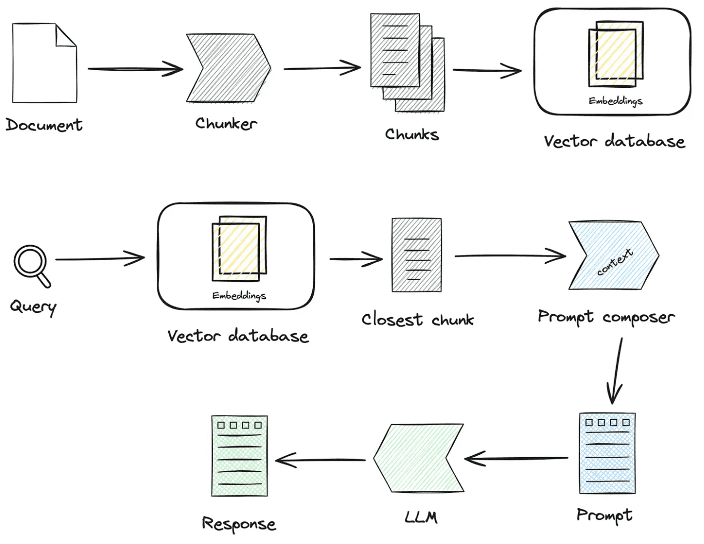
2024 Инвентаризация RAG, стратегия применения RAG 100+


В 2024 году большие модели меняются с каждым днем, и сотни разумных тел соревнуются между собой. Будучи важной частью приложений ИИ, RAG также является "группой героев и вассалов". В начале года модульный RAG продолжает набирать обороты, GraphRAG сияет, в середине года инструменты с открытым исходным кодом в полном разгаре, графы знаний создают новые возможности, а в конце года понимание графов и мультимодальный RAG начинают новое путешествие, так что это почти как "ты поешь, а я выступаю на сцене", и появляются странные техники, и список можно продолжать и продолжать!
Я выбрал типичные системы и документы RAG для 2024 года (с примечаниями AI, источниками и краткой информацией), а в конце статьи включил обзор RAG и материалы по бенчмаркингу тестов. Я надеюсь, что эта статья объемом 16 000 слов поможет вам быстро пройти RAG.
Полный текст 72 статей, месяц за месяцем в виде конспекта, крепко названного "RAG семьдесят два стиля", для того, чтобы предложить вам.
Примечания:
Все содержимое этой статьи было размещено в репозитории с открытым исходным кодом Awesome-RAG, не стесняйтесь отправлять PR для проверки пробелов.
Адрес GitHub: https://github.com/awesome-rag/awesome-rag
(01) GraphReader [Графический эксперт]
Графические экспертыОн похож на преподавателя, который умеет составлять карты мышления, превращая длинный текст в четкую сеть знаний, чтобы ИИ мог легко найти ключевые моменты, необходимые для ответа, как будто исследуя карту, эффективно преодолевая проблему "заблудиться" при работе с длинным текстом.
- Время: 01.20
- Диссертация: GraphReader: создание агента на основе графов для улучшения возможностей длинных контекстов больших языковых моделей
GraphReader - это графовая система интеллектов, предназначенная для обработки длинных текстов путем их построения в виде графа и автономного исследования этого графа с помощью интеллектов. Получив задачу, интеллектуальный орган сначала проводит пошаговый анализ и разрабатывает разумный план. Затем он вызывает набор предопределенных функций для чтения содержимого узлов и их соседей, облегчая грубое и тонкое исследование графа. В процессе исследования интеллектуальный организм постоянно фиксирует новые сведения и размышляет о текущей ситуации, оптимизируя процесс, пока не соберет достаточно информации для выработки ответа.

(02) MM-RAG [Многогранный]
разносторонний человекЭто универсальное устройство, которое одновременно владеет зрением, слухом и языком, не только понимая различные формы информации, но и свободно переключаясь и соотносясь между ними. Благодаря всестороннему пониманию различной информации он может предоставлять более интеллектуальные и естественные услуги в различных областях, таких как рекомендации, помощники и средства массовой информации.
Представлены достижения в области мультимодального машинного обучения, включая сравнительное обучение, произвольный модальный поиск, реализованный с помощью мультимодального встраивания, мультимодальный поиск с расширенной генерацией (MM-RAG) и использование векторных баз данных для построения мультимодальных производственных систем. Также рассматриваются будущие тенденции развития мультимодального ИИ, подчеркивается перспективность его применения в таких областях, как рекомендательные системы, виртуальные помощники, медиа и электронная коммерция.

(03) CRAG [самокоррекция]
самокоррекция: Подобно опытному редактору, он просто и быстро просеивает предварительную информацию, затем расширяет ее путем поиска в Интернете и, наконец, обеспечивает точность и надежность конечного контента, разбирая и реорганизуя его. Это как система контроля качества на RAG, чтобы сделать контент, который он производит, более надежным.
- Время: 01.29
- Диссертация: Коррекция Поиск Дополненное поколение
- Проект: https://github.com/HuskyInSalt/CRAG
CRAG улучшает качество найденных документов за счет разработки легкого поискового анализатора и внедрения крупномасштабного веб-поиска, а также дорабатывает полученную информацию с помощью алгоритмов декомпозиции и реорганизации для повышения точности и надежности сгенерированного текста. CRAG является полезным дополнением и усовершенствованием существующей техники RAG, которая повышает надежность сгенерированного текста за счет самокоррекции результатов поиска.

(04) RAPTOR [иерархическое обобщение]
иерархическое резюмеПодобно хорошо организованному библиотекарю, содержимое документа организовано в виде древовидной структуры снизу вверх, что позволяет гибко перемещаться между различными уровнями, как в плане общего обзора, так и в плане углубленных деталей.
- Время: 01.31
- Диссертация: RAPTOR: Recursive Abstractive Processing for Tree-Organised Retrieval
- Проект: https://github.com/parthsarthi03/raptor
RAPTOR (Recursive Abstractive Processing for Tree-Organised Retrieval) представляет новый метод рекурсивного встраивания, кластеризации и обобщения блоков текста для построения деревьев с различными уровнями обобщения снизу вверх. Во время вывода модель RAPTOR осуществляет поиск по этому дереву, объединяя информацию из длинных документов с разными уровнями абстракции.

(05) T-RAG [частный консультант]
частный консультантКак штатный консультант, знакомый с организационной структурой, он умеет организовать информацию с помощью древовидной структуры, чтобы предоставлять локальные услуги эффективно и экономично, защищая при этом конфиденциальность.
- Диссертация: T-RAG: уроки из окопов LLM
T-RAG (Tree Retrieval Augmentation Generation) объединяет RAG с точно настроенными LLM с открытым исходным кодом, использующими древовидные структуры для представления иерархий сущностей в контекстах дополнения организаций, используя локально размещенные модели с открытым исходным кодом для решения проблем конфиденциальности данных, а также для решения проблем задержки вывода, стоимости использования токенов, региональной и географической доступности.

(06) RAT [Мыслитель]
мыслительКак рефлексирующий преподаватель, вместо того чтобы сразу прийти к выводу, вы начинаете с первоначальных идей, а затем используете полученную информацию для постоянного анализа и уточнения каждого этапа процесса рассуждения, чтобы сделать цепочку мыслей более плотной и надежной.
- Диссертация: RAT: Retrieval Augmented Thoughts Elicit Контекстно-ориентированные рассуждения при генерации длинных горизонтов
- Проект: https://github.com/CraftJarvis/RAT
RAT (Retrieval Augmented Thinking) После генерации начальной цепочки мыслей с нулевой выборкой (CoT) каждый шаг мысли пересматривается индивидуально с использованием извлеченной информации, связанной с запросом задачи, текущими и прошлыми шагами мысли, и RAT значительно улучшает производительность при выполнении широкого спектра задач, требующих длительного времени генерации.

(07) РАФТ [Мастер открытой книги]
мастер открывать книгиКак хороший кандидат, вы не только найдете нужные ссылки, но и точно процитируете ключевые элементы и четко объясните ход рассуждений, чтобы ответ был одновременно и доказательным, и разумным.
- Диссертация: RAFT: адаптация языковой модели к специфике домена RAG
Цель RAFT - улучшить способность модели отвечать на вопросы в специфической для домена среде "открытых книг" путем обучения модели игнорировать нерелевантные документы и отвечать на вопросы, дословно цитируя правильные последовательности из соответствующих документов, что, в сочетании с мысленными цепочками ответов, значительно улучшает способность модели к рассуждению.

(08) Adaptive-RAG [Reaching the Right Person for the Right Job]
(идиома) преподавать в соответствии со способностями ученика: Сталкиваясь с вопросами разной сложности, он будет грамотно выбирать наиболее подходящий ответ. На простые вопросы он ответит прямо, а на сложные - с помощью дополнительной информации или пошаговых рассуждений, подобно опытному учителю, который умеет корректировать метод обучения в зависимости от конкретных проблем учеников.
- Диссертация: Adaptive-RAG: обучение адаптации больших языковых моделей, дополняющих поиск, через сложность вопросов
- Проект: https://github.com/starsuzi/Adaptive-RAG
Adaptive-RAG динамически выбирает наиболее подходящую стратегию улучшения поиска для LLM в зависимости от сложности запроса, динамически выбирая наиболее подходящую стратегию для LLM от самой простой до самой сложной. Этот процесс выбора реализуется с помощью небольшого классификатора языковой модели, который предсказывает сложность запроса и автоматически собирает метки для оптимизации процесса выбора. Этот подход обеспечивает сбалансированную стратегию, которая легко адаптируется между итеративными и одношаговыми LLM с расширенным поиском, а также методами без поиска для ряда сложностей запросов.

(09) HippoRAG [гиппокамп]
гиппокамп: Подобно лошадиному телу человеческого разума, старые и новые знания искусно сплетаются в паутину. Не просто накапливая информацию, а позволяя каждому новому знанию найти свой самый подходящий дом.
- Диссертация: HippoRAG: нейробиологически вдохновленная долговременная память для больших языковых моделей
- Проект: https://github.com/OSU-NLP-Group/HippoRAG
HippoRAG - это новая система извлечения информации, вдохновленная гиппокампальной теорией индексации долговременной памяти человека, направленная на более глубокую и эффективную интеграцию новых знаний. HippoRAG синергетически объединяет LLM, графы знаний и персонализированные алгоритмы PageRank, чтобы имитировать различные роли неокортекса и гиппокампа в человеческой памяти.

(10) RAE [интеллектуальное редактирование]
интеллектуальный редактор (программное обеспечение)Подобно внимательному редактору новостей, он или она не только докопается до соответствующих фактов, но и найдет ключевую информацию, которую легко упустить из виду, рассуждая по цепочке, и в то же время знает, как сократить избыточный контент, чтобы итоговая информация была одновременно точной и лаконичной, избегая проблемы "много говорить, но не быть достоверным".
- Диссертация: Редактирование знаний с помощью поиска в языковых моделях для многоходовых ответов на вопросы
- Проект: https://github.com/sycny/RAE
RAE (Multi-hop Q&A Retrieval Enhanced Model Editing Framework) сначала извлекает отредактированные факты, а затем оптимизирует языковую модель с помощью контекстного обучения. Подход к поиску, основанный на максимизации взаимной информации, использует возможности большой языковой модели для выявления цепочек фактов, которые могут быть пропущены при традиционном поиске по сходству. Кроме того, фреймворк включает стратегию обрезки для удаления избыточной информации из найденных фактов, что повышает точность редактирования и смягчает проблему иллюзий.

(11) RAGCache [Кладовщик]
кладовщик: Как в большом логистическом центре, размещайте часто используемые знания на полках, которые легче всего забрать. Знайте, как положить часто используемые посылки у двери, а редко используемые - в задние контейнеры, чтобы максимально повысить эффективность самовывоза.
- Диссертация: RAGCache: эффективное кэширование знаний для генерации с расширенным поиском
RAGCache - это новая многоуровневая система динамического кэширования для RAG, которая организует промежуточные состояния извлекаемых знаний в дерево знаний и кэширует их в иерархии памяти GPU и хоста. RAGCache предлагает стратегию замещения, которая учитывает особенности рассуждений LLM и шаблоны поиска RAG. Кроме того, она динамически перекрывает этапы поиска и рассуждений, чтобы минимизировать задержку между ними.

(12) GraphRAG [Резюме сообщества]
Краткие сведения о сообществах: Сначала сортируется сеть жителей микрорайона, а затем каждому кругу микрорайона дается профиль. Когда кто-то спрашивает дорогу, каждый районный круг дает подсказки, которые в итоге объединяются в наиболее полный ответ.
- Диссертация: От локального к глобальному: подход Graph RAG к резюмированию, ориентированному на запросы
- Проект: https://github.com/microsoft/graphrag
GraphRAG строит текстовые индексы на основе графов в два этапа: сначала из исходных документов составляется граф знаний о сущностях, а затем для всех групп тесно связанных сущностей предварительно генерируются краткие описания сообществ. Если задана проблема, то каждое резюме сообщества используется для создания частичного ответа, а затем все частичные ответы снова обобщаются в окончательном ответе пользователю.

(13) R4 [Мастер-хореограф]
мастер-аранжировщик: Подобно мастеру типографского дела, качество выпускаемой продукции повышается за счет оптимизации порядка и подачи материала, что делает содержание более организованным и сфокусированным без необходимости менять основную модель.
- Диссертация: R4: Усиленный ретривер-реордер-респондер для больших языковых моделей с расширением поиска
R4 (Reinforced Retriever-Reorder-Responder) используется для обучения упорядочиванию документов для большой языковой модели с расширенным поиском, что позволяет дополнительно расширить генеративные возможности большой языковой модели, при этом большое количество ее параметров остается замороженным. Процесс обучения упорядочиванию делится на два этапа, основанных на качестве генерируемых ответов: корректировка порядка документов и улучшение представления документов. В частности, корректировка порядка документов направлена на упорядочивание извлеченных документов на начальную, среднюю и конечную позиции на основе обучения внимания графа, чтобы максимизировать вознаграждение за подкрепление качества ответа. Улучшение представления документов способствует дальнейшему совершенствованию представлений документов, полученных из некачественных ответов, с помощью градиентного состязательного обучения на уровне документов.

(14) ИМ-РАГ [разговор с самим собой]
разговаривать с самим собойКогда они сталкиваются с проблемой, то мысленно вычисляют, "какую информацию мне нужно проверить" и "достаточно ли этой информации", и уточняют ответ с помощью непрерывного внутреннего диалога. Эта способность к "монологу" похожа на способность человека-эксперта, который способен глубоко мыслить и решать сложные проблемы шаг за шагом.
- Диссертация: IM-RAG: многораундовая генерация с расширенным поиском через обучение внутренним монологам
IM-RAG поддерживает несколько раундов улучшения поиска путем обучения внутренним монологам для соединения ИК-систем с LLM. Этот подход объединяет информационно-поисковую систему с большими языковыми моделями для поддержки нескольких раундов улучшения поиска путем обучения внутренним монологам. Во время внутреннего монолога большая языковая модель выступает в качестве основной модели рассуждений, которая может либо задать запрос ретриверу для сбора дополнительной информации, либо предоставить окончательный ответ, основанный на контексте диалога. Мы также вводим оптимизатор, который улучшает результаты работы ретривера, эффективно преодолевая разрыв между рассуждающей моделью и модулями поиска информации с различными возможностями, и облегчая многораундовое взаимодействие. Весь процесс внутреннего монолога оптимизируется с помощью обучения с усилением (RL), где также введен трекер прогресса для обеспечения вознаграждения за промежуточные шаги, а предсказания ответов далее оптимизируются индивидуально с помощью Supervised Fine-Tuning (SFT).

(15) AntGroup-GraphRAG [Сотни экспертов]
сто школ мыслиКомпания объединяет лучших из лучших в отрасли, специализируясь на различных способах быстрого поиска информации, обеспечивая точный поиск, а также понимая запросы на естественном языке, что делает сложный поиск знаний экономически выгодным и эффективным.
- Проект: https://github.com/eosphoros-ai/DB-GPT
Команда Ant TuGraph создала фреймворк GraphRAG с открытым исходным кодом на основе DB-GPT, который совместим с различными пьедесталами индексации баз знаний, такими как вектор, граф, полный текст и т.д., и поддерживает недорогое извлечение знаний, отображение структуры документа и абстракцию графового сообщества с гибридным поиском для решения проблем QFS Q&A. Также обеспечивается поддержка различных возможностей поиска, таких как ключевые слова, векторы и естественный язык.

(16) Котаэмон [LEGO]
Лего (игрушки)Готовый набор строительных блоков Q&A, которые можно использовать напрямую или свободно разбирать и переделывать. Пользователи могут использовать их по своему усмотрению, а разработчики могут изменять их по своему усмотрению.
- Проект: https://github.com/Cinnamon/kotaemon
Чистый и настраиваемый пользовательский интерфейс RAG с открытым исходным кодом для создания и настройки вашей собственной системы вопросов и ответов на документы. Учитываются потребности как конечных пользователей, так и разработчиков.

(17) FlashRAG [сундук с сокровищами]
сундук с сокровищами: Упаковка различных артефактов RAG в набор инструментов, позволяющий исследователям строить собственные модели поиска по мере необходимости, как будто собирая строительные блоки.
- Диссертация: FlashRAG: модульный инструментарий для эффективного исследования поколений с расширенным поиском
- Проект: https://github.com/RUC-NLPIR/FlashRAG
FlashRAG - это эффективный модульный инструментарий с открытым исходным кодом, разработанный для того, чтобы помочь исследователям воспроизводить существующие методы RAG и разрабатывать собственные алгоритмы RAG в рамках единой структуры. Наш инструментарий реализует 12 современных методов RAG, а также собирает и обобщает 32 эталонных набора данных.

(18) ГРАГ [детектив]
заниматься детективной деятельностью: Не довольствуясь поверхностными подсказками, копайте глубже в сети связей между текстами, выслеживая истину за каждым кусочком информации, как в преступлении, чтобы сделать ответ более точным.
- Диссертация: GRAG: Graph Retrieval-Augmented Generation
- Проект: https://github.com/HuieL/GRAG
Традиционные модели RAG игнорируют связи между текстами и топологическую информацию базы данных при работе со сложными графовыми данными, что приводит к снижению производительности. GRAG значительно повышает производительность и снижает иллюзии процесса поиска и генерации, подчеркивая важность подграфовых структур.

(19) Camel-GraphRAG [слева и справа]
ударить одной рукой, а затем другой, в быстрой последовательностиОдин глаз сканирует текст с помощью Mistral для извлечения информации, а другой плетет паутину взаимосвязей с помощью Neo4j. При поиске левый и правый глаза работают вместе, чтобы найти сходства, а также проследить путь по карте следов, что делает поиск более полным и точным.
- Проект: https://github.com/camel-ai/camel
Camel-GraphRAG опирается на модель Mistral для поддержки извлечения знаний из заданного контента и построения структур знаний, а затем сохраняет эту информацию в базе данных графов Neo4j. Гибридный подход, сочетающий векторный поиск и поиск по графу знаний, используется для запроса и изучения хранящихся знаний.

(20) G-RAG [Stringer]
лит. стучать в дверь (идиома); рис. чудодейственное средство от проблем людейВместо того чтобы искать информацию в одиночку, вы создаете сеть связей для каждой точки знания. Подобно светской львице, вы не только знаете, в чем хорош каждый из ваших друзей, но и знаете, кто с кем дружит, чтобы в поисках ответов идти прямо по следу.
- Доклад: Не забудьте соединить! Улучшение RAG с помощью рерайтинга на основе графиков
RAG по-прежнему сталкивается с проблемами, связанными с отношениями между документами и контекстом вопроса, и модель не может эффективно использовать документы, если их релевантность вопросу не очевидна или если они содержат лишь частичную информацию. Кроме того, важной проблемой является обоснованное определение связей между документами. G-RAG реализует графовую нейронную сеть (GNN), основанную на перестановке между ретривером RAG и читателем. Метод объединяет информацию о связях между документами и семантическую информацию (через абстрактный граф семантического представления), чтобы обеспечить ранжирование на основе контекста для RAG.

(21) LLM-Graph-Builder [Mover]
носильщик: Дайте хаотичному тексту понятный дом. Не просто несите его, а, как одержимый человек, маркируйте каждую точку знаний, рисуйте линии взаимосвязи и, наконец, создайте упорядоченное здание знаний в базе данных Neo4j.
- Проект: https://github.com/neo4j-labs/llm-graph-builder
Neo4j с открытым исходным кодом генератор извлечения графа знаний на основе LLM, который может преобразовать неструктурированные данные в граф знаний в Neo4j. Использование больших моделей для извлечения узлов, связей и их атрибутов из неструктурированных данных.

(22) МРАГ [Осьминог]
ОсьминогВместо того чтобы отрастить только одну голову для решения задачи, он отращивает множество щупалец, как осьминог, причем каждое щупальце отвечает за захват угла. Проще говоря, это версия "многозадачности" для ИИ.
- Диссертация: Multi-Head RAG: решение многоаспектных задач с помощью LLM
- Проект: https://github.com/spcl/MRAG
Существующие решения RAG не ориентированы на запросы, которые могут требовать доступа к нескольким документам с существенно отличающимся содержанием. Такие запросы возникают часто, но являются сложными, поскольку вкрапления этих документов могут находиться далеко друг от друга в пространстве вкраплений, что затрудняет их извлечение. В данной статье представлена Multihead RAG (MRAG) - новая схема, которая призвана заполнить этот пробел с помощью простой, но мощной идеи: используя Трансформатор Активация слоя внимания с несколькими головками, а не слоя декодера, служит ключом к восприятию многогранных документов. Мотивация заключается в том, что разные головки внимания могут научиться улавливать различные аспекты данных. Использование соответствующих активаций создает вкрапления, представляющие элементы данных и различные аспекты запроса, что повышает точность поиска по сложным запросам.

(23) PlanRAG [стратег]
стратег: Разрабатывается полный план сражения, затем ситуация анализируется в соответствии с правилами и данными, и, наконец, принимаются оптимальные тактические решения.
- Диссертация: PlanRAG: Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers
- Проект: https://github.com/myeon9h/PlanRAG
PlanRAG исследует, как использовать крупномасштабные языковые модели для решения сложных проблем принятия решений при анализе данных, определяя задачу Decision QA, то есть определение наилучшего решения на основе проблемы принятия решений Q, бизнес-правил R и базы данных D. PlanRAG сначала генерирует план принятия решений, а затем ретривер формирует запросы для анализа данных.

(24) FoRAG [писатель]
писательЭссе пишется в виде конспекта, который составляет основу эссе, а затем расширяется и уточняется абзац за абзацем. Также есть "редактор", который помогает отточить каждую деталь и обеспечить качество работы, тщательно проверяя факты и предлагая изменения.
- Диссертация: FoRAG: Factuality-optimised Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
FoRAG предлагает новый генератор для улучшения контуров, где генератор использует шаблоны контуров для составления контуров ответов на основе запроса пользователя и контекста на первом этапе, и расширяет каждую точку зрения на основе сгенерированного контура на втором этапе для построения окончательного ответа. Также предлагается подход к оптимизации фактов, основанный на хорошо разработанном двойном тонком фреймворке RLHF, который обеспечивает более плотные сигналы вознаграждения за счет внедрения тонкого дизайна на двух основных этапах оценки фактов и моделирования вознаграждения.

(25) Multi-Meta-RAG [мета-скринер]
мета-фильтрКак опытный менеджер данных, он использует многочисленные механизмы фильтрации, чтобы выделить наиболее релевантный контент из огромного количества информации. Он не просто смотрит на поверхность, а анализирует "идентификационные метки" (метаданные) документов, чтобы убедиться, что каждый найденный фрагмент информации действительно соответствует теме.
- Диссертация: Multi-Meta-RAG: Улучшение RAG для многоходовых запросов с помощью фильтрации баз данных и извлеченных из LLM метаданных
- Проект: https://github.com/mxpoliakov/multi-meta-rag
Multi-Meta-RAG использует фильтрацию базы данных и метаданные, извлеченные из LLM, чтобы улучшить выбор RAG релевантных документов из различных источников, имеющих отношение к проблеме.

(26) RankRAG [All Rounder]
универсальный: Немного потренировавшись, вы можете стать и "судьей", и "конкурентом". Как одаренный спортсмен, с небольшим количеством тренировок вы можете превзойти профессионалов в нескольких дисциплинах и овладеть всеми навыками.
- Диссертация: RankRAG: объединение контекстного ранжирования и генерации с расширением поиска в LLM
RankRAG's тонко настраивает один LLM с инструкциями для выполнения контекстного ранжирования и генерации ответов. При добавлении небольшого количества данных о ранжировании к обучающим данным, LLM с инструкциями работает удивительно хорошо и даже превосходит существующие экспертные модели ранжирования, включая тот же LLM, специально настроенный на большом количестве данных о ранжировании. Такая конструкция не только упрощает сложность множества моделей в традиционных системах RAG, но и улучшает оценку контекстной релевантности и эффективность использования информации за счет совместного использования параметров модели.

(27) GraphRAG-Local-UI [модификатор]
тюнер: Превращение спортивного автомобиля в практичный автомобиль для местных дорог, с дружелюбной приборной панелью, чтобы им мог управлять каждый.
- Проект: https://github.com/severian42/GraphRAG-Local-UI
GraphRAG-Local-UI - это адаптированная к локальной модели версия GraphRAG на базе Microsoft с богатой экосистемой интерактивных пользовательских интерфейсов.

(28) ThinkRAG [маленький секретарь]
младший секретарь: Сожмите огромный объем знаний в карманную версию, как маленький секретарь в дороге, готовый помочь вам найти ответы без большого устройства.
- Проект: https://github.com/wzdavid/ThinkRAG
Система ThinkRAG Big Model Retrieval Enhanced Generation System может быть легко развернута на ноутбуках, чтобы обеспечить интеллектуальный опрос локальных баз знаний.

(29) Nano-GraphRAG [легкая нагрузка]
лит. pack light and go into battle (идиома); fig. начинать работу с легким грузомКак спортсмен, собирающий вещи налегке, громоздкое оборудование было упрощено, но основные компетенции сохранены.
- Проект: https://github.com/gusye1234/nano-graphrag
Nano-GraphRAG - это более компактный, быстрый и лаконичный GraphRAG с сохранением основной функциональности.
(30) RAGFlow-GraphRAG [Навигатор]
штурман (на самолете или корабле): Проложите кратчайший путь через лабиринт вопросов и ответов, предварительно нарисовав карту, на которой отмечены все точки знания, исключив дублирующие указатели и специально сократив карту, чтобы люди, спрашивающие дорогу, не выбирали долгий путь.
- Проект: https://github.com/infiniflow/ragflow
RAGFlow опирается на реализацию GraphRAG и вводит построение графа знаний в качестве дополнительной опции на этапе предварительной обработки документа для обслуживания сценариев QFS Q&A, а также вносит такие улучшения, как де-взвешивание сущностей и оптимизация токенов.

(31) Medical-Graph-RAG [Цифровой доктор]
цифровой врачКак опытный медицинский консультант, он четко излагает сложные медицинские знания с помощью диаграмм, а диагностические предложения не делаются на пустом месте, а обосновываются, так что и врач, и пациент могут видеть, что стоит за каждым диагнозом.
- Диссертация: Medical Graph RAG: Towards Safe Medical Large Language Model through Graph Retrieval-Augmented Generation
- Проект: https://github.com/SuperMedIntel/Medical-Graph-RAG
MedGraphRAG - это фреймворк, разработанный для решения проблем, связанных с применением LLM в медицине. Он использует графовый подход для повышения точности диагностики, прозрачности и интеграции в клинические рабочие процессы. Система повышает точность диагностики, генерируя ответы, подкрепленные надежными источниками, решая проблему сохранения контекста в больших объемах медицинских данных.

(32) HybridRAG [Комбинация китайской медицины]
Рецепт китайской медициныКак и в традиционной китайской медицине (ТКМ), одно лекарство не так эффективно, как сочетание нескольких. Векторные базы данных отвечают за быстрый поиск, а графы знаний дополняют реляционную логику, дополняя сильные стороны друг друга.
- Диссертация: HybridRAG: интеграция графов знаний и векторного поиска для эффективного извлечения информации
Новый подход, основанный на комбинации техник Knowledge Graph RAG (GraphRAG) и VectorRAG, названный HybridRAG, для улучшения систем вопросов и ответов для извлечения информации из финансовых документов, показывает, что он генерирует точные и контекстуально релевантные ответы. На этапах поиска и генерации ответов HybridRAG для извлечения контекста из векторных баз данных и графов знаний превосходит традиционные VectorRAG и GraphRAG по точности поиска и генерации ответов.

(33) W-RAG [Эволюционный поиск]
Эволюционный поискКак хорошая саморазвивающаяся поисковая система, она учится тому, что является хорошим ответом, оценивая параграфы статей в большой модели, постепенно улучшая свою способность находить ключевую информацию.
- Диссертация: W-RAG: Слабо контролируемый плотный поиск в RAG для ответов на вопросы в открытых доменах
- Проект: https://github.com/jmnian/weak_label_for_rag
Методы плотного поиска со слабым контролем в викторинах с открытым доменом используют возможности ранжирования больших языковых моделей для создания слабомаркированных данных для обучения плотных ретриверов. Оценивая вероятность того, что большая языковая модель сгенерирует правильный ответ на основе вопроса и каждого абзаца, можно определить вероятность прохождения теста. BM25 Лучшие K найденных отрывков повторно ранжируются. Отрывки с наивысшим рейтингом используются в качестве положительных обучающих примеров для интенсивного поиска.

(34) RAGChecker [инспектор качества]
инспектор по качествуОтвет не просто правильный или неправильный, он будет тщательно изучен, начиная с поиска информации и заканчивая составлением окончательного ответа, как строгий экзаменатор, который предоставит подробный отчет с отметками и укажет, где необходимо внести конкретные улучшения.
- Диссертация: RAGChecker: тонкий фреймворк для диагностики генерации, дополненной поисковыми функциями
- Проект: https://github.com/amazon-science/RAGChecker
Диагностический инструмент RAGChecker предоставляет тонкие, полные и надежные диагностические отчеты по системе RAG и предлагает практические направления для дальнейшего улучшения производительности. Он не только оценивает общую производительность системы, но и проводит глубокий анализ работы двух основных модулей - поиска и генерации.

(35) Meta-Knowledge-RAG [Scholar]
академияПодобно старшему научному сотруднику, он не только собирает информацию, но и активно размышляет над проблемой, аннотирует и обобщает каждый документ и даже заранее предвидит возможные проблемы. Он соединяет связанные точки знаний, формируя сеть знаний, так что запрос становится более глубоким и широким, как будто ученый помогает вам сделать обзор исследований.
- Диссертация: Метазнания для поиска дополненных моделей большого языка
Meta-Knowledge-RAG (резюме MK) представляет новый рабочий процесс RAG, ориентированный на данные, который трансформирует традиционную систему "извлечение-чтение" в более продвинутую систему "подготовка-перезапись-извлечение-чтение " для достижения более высокого экспертного уровня понимания базы знаний. Наш подход основан на генерации метаданных и синтетических вопросов и ответов для каждого документа, а также на введении новой концепции обобщения метазнаний для кластеризации документов на основе метаданных. Предложенные инновации позволяют персонализировать запросы пользователей и осуществлять глубокий поиск информации в базах знаний.

(36) CommunityKG-RAG [Разведка сообществ]
Исследование сообществаКак волшебник, знакомый с сетью взаимоотношений в сообществе, он умеет использовать ассоциации и групповые характеристики между знаниями, чтобы точно находить нужную информацию и проверять ее достоверность без специального обучения.
- Диссертация: CommunityKG-RAG: Leveraging Community Structures in Knowledge Graphs for Advanced Retrieval-Augmented Generation in Fact- Проверка фактов
CommunityKG-RAG - это новая система с нулевой выборкой, которая объединяет структуры сообществ в Графе знаний с системой RAG для улучшения процесса проверки фактов. CommunityKG-RAG способна адаптироваться к новым доменам и запросам без дополнительного обучения, и она использует многохоповую природу структур сообществ в Графе знаний для значительного повышения точности и релевантности поиска информации. релевантность.

(37) TC-RAG [Memory Warlock]
художник-мнемоник: Поставьте на LLM мозг с функцией автоочистки. Так же, как мы решаем задачи, мы будем писать важные шаги на черновике и вычеркивать их, когда закончим. Это не заучивание, это запоминание того, что нужно запомнить, и своевременное опустошение того, что нужно забыть, как школьный хулиган, который может навести порядок в своей комнате.
- Диссертация: TC-RAG: пример Тьюринг-полного RAG на медицинских системах LLM
- Проект: https://github.com/Artessay/TC-RAG
Внедрение Тьюринг-полной системы для управления переменными состояния позволяет добиться более эффективного и точного извлечения знаний. Используя систему стека памяти с адаптивными возможностями поиска, рассуждений и планирования, TC-RAG не только обеспечивает контролируемое прекращение процесса поиска, но и уменьшает накопление ошибочных знаний за счет операций Push и Pop.

(38) RAGLAB [Arena]
арена: Предоставление алгоритмам возможности честно конкурировать и сравнивать друг с другом по единым правилам, подобно стандартизированному процессу тестирования в научной лаборатории, гарантирует, что каждый новый метод будет оцениваться объективно и прозрачно.
- Диссертация: RAGLAB: модульный и ориентированный на исследования унифицированный фреймворк для генерации с расширенным поиском
- Проект: https://github.com/fate-ubw/RAGLab
Все больше ощущается нехватка всесторонних и справедливых сравнений между новыми алгоритмами RAG, а высокоуровневая абстракция инструментов с открытым исходным кодом приводит к отсутствию прозрачности и ограничивает возможность разработки новых алгоритмов и метрик оценки. RAGLAB - это модульная библиотека с открытым исходным кодом, ориентированная на исследования, которая воспроизводит 6 алгоритмов и создает комплексную исследовательскую экосистему. С помощью RAGLAB мы справедливо сравниваем 6 алгоритмов на 10 эталонах, помогая исследователям эффективно оценивать и внедрять инновационные алгоритмы.

(39) MemoRAG.
обладают высокой ретенционной памятьюОн не просто ищет информацию по запросу, он глубоко понимает и запоминает всю базу знаний. Когда вы задаете вопрос, он быстро извлекает соответствующие воспоминания из этого "супермозга" и дает точный и глубокий ответ, как знающий эксперт.
- Проект: https://github.com/qhjqhj00/MemoRAG
MemoRAG - это инновационный фреймворк Retrieval Augmented Generation (RAG), построенный на основе эффективной модели сверхдлинной памяти. В отличие от стандартных RAG, которые в основном работают с запросами с явными информационными потребностями, MemoRAG использует свою модель памяти для достижения глобального понимания всей базы данных. Вызывая из памяти подсказки, относящиеся к конкретному запросу, MemoRAG улучшает поиск доказательств, что приводит к более точной генерации ответов с учетом контекста.

(40) OP-RAG [управление вниманием]
Управление вниманием: Это как чтение толстой книги - невозможно запомнить все детали, но именно люди, умеющие отмечать ключевые главы, являются мастерами. Это не бесцельное чтение, а как старший читатель, читая и записывая ключевые моменты, при необходимости переходить непосредственно к отмеченной странице.
- Диссертация: В защиту RAG в эпоху длинноконтекстных языковых моделей
Очень длинные контексты в LLM приводят к снижению внимания к релевантной информации и потенциальному ухудшению качества ответа. Пересмотрев RAG в генерации ответов с длинным контекстом, мы предлагаем механизм генерации улучшений поиска с сохранением порядка, OP-RAG, который значительно улучшает производительность RAG в приложениях с длинными контекстными вопросами и ответами.

(41) AgentRE [Интеллектуальное извлечение]
Интеллектуальное извлечениеПодобно социологу, умеющему наблюдать за отношениями, он или она не только запоминает ключевую информацию, но и берет на себя инициативу проверить ее и глубоко обдумать, чтобы точно понять сложную сеть взаимоотношений. Даже перед лицом сложных взаимоотношений они способны проанализировать их с разных точек зрения, чтобы понять их смысл и не читать в них.
- Диссертация: AgentRE: агент-основанная структура для навигации по сложным информационным ландшафтам при извлечении связей
- Проект: https://github.com/Lightblues/AgentRE
Интегрируя возможности памяти, извлечения и отражения информации в крупномасштабных языковых моделях, AgentRE эффективно решает проблемы различных типов отношений в сложных сценах извлечения отношений и неоднозначных отношений между сущностями в одном предложении. AgentRE состоит из трех основных модулей, которые позволяют агентам эффективно получать и обрабатывать информацию и значительно улучшают производительность RE.

(42) iText2KG [Архитектор]
архитекторыПодобно организованному инженеру, он постепенно превращает разрозненные документы в систематическую сеть знаний, поэтапно уточняя, извлекая и интегрируя информацию, и не требует предварительной подготовки подробных архитектурных чертежей, а может гибко расширяться и совершенствоваться по мере необходимости.
- Диссертация: iText2KG: инкрементное построение графов знаний с использованием больших языковых моделей
- Проект: https://github.com/AuvaLab/itext2kg
iText2KG (Incremental Knowledge Graph Construction) использует большие языковые модели (LLM) для построения графов знаний из необработанных документов и обеспечивает инкрементное построение графов знаний с помощью четырех модулей (Document Refiner, Incremental Entity Extractor, Incremental Relationship Extractor и Graph Integrator) без необходимости предварительного определения онтологий или обширного обучения под наблюдением.

(43) GraphInsight [графическая интерпретация]
интерпретация атласа: Как эксперт в анализе инфографики, умеющий разместить важную информацию на самых видных местах, при этом обращаясь к справочникам, чтобы добавить детали, когда это необходимо, и шаг за шагом объясняя сложные диаграммы так, чтобы ИИ получил общую картину, не упуская деталей.
- Диссертация: GraphInsight: раскрытие смысла в больших языковых моделях для понимания структуры графов
GraphInsight - это новый фреймворк, направленный на улучшение понимания LLM информации о графах на макро- и микроуровне. GraphInsight основан на двух ключевых стратегиях: 1) размещение ключевой информации о графах в местах, где LLM обладают хорошей памятью, и 2) внедрение облегченных внешних баз знаний для областей со слабой памятью, опираясь на идею Retrieval Augmented Generation (RAG). Кроме того, GraphInsight исследует интеграцию этих двух стратегий в процесс агента LLM для решения составных задач с графами, требующих многоэтапных рассуждений.

(44) LA-RAG [Диалектный пропуск]
диалектная книгаПодобно лингвисту, хорошо разбирающемуся в диалектах разных местностей, ИИ может точно определить не только стандартный мандарин, но и понять акценты с местными особенностями благодаря тщательному анализу речи и контекстуальному пониманию, что позволяет ему общаться с людьми из разных регионов без каких-либо барьеров.
- Диссертация: LA-RAG:Повышение точности ASR на основе LLM с помощью генерации с расширением поиска
LA-RAG - это новая парадигма расширенного поиска (Retrieval Augmented Generation, RAG) для ASR на основе LLM. LA-RAG использует механизмы хранения речевых данных на уровне маркеров и поиска по речи для повышения точности ASR благодаря функции контекстного обучения LLM (ICL).

(45) SFR-RAG [уточненный поиск]
Оптимизированный поискКак изысканный консультант, небольшой по размеру, но точный по функциям, он понимает потребности и знает, как обратиться за помощью к внешнему источнику, обеспечивая точность и эффективность ответов.
- Диссертация: SFR-RAG: на пути к контекстуально верным LLM
SFR-RAG - это небольшая языковая модель, точно настроенная с помощью инструкций, ориентированных на контекстную генерацию и минимизацию иллюзий. Сосредоточившись на уменьшении количества аргументов при сохранении высокой производительности, модель SFR-RAG включает в себя функциональность вызова функций, которая позволяет ей динамически взаимодействовать с внешними инструментами для получения высококачественной контекстуальной информации.

(46) FlexRAG [эксперт по компрессии]
Специалист по компрессии: Сократите длинную речь до краткого резюме, а степень сжатия можно гибко регулировать в зависимости от потребностей, чтобы не потерять ключевую информацию и сэкономить на хранении и обработке. Это похоже на переработку толстой книги в краткую заметку для чтения.
- Диссертация: Легче и лучше: к гибкой адаптации контекста для поиска дополненного поколения
Контекст, полученный FlexRAG, сжимается в компактные вкрапления перед кодированием в LLM. В то же время эти сжатые вкрапления оптимизируются для повышения производительности последующих RAG. Ключевой особенностью FlexRAG является его гибкость, позволяющая эффективно поддерживать различные коэффициенты сжатия и выборочно сохранять важные контексты. Благодаря этим техническим решениям FlexRAG достигает превосходного качества генерации при значительном снижении эксплуатационных расходов. Всесторонние эксперименты на различных наборах данных Q&A подтверждают, что наш подход является экономически эффективным и гибким решением для систем RAG.

(47) CoTKR [перевод атласа]
перевод атласаКак терпеливый учитель, он или она понимает контекст знаний, а затем объясняет их шаг за шагом, не просто повторяя, а передавая их глубоко. В то же время, собирая обратную связь от студентов, вы можете улучшить свой собственный способ объяснения, чтобы знания передавались более четко и эффективно.
- Диссертация: CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
- Проект: https://github.com/wuyike2000/CoTKR
Подход CoTKR (Chain-of-Thought Enhanced Knowledge Rewriting) чередует генерацию путей вывода и соответствующих знаний, тем самым преодолевая ограничение одноэтапного переписывания знаний. Кроме того, чтобы устранить разницу в предпочтениях между переписывателем знаний и QA-моделью, мы предлагаем стратегию обучения, которая выравнивает предпочтения из обратной связи Q&A для дальнейшей оптимизации переписывателя знаний за счет использования обратной связи от QA-модели.

(48) Open-RAG [Think Tank]
репозиторий: Разбиение огромных языковых моделей на группы экспертов, которые могут думать независимо, а также работать вместе, и быть особенно хорошими в различении истинной и ложной информации, знать, стоит ли искать информацию или нет в критические моменты, как опытный мозговой центр.
- Диссертация: Open-RAG: Enhanced Retrieval-Augmented Reasoning with Open-Source Large Language Models
- Проект: https://github.com/ShayekhBinIslam/openrag
Open-RAG улучшает рассуждения в RAG за счет открытого доступа к большим языковым моделям, преобразуя произвольно плотные большие языковые модели в эффективные по параметрам разреженные модели Mixed-Mixture-of-Experts (MoE), способные решать сложные задачи рассуждения, включая одноходовые и многоходовые запросы. OPEN-RAG уникальным образом обучает модели справляться со сложными интерферирующими терминами, которые кажутся релевантными, но вводят в заблуждение.

(49) TableRAG [Эксперт Excel]
Специалист по Excel: Не ограничивайтесь простым просмотром табличных данных, а знайте, как понимать и извлекать данные как в заголовке, так и в ячейках, так же умело используя поворотные таблицы для быстрого поиска и извлечения нужной вам ключевой информации.
- Доклад: TableRAG: понимание таблиц на миллион слов с помощью языковых моделей
TableRAG разработал механизм генерации с улучшенным поиском специально для понимания таблиц, сочетающий поиск схем и ячеек через расширение запросов для определения ключевых данных до предоставления информации языковой модели, что позволяет более эффективно кодировать данные и точно их извлекать, значительно сокращая длину подсказок и уменьшая потерю информации.

(50) LightRAG [Человек-паук]
человек-паук: Ловко ориентируетесь в паутине знаний, как улавливая нити между точками знаний, так и следуя за ними по паутине. Как ясновидящий библиотекарь, вы не только знаете, где находится каждая книга, но и знаете, какие книги следует читать вместе.
- Диссертация: LightRAG: простая и быстрая генерация с расширением поиска
- Проект: https://github.com/HKUDS/LightRAG
Система интегрирует графовые структуры в процесс индексирования и поиска текстов. Эта инновационная система использует двухуровневую систему поиска, которая улучшает комплексный поиск информации как на основе низкоуровневых, так и высокоуровневых знаний. Кроме того, объединение графовых структур с векторными представлениями способствует эффективному поиску релевантных сущностей и связей между ними, значительно улучшая время отклика при сохранении контекстной релевантности. Эта возможность еще более усиливается благодаря алгоритму инкрементного обновления, который обеспечивает своевременную интеграцию новых данных, позволяя системе оставаться эффективной и быстро реагировать в условиях быстро меняющейся среды данных.

(51) AstuteRAG [Мудрый судья]
Разумный судья: Сохранять бдительность по отношению к внешней информации, не доверять результатам поиска, правильно использовать собственные накопленные знания, проверять подлинность информации и взвешивать доказательства многих сторон, чтобы прийти к заключению, подобно старшему судье.
- Диссертация: Astute RAG: преодоление несовершенного дополнения поиска и конфликтов знаний для больших языковых моделей
Надежность и достоверность системы повышается за счет адаптивного извлечения информации из внутренних знаний LLM, комбинирования ее с результатами внешнего поиска и окончательного принятия решения на основе достоверности информации.

(52) TurboRAG [мастер стенографии]
мастер-стенографист: Заранее сделайте домашнее задание и запишите все ответы в маленький блокнот. Как предэкзаменационный рейд школьного хулигана, не клинические застежки, а общие вопросы заранее заносите не в ту книгу. Когда нужно будет непосредственно обратиться, используйте, экономьте каждый раз, когда придется выводить один раз на месте.
- Диссертация: TurboRAG: ускорение генерации с расширенным поиском и предварительно вычисленными KV-кэшами для фрагментированного текста
- Проект: https://github.com/MooreThreads/TurboRAG
TurboRAG оптимизирует парадигму рассуждений системы RAG, предварительно вычисляя и сохраняя KV-кэши документов в автономном режиме. В отличие от традиционных подходов, TurboRAG больше не вычисляет эти KV-кэши при каждом умозаключении, а вместо этого извлекает предварительно вычисленные кэши для эффективного предварительного заполнения, устраняя необходимость в повторяющихся вычислениях в режиме онлайн. Такой подход значительно снижает вычислительные затраты и ускоряет время отклика, сохраняя при этом точность.

(53) StructRAG [Организатор]
организатор: Организуйте беспорядок информации по категориям, как в организованном гардеробе. Как школьный учитель, подражающий человеческому разуму, вместо заучивания сначала нарисуйте карту ума.
- Диссертация: StructRAG: Boosting Knowledge Intensive Reasoning of LLMs through Inference-time Hybrid Information Structurisation
- Проект: https://github.com/Li-Z-Q/StructRAG
Вдохновленный когнитивной теорией, согласно которой люди преобразуют необработанную информацию в структурированные знания при проведении наукоемких рассуждений, фреймворк представляет гибридный механизм структурирования информации, который создает и использует структурированные знания в наиболее подходящем формате в соответствии с конкретными требованиями поставленной задачи. Имитируя человекоподобные мыслительные процессы, он улучшает производительность LLM при решении наукоемких задач.

(54) Висраг [огненные глаза]
проницательные глаза: Я наконец понял, что слова - это всего лишь особая форма выражения образов. Как читатель, у которого открылись глаза, он больше не настаивает на разборе слова за словом, а сразу "видит" всю картину. Вместо OCR я использовал фотоаппарат и понял, что "фотография стоит тысячи слов".
- Диссертация: VisRAG: визуальный поиск-дополнительная генерация на мультимодальных документах
- Проект: https://github.com/openbmb/visrag
Генерация улучшена за счет построения процесса RAG на основе визуально-лингвистической модели (VLM), которая напрямую внедряет и извлекает документы в виде изображений. По сравнению с традиционным текстовым RAG, VisRAG позволяет избежать потери информации при разборе и более полно сохранить информацию исходного документа. Эксперименты показывают, что VisRAG превосходит традиционный RAG как на этапе поиска, так и на этапе генерации, с улучшением сквозной производительности на 25-391 TP3 T. VisRAG не только эффективно использует обучающие данные, но и демонстрирует сильные обобщающие способности, что делает его идеальным выбором для мультимодального RAG документов.

(55) AGENTiGraph [Менеджер знаний]
менеджер по знаниям: Как разговорный библиотекарь, он помогает вам организовать и представить свои знания посредством ежедневного общения, а команда помощников готова ответить на вопросы и обновить информацию, делая управление знаниями простым и естественным.
- Диссертация: AGENTiGraph: интерактивная платформа для чат-ботов на основе LLM, использующая приватные данные
AGENTiGraph - это платформа для управления знаниями с помощью взаимодействия на естественном языке. AGENTiGraph использует мультиинтеллектуальную архитектуру для динамической интерпретации намерений пользователя, управления задачами и интеграции новых знаний, обеспечивая адаптацию к изменяющимся потребностям пользователей и контексту данных.

(56) RuleRAG [Rule Following]
следовать по компасу и идти по заданному квадрату (идиома); неукоснительно следовать правилам: Научить ИИ выполнять действия по правилам - все равно что принять на работу нового сотрудника и сначала дать ему справочник. Вместо того чтобы бесцельно учиться, он подобен строгому учителю, который сначала объясняет правила и примеры, а затем позволяет ученикам делать это самостоятельно. Делайте больше, эти правила становятся мышечной памятью, и в следующий раз, когда вы столкнетесь с подобными проблемами, вы уже будете знать, как их решать.
- Диссертация: RuleRAG: генерация с использованием языковых моделей для ответов на вопросы с помощью поиска и дополнения правилами
- Проект: https://github.com/chenzhongwu20/RuleRAG_ICL_FT
RuleRAG предлагает подход к генерации, основанный на правилах поиска и усиленной генерации на основе языковой модели, которая явно представляет символические правила как примеры контекстного обучения (RuleRAG - ICL), чтобы направить ретривер на поиск логически релевантных документов в соответствии с правилами, и единообразно направляет генератор на создание обоснованных ответов, руководствуясь тем же набором правил. Кроме того, комбинация запросов и правил может быть использована в качестве контролируемых данных тонкой настройки для обновления ретриверов и генераторов (RuleRAG - FT) для достижения лучшего следования инструкциям, основанным на правилах, что, в свою очередь, приводит к получению более благоприятных результатов и генерированию более приемлемых ответов.

(57) Класс-RAG [Судьи]
судьяВместо того чтобы опираться на жесткие положения при решении дел, он изучает постоянно пополняющуюся библиотеку судебной практики. Подобно опытному судье, он держит в руках кодекс на свободном листе и в любой момент читает последние дела, так что у решения есть и температура, и масштаб.
- Диссертация: Class-RAG: модерация контента с помощью дополненного поиска
Классификаторы проверки содержимого имеют решающее значение для безопасности генеративного ИИ. Однако различить нюансы между безопасным и небезопасным контентом зачастую сложно. По мере распространения технологий становится все сложнее и дороже постоянно настраивать модели для устранения рисков. В связи с этим мы предлагаем подход Class-RAG, который обеспечивает немедленное снижение рисков путем динамического обновления базы поиска. Class-RAG является более гибким и прозрачным, чем традиционные модели тонкой настройки, и демонстрирует лучшие результаты в плане классификации и устойчивости к атакам. Также показано, что расширение поисковой базы может эффективно повысить эффективность аудита при низких затратах.

(58) Self-RAG [Reflector]
мыслитель: Отвечая на вопросы, они не только обращаются к информации, но и обдумывают и проверяют свои ответы на точность и полноту. Как благоразумный ученый, "думая во время разговора", он или она гарантирует, что каждая точка зрения будет подкреплена убедительными доказательствами.
- Диссертация: Self-RAG: обучение извлечению, генерированию и критике через саморефлексию
- Проект: https://github.com/AkariAsai/self-rag
Self-RAG повышает качество и точность языковых моделей за счет поиска и саморефлексии. Система обучает одну произвольную языковую модель, которая может адаптивно извлекать отрывки по запросу и использовать специальные маркеры, называемые рефлексивными маркерами, для генерации и осмысления извлеченных отрывков и собственного сгенерированного контента. Генерирование рефлексивных маркеров делает языковую модель управляемой на этапе рассуждений, позволяя ей адаптировать свое поведение к различным требованиям задачи.

(59) SimRAG [самоучитель]
гений-самородок: Когда вы сталкиваетесь с какой-либо областью знаний, задавайте себе вопросы, прежде чем ответить на них, и пополняйте свой запас профессиональных знаний путем постоянной практики, так же как студенты знакомятся со своими профессиональными знаниями путем многократного выполнения упражнений.
- Диссертация: SimRAG: самосовершенствующаяся генерация с расширением поиска для адаптации больших языковых моделей к специализированным доменам
SimRAG - это метод самообучения, который дает LLM возможность комбинировать вопросы и ответы, а также генерировать вопросы для конкретных доменов. Хорошие вопросы можно задавать только в том случае, если знания действительно понятны. Эти две способности дополняют друг друга, помогая модели лучше понять знания. Сначала LLM настраивается на следование инструкциям, вопросы и ответы и поиск релевантных данных. Затем этому же LLM предлагается сгенерировать множество вопросов, относящихся к области, из немаркированного корпуса, с дополнительными стратегиями фильтрации для сохранения высококачественных синтетических примеров. Используя эти синтетические примеры, LLM может улучшить свою производительность при решении задач RAG, специфичных для данной области.

(60) ChunkRAG [отрывки из мастера]
человек, который делает выписки из книги: Разбейте длинные статьи на небольшие абзацы, а затем профессиональным взглядом выделите наиболее важные фрагменты, не упуская сути и не отвлекаясь на неактуальный контент.
- Диссертация: ChunkRAG: новый метод LLM-фильтрации для RAG-систем
ChunkRAG предлагает подход к фильтрации фрагментов на основе LLM для расширения возможностей систем RAG путем оценки и фильтрации полученной информации на уровне фрагментов, где "фрагменты" представляют собой небольшие связные части документа. Наш подход использует семантическую разбивку для разделения документа на последовательные части и использует оценку релевантности на основе большой языковой модели для оценки того, насколько хорошо каждый кусок соответствует запросу пользователя. Отфильтровывая менее релевантные фрагменты до этапа генерации, мы значительно уменьшаем количество иллюзий и повышаем точность фактов.

(61) FastGraphRAG [Radar]
радар (заимствованное слово): Как и Google Page Rank, присваивает знаниям горячий список. Это как лидер мнений в социальной сети: чем больше людей следуют за ним, тем легче его заметить. Вместо бесцельного поиска, это как разведчик с радаром, который ищет везде, где есть сильный сигнал.
- Проект: https://github.com/circlemind-ai/fast-graphrag
FastGraphRAG - это эффективная, интерпретируемая и высокоточная система Fast Graph Retrieval Augmented Generation (FastGraphRAG). Она применяет алгоритм PageRank в процессе обхода графа знаний, чтобы быстро находить наиболее релевантные узлы знаний. Вычисляя балл важности узла, PageRank позволяет GraphRAG более разумно фильтровать и сортировать информацию в графе знаний. Это похоже на оснащение GraphRAG "радаром важности", который позволяет быстро находить ключевую информацию в огромном количестве данных.

(62) AutoRAG [Tuner]
тюнерRAG - это опытный настройщик, который находит наилучшее звучание не путем угадывания, а путем научного тестирования. Он автоматически пробует различные комбинации RAG, подобно тому как микшер тестирует различное аудиооборудование, чтобы найти наиболее гармоничное "игровое решение".
- Диссертация: AutoRAG: Автоматизированная структура для оптимизации конвейера дополненной генерации поисковых данных
- Проект: https://github.com/Marker-Inc-Korea/AutoRAG_ARAGOG_Paper
Фреймворк AutoRAG автоматически определяет подходящие модули RAG для заданного набора данных, а также исследует и приближенно определяет оптимальную комбинацию модулей RAG для этого набора данных. Систематически оценивая различные наборы RAG для оптимизации выбора методов, фреймворк похож на практику AutoML в традиционном машинном обучении, где проводятся обширные эксперименты для оптимизации выбора методов RAG и повышения эффективности и масштабируемости системы RAG.

(63) План x RAG [Руководитель проекта]
руководитель проектаПланирование перед действием, разбивка крупных задач на более мелкие и организация параллельной работы нескольких "экспертов". Каждый эксперт отвечает за свой участок, а руководитель проекта - за подведение итогов. Такой подход не только быстрее и точнее, но и позволяет получить четкое представление об источнике каждого вывода.
- Диссертация: Plan × RAG: планирование-направленное извлечение дополненной генерации
Plan×RAG - это новый фреймворк, который расширяет парадигму "поиск - рассуждение" существующих фреймворков RAG до парадигмы "план - поиск". Plan×RAG формулирует планы рассуждений как направленные ациклические графы (DAG), которые декомпозируют запросы на Plan×RAG формулирует план рассуждений в виде направленного ациклического графа (DAG) и декомпозирует запрос на взаимосвязанные атомарные подзапросы. Генерация ответов следует структуре DAG, что значительно повышает эффективность за счет параллельного поиска и генерации. В то время как современные решения RAG требуют обширной генерации данных и тонкой настройки языковых моделей (ЯМ), Plan×RAG использует замороженные ЯМ как подключаемые эксперты для генерации высококачественных ответов.

(64) SubgraphRAG [locator]
позиционерВместо того чтобы искать иголку в стоге сена, составляется точная карта знаний, чтобы ИИ мог быстро находить ответы.
- Диссертация: Простота - это эффективность: роли графов и больших языковых моделей в поисковой системе на основе графов знаний - дополненное поколение
- Проект: https://github.com/Graph-COM/SubgraphRAG
SubgraphRAG расширяет рамки RAG на основе KG, извлекая подграфы и используя LLM для вывода и предсказания ответов. Легкий многослойный перцептрон сочетается с параллельным троичным механизмом подсчета баллов для эффективного и гибкого поиска подграфов, при этом кодируется расстояние направленной структуры для повышения эффективности поиска. Размер извлекаемых подграфов может быть гибко настроен в соответствии с требованиями запроса и возможностями последующего LLM. Такая конструкция позволяет найти баланс между сложностью модели и возможностями вывода, обеспечивая масштабируемый и универсальный процесс поиска.

(65) RuRAG [Алхимик]
алхимик: Подобно алхимику, он может перегонять огромные объемы данных в четкие логические правила и выражать их на простом языке, делая ИИ более умным в практических приложениях.
- Диссертация: RuAG: генерация с дополнениями по изученным правилам для больших языковых моделей
направлен на расширение возможностей рассуждений крупномасштабных языковых моделей (LLM) путем автоматического преобразования больших объемов автономных данных в интерпретируемые логические правила первого порядка и их введения в LLM. Фреймворк использует поиск по дереву Монте-Карло (MCTS) для обнаружения логических правил и преобразования этих правил в естественный язык, что позволяет вводить знания и обеспечивать бесшовную интеграцию для последующих задач LLM. В статье оценивается эффективность фреймворка на государственных и частных промышленных задачах, что демонстрирует его потенциал для расширения возможностей LLM в различных задачах.

(66) RAGViz [прозрачный глаз]
туннельное зрение: Сделайте систему RAG прозрачной, чтобы видеть, какое предложение читает модель, как врач, смотрящий на рентгеновский снимок, и сразу понять, что не так.
- Диссертация: RAGViz: Диагностика и визуализация генерации с расширенным поиском
- Проект: https://github.com/cxcscmu/RAGViz
RAGViz предоставляет визуализацию найденных документов и внимания к модели, чтобы помочь пользователям понять взаимодействие между сгенерированной разметкой и найденными документами, а также может использоваться для диагностики и визуализации систем RAG.

(67) AgenticRAG [Интеллектуальный помощник]
интеллектуальный помощник: Теперь вам нужен не просто поиск и копирование, а помощник, способный выполнять функции конфиденциального секретаря. Как грамотный администратор, он не только умеет искать информацию, но и знает, когда позвонить по телефону, когда провести совещание и когда попросить инструкций.
AgenticRAG описывает RAG, основанный на реализации интеллекта ИИ. В частности, он включает интеллекты ИИ в процесс RAG для координации его компонентов и выполнения дополнительных действий, помимо простого поиска и генерации информации, чтобы преодолеть ограничения неинтеллектуальных процессов организма.

(68) HtmlRAG [Типография]
типография: Знания хранятся не как текущий отчет, а как журнальная верстка, с выделением жирным шрифтом там, где нужно, и красным - там, где нужно. Это похоже на суетливого редактора, который считает, что одного содержания недостаточно, нужно еще и оформить его так, чтобы ключевые моменты были видны с первого взгляда.
- Диссертация: HtmlRAG: HTML лучше, чем обычный текст, для моделирования полученных знаний в системах RAG
- Проект: https://github.com/plageon/HtmlRAG
HtmlRAG использует HTML, а не обычный текст в качестве формата для поиска знаний в RAG. HTML лучше, чем обычный текст, при моделировании знаний из внешних документов, и большинство LLM хорошо знают HTML. HtmlRAG предлагает стратегии очистки, сжатия и обрезки HTML для сокращения HTML при минимизации потери информации.

(69) M3DocRAG [Sensualist]
чувствительный человек: Он не только читает, но и может читать картинки и слушать голоса. Подобно участнику эстрадного шоу, он может читать картинки, понимать слова, прыгать, когда нужно прыгнуть, сосредотачиваться на деталях, когда нужно сосредоточиться, и не поддается никаким испытаниям.
- Диссертация: M3DocRAG: мультимодальный поиск - это то, что вам нужно для понимания многостраничных документов
M3DocRAG - это новая мультимодальная система RAG, которая гибко адаптируется к различным контекстам документов (закрытые и открытые домены), переходам вопросов (одиночные и множественные) и способам доказательства (текст, диаграммы, графики и т.д.). M3DocRAG использует мультимодальный ретривер и MLM для поиска релевантных документов и ответов на вопросы, и поэтому может эффективно обрабатывать одиночные или множественные документы с сохранением визуальной информации. информацию.

(70) КАГ [магистр логики]
мастер логики: Это не просто поиск похожих ответов по ощущениям, но и причинно-следственная связь между знаниями. Как строгий учитель математики, вы должны не только знать ответ, но и объяснить, как этот ответ был получен шаг за шагом.
- Диссертация: KAG: Повышение уровня LLM в профессиональных областях с помощью генерации дополненных знаний
- Проект: https://github.com/OpenSPG/KAG
Разрыв между сходством векторов и релевантностью знаний в RAG, а также нечувствительность к логике знаний (например, числовые значения, временные отношения, экспертные правила и т. д.) препятствуют эффективности экспертных сервисов. KAG разработан, чтобы использовать сильные стороны Графа знаний (ГЗ) и векторного поиска для решения вышеуказанных проблем, и двунаправленно улучшает крупномасштабные языковые модели (LLM) и Граф знаний через пять ключевых аспектов для повышения производительности генерации и вывода: (1) удобное для LLM представление знаний, (2) перекрестная индексация между Knowledge Graph и необработанными фрагментами, (3) гибридный механизм вывода на основе логических форм, (4) выравнивание знаний с семантическим выводом, и (5) расширение возможностей моделирования KAG.

(71) ФИЛКО [Просеиватель]
грохоты: Как строгий редактор, умеющий выявлять и сохранять наиболее ценную информацию из больших объемов текста, обеспечивая точность и актуальность каждого фрагмента контента, передаваемого ИИ.
- Диссертация: Обучение фильтрации контекста для генерации с расширенным поиском
- Проект: https://github.com/zorazrw/filco
FILCO улучшает качество контекста, предоставляемого генератору, путем определения полезных контекстов на основе лексического и информационно-теоретического подходов, а также путем обучения модели фильтрации контекста для фильтрации полученных контекстов.

(72) LazyGraphRAG [актуарий]
актуарии: Шаг - это шаг, если вы можете его сэкономить, а большие дорогие модели использовать с пользой. Как домохозяйка, знающая толк в жизни, вы не просто покупаете, когда видите распродажу в супермаркете, а сравниваете, прежде чем решить, куда потратить деньги, чтобы получить максимальную выгоду.
- Проект: https://github.com/microsoft/graphrag
Новый подход к созданию расширенного поиска с использованием графов (RAG). Этот подход значительно снижает затраты на индексирование и запрос, сохраняя или превосходя конкурентов по качеству ответа, что делает его высокомасштабируемым и эффективным в широком диапазоне случаев использования.LazyGraphRAG откладывает использование LLM. На этапе индексирования LazyGraphRAG использует только легкие методы NLP для обработки текста, откладывая обращение к LLM до фактического запроса. Такая "ленивая" стратегия позволяет избежать высоких затрат на предварительное индексирование и эффективно использовать ресурсы.
| Традиционный графикRAG | LazyGraphRAG | |
| этап индексирования | - Извлечение и описание сущностей и отношений с помощью LLM - Создайте сводки для каждой сущности и отношения - Обобщение содержания сообществ с помощью LLM - Создание векторов встраивания - Генерация паркетных файлов | - Извлечение понятий и кокуррентных отношений с помощью методов НЛП - Составление концептуальных карт - Извлечение структур сообщества - LLM не используется на этапе индексирования |
| Стадия запроса | - Отвечайте на запросы напрямую, используя сводки сообществ - Отсутствие уточнения запросов и сосредоточения внимания на релевантной информации | - Использование LLM для уточнения запросов и создания подзапросов - Выбор сегментов текста и сообществ на основе релевантности - Извлечение и генерирование ответов с помощью LLM - Больше внимания уделяется актуальному содержанию, более точные ответы |
| Вызов LLM | - Широко используется как на этапе индексирования, так и на этапе запросов | - LLM не используется на этапе индексирования - Вызов LLM только в фазе запроса - LLM используется более эффективно |
| экономическая эффективность | - Высокая стоимость и трудоемкость индексации - Производительность запросов ограничена качеством индекса | - Стоимость индексации составляет всего 0,1% по сравнению с традиционным GraphRAG. - Высокая эффективность запросов и высокое качество ответов |
| хранение данных | - Файлы Parquet создаются из индексированных данных и подходят для хранения и обработки больших объемов данных. | - Индексированные данные хранятся в облегченных форматах (например, JSON, CSV), что лучше подходит для быстрой разработки и небольших объемов данных. |
| Сценарии использования | - Для сценариев, которые не чувствительны к вычислительным ресурсам и времени - Полный граф знаний должен быть построен заранее и сохранен в виде файла Parquet для последующего импорта в базу данных для проведения комплексного анализа | - Для сценариев, требующих быстрого индексирования и отклика - Идеально подходит для одноразовых запросов, исследовательского анализа и обработки потоковых данных |
Опрос RAG
- Обзор создания текстов с помощью поисковых систем
- Поиск мультимодальной информации для дополненного поколения: обзор
- Генерация с расширением поиска для больших языковых моделей: обзор
- Поиск-дополнение для генерируемого ИИ контента: обзор
- Обзор генерации текстов с расширенными возможностями поиска для больших языковых моделей
- RAG и RAU: обзор моделей языка, дополняемых поисковой информацией, в обработке естественного языка
- Обзор LLM на встрече RAG: на пути к большим языковым моделям с расширением поиска
- Оценка генерации с расширенным поиском: обзор
- Генерация, дополненная поиском, для обработки естественного языка: обзор
- Поколение с расширенным графическим поиском: обзор
- Всесторонний обзор технологии Retrieval-Augmented Generation (RAG): эволюция, текущий ландшафт и будущие направления
- Поколение с расширенным поиском (RAG) и не только: всесторонний обзор того, как заставить ваших магистрантов более разумно использовать внешние данные
Контрольный показатель RAG
- Бенчмаркинг больших языковых моделей в генерации с расширенным поиском
- RECALL: контрольный показатель устойчивости LLM к внешним контрфактическим знаниям
- ARES: автоматизированная система оценки для систем генерации с расширенным поиском
- RAGAS: Автоматизированная оценка дополненного поиска
- CRUD-RAG: комплексный китайский бенчмарк для создания больших языковых моделей с расширенным поиском
- FeB4RAG: оценка объединенного поиска в контексте дополненной генерации поиска
- CodeRAG-Bench: может ли поиск дополнить генерацию кода?
- Long2RAG: оценка длинного контекста и длинной формы, дополненной генерацией с запоминанием ключевых точек
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...