серии R больших языковых моделей (LLM), разработанных специально для предприятий. Command R7B обеспечивает лучшую в отрасли производительность в своем классе моделей с открытыми весами, способных решать реальные задачи, которые важны для пользователей. Модель предназначена для разработчиков и предприятий, которым необходимо оптимизировать скорость, экономическую эффективность и вычислительные ресурсы.
Как и другие модели семейства R, Command R7B имеет длину контекста 128k и превосходит другие модели в нескольких важных сценариях бизнес-приложений. Она сочетает в себе мощную многоязыковую поддержку, подтвержденную эталонами генерацию дополненного поиска (RAG), рассуждения, использование инструментов и поведение агента. Благодаря компактным размерам и эффективности он может работать на графических процессорах низкого класса, MacBook и даже на центральных процессорах, что значительно снижает стоимость внедрения приложений ИИ в производство.
Высокая производительность в небольшом корпусе
Комплексная модель
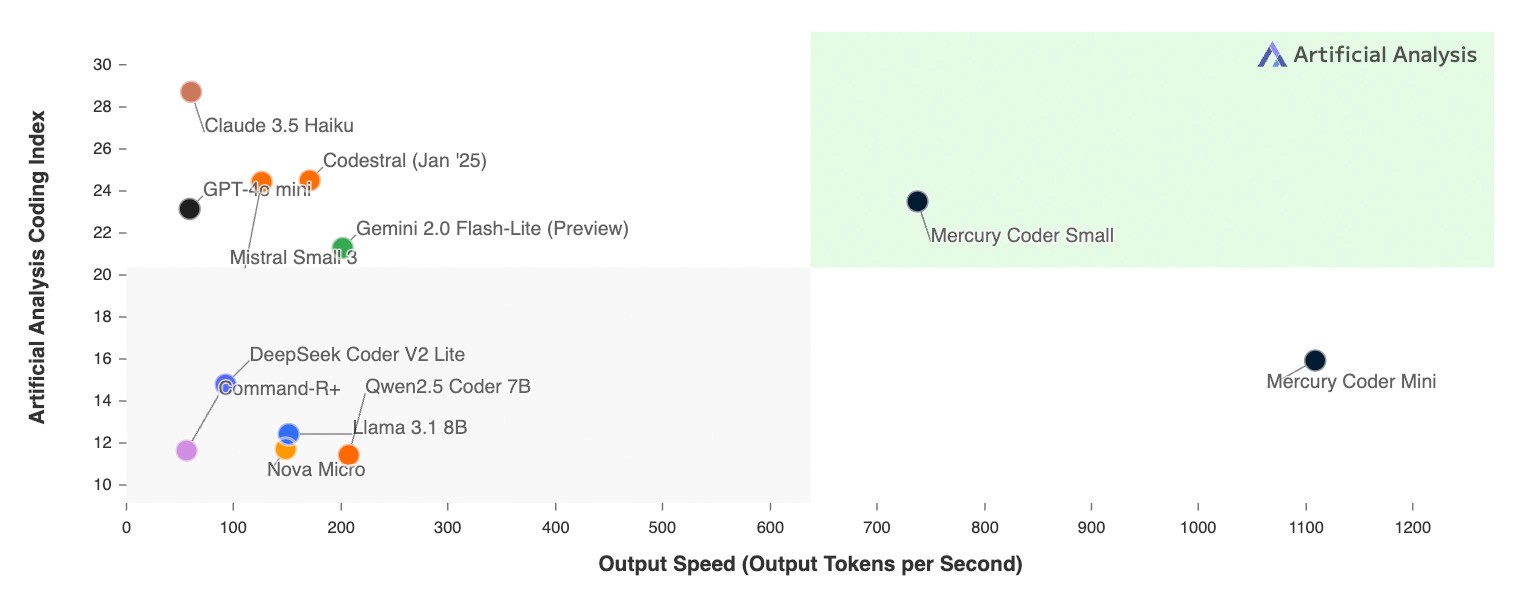
Command R7B демонстрирует высокие результаты в стандартизированных и поддающихся внешней проверке тестах, таких как Таблицы лидеров HuggingFace Open LLM. Команда R7B заняла первое место в среднем по всем заданиям, показав высокие результаты по сравнению с другими сопоставимыми моделями с открытым весом.

Результаты оценки таблицы лидеров HuggingFace. Показатели конкурентов взяты из официальных таблиц лидеров. результаты для Command R7B рассчитаны нами на основе подсказок и оценочных кодов, предоставленных официальным представителем HuggingFace.
Повышение эффективности при выполнении заданий по математике, коду и рассуждениям
Основное внимание в Command R7B уделяется улучшению производительности в математике и рассуждениях, написании кода и многоязычных задачах. В частности, модель способна сравняться или превзойти производительность сопоставимых моделей с открытыми взвешенными параметрами на распространенных эталонных задачах по математике и написанию кода, используя при этом меньшее количество параметров.

Модельные показатели по математике и коду. Все данные взяты из внутренних оценок, цифры, отмеченные звездочкой, относятся к внешним результатам, которые выше. Мы используем базовую версию MBPPPlus, LBPP усреднен по 6 языкам, SQL усреднен по 3 наборам данных (секции повышенной и сверхповышенной сложности SpiderDev и Test only, BirdBench и внутренний набор данных), а COBOL - это набор данных, который мы разработали своими силами.

Качество перевода документов (с помощью метрики spBLEU корпуса) оценивается с помощью набора данных NTREX.
Лучший в своем классе RAG, использование инструментов и интеллигентность
Command R7B превосходит другие открытые модели взвешивания сопоставимого размера в работе с основными видами деятельности, такими как RAG, использование инструментов и искусственный интеллект. Она идеально подходит для организаций, которым нужна экономически эффективная модель, основанная на внутренних документах и данных. Как и другие наши модели серии R, наши RAG Местные встроенные ссылки значительно уменьшают иллюзии и облегчают проверку фактов.

Оценка производительности на ChatRAGBench (усредненная по 10 наборам данных), BFCL-v3, StrategyQA, Bamboogle и Tooltalk-hard. Методологию и более подробную информацию см. в сноске [1] ниже.
С точки зрения использования инструментов, мы видим, что по сравнению с аналогичными масштабными моделями, Command R7B более эффективен с точки зрения промышленных стандартов Таблица лидеров по вызову функций Беркли Это показывает, что команда R7B особенно хорошо умеет использовать инструменты в разнообразных и динамичных средах реального мира и способна избегать ненужных обращений к инструментам, что является важным аспектом использования инструментов в реальных приложениях. Это свидетельствует о том, что команда R7B особенно искусна в использовании инструментов в разнообразных и динамичных средах реального мира и способна избегать ненужных вызовов инструментов, что является важным аспектом использования инструментов в реальных приложениях.Способность команды R7B использовать многоступенчатые инструменты позволяет ей поддерживать быстрый и эффективный ИИ-интеллект.
Оптимизация для корпоративного использования
Наши модели оптимизированы с учетом возможностей, необходимых организациям при развертывании систем искусственного интеллекта в реальном мире. Серия R предлагает непревзойденный баланс эффективности и надежной производительности. Command R7B превосходит аналогичные по размеру модели с открытыми весами в слепых тестах "голова к голове" на примере RAG для создания ИИ-помощников, о которых заботятся клиенты, таких как служба поддержки клиентов, HR, соблюдение нормативных требований и функции ИТ-поддержки.

При оценке на людях Command R7B тестировался в сравнении с Gemma 2 9B на выборке из 949 примеров использования RAG на предприятиях. Все примеры были слепо аннотированы не менее трех раз специально обученными аннотаторами для оценки беглости, точности и полезности ответов.
Эффективно и быстро
Компактный размер Command R7B обеспечивает небольшую площадь обслуживания для быстрого создания прототипов и итераций. Он отлично подходит для высокопроизводительных приложений реального времени, таких как чат-боты и кодовые помощники. Он также поддерживает рассуждения на стороне устройства, значительно снижая затраты на развертывание инфраструктуры, такой как графические и центральные процессоры потребительского класса.
В этом процессе мы не пошли на компромисс со стандартами безопасности и конфиденциальности корпоративного уровня, чтобы обеспечить защиту данных наших клиентов.
быстрый старт
Command R7B можно приобрести уже сегодня на сайте Платформа Cohere Его также можно использовать на HuggingFace О доступе. Мы рады выпустить весовую часть модели, чтобы предоставить сообществу исследователей ИИ более широкий доступ к передовым технологиям.
| Cohere Ценообразование API | импорт Токен | Выходной токен |
|---|---|---|
| Команда R7B | $0.0375 / 1M | $0.15 / 1M |
[1] Разговорный RAG: тест средней производительности на бенчмарке ChatRAGBench на 10 наборах данных, проверяющий способность генерировать ответы в различных условиях, включая разговорные задачи, обработку длинных вводимых данных, анализ форм, извлечение и манипулирование информацией в финансовой среде. Мы усовершенствовали методику оценки, использовав интеграцию дискриминатора PoLL (Verga et al., 2024) в сочетании с Haiku, GPT3.5 и Command R, что обеспечило более высокую согласованность (каппа Флейсса = 0,74 по сравнению с 0,57 в оригинальной версии, основанной на 20 000 ручных оценок). Использование инструмента: производительность на эталоне BFCL-v3 от 12 декабря 2024 года. Все доступные оценки взяты из публичных таблиц лидеров, в противном случае - из внутренних оценок с использованием официальной кодовой базы. Для конкурентов мы сообщаем, какой из их результатов BFCL больше - "подсказанный" или "вызывающий функции". Мы сообщаем общую оценку, оценку подмножества реального времени (тестирование использования инструментов в реальном мире, разнообразных и динамических средах) и оценку подмножества нерелевантности (тестирование того, как модель избегает ненужного вызова инструментов).REACT Agent/Multi-step: Мы оценили LangChain РЕАКТ Способность интеллектов, подключенных к Интернету, декомпозировать сложные проблемы и разрабатывать планы для успешного проведения исследований оценивалась с помощью Bamboogle и StrategyQA. Bamboogle оценивался с помощью интеграции PoLL, а StrategyQA - путем оценки того, следовала ли модель инструкциям формата и в итоге отвечала "Да ' или "Нет" для вынесения решения. Мы используем наборы тестов Chen et al. (2023) и Press et al. (2023).ToolTalk требует от модели сложных рассуждений и активного поиска информации от пользователя для выполнения сложных пользовательских задач, таких как управление учетной записью, отправка электронных писем и обновление календарей.ToolTalk-hard оценивается с помощью коэффициента успешности soft официальной библиотеки ToolTalk. ToolTalk требует от моделей API вызова функций, что недоступно в Gemma 2 9B.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...