

QwenLong-L1.5是什么
QwenLong-L1.5是阿里巴巴通义实验室开源的长文本推理模型,专注于解决超长上下文(如1M-4M tokens)的复杂推理问题。核心突破在于后训练阶段的三大创新:通过知识图谱、SQL解析和多智能体框架生成高质量多跳推理数据;提出自适应熵控策略AEPo,动态平衡训练稳定性;设计内存代理架构,分块处理超长文本并实时更新记忆摘要。模型在LongBench-V2等榜单上超越GPT-5和Gemini-2.5-Pro,尤其在超长文本任务中表现突出,同时提升了数学推理等通用能力。
QwenLong-L1.5的功能特色
- 长上下文推理能力显著提升:通过系统化的后训练方案,QwenLong-L1.5在长上下文推理方面表现出色,能处理超出其物理上下文窗口(256K)的任务。
- 创新的数据合成与强化学习策略:开发了新的数据合成流程,专注于创建需要多跳溯源和全局分布式证据推理的挑战性任务,引入任务平衡采样和自适应熵控策略优化等强化学习策略,以稳定长上下文训练。
- 强大的记忆管理框架:采用多阶段融合强化学习,结合记忆更新机制,使模型在单次推理256K上下文窗口外,能处理更长的任务。
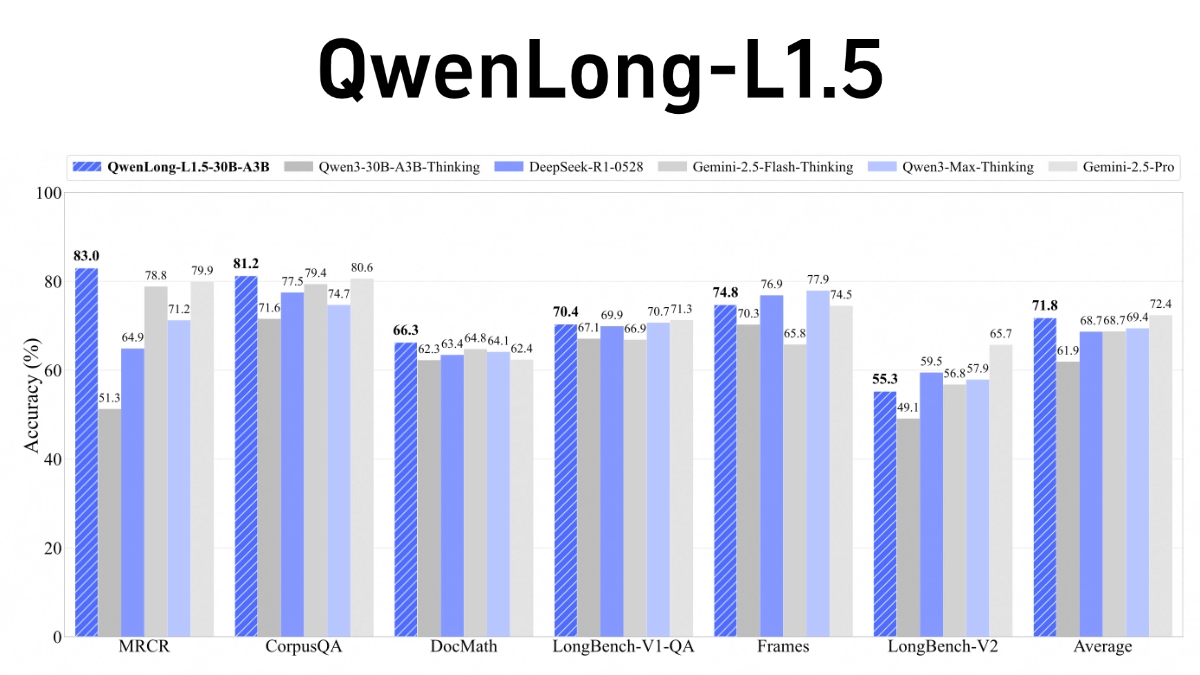
- 性能优异:在长上下文基准测试中,QwenLong-L1.5比其基线模型Qwen3-30B-A3B-Thinking平均高出9.9分,性能可与GPT-5和Gemini-2.5-Pro等顶级模型媲美。其记忆-智能体框架在超长任务(100万~400万个token)上,较智能体基线实现9.48分的性能增益。
- 开源:模型已经开源,方便研究人员和开发者使用。
QwenLong-L1.5的核心优势
- 超强长文本处理能力:能处理超过其物理上下文窗口(256K)的任务,适合处理超长文本推理和分析,如长篇文档、复杂数据集等。
- 创新训练策略:结合任务平衡采样和自适应熵控策略优化(AEPO)等强化学习方法,有效提升模型在长上下文任务中的稳定性和性能。
- 高效记忆管理:通过记忆更新机制和多阶段融合强化学习,模型可以有效管理长文本中的信息,实现对超长任务(100万~400万个token)的高效处理。
- 卓越性能表现:在长上下文基准测试中,QwenLong-L1.5的性能显著优于其基线模型,甚至可以与GPT-5和Gemini-2.5-Pro等顶级模型媲美。
QwenLong-L1.5官网是什么
- GitHub仓库:https://github.com/Tongyi-Zhiwen/Qwen-Doc
- HuggingFace模型库:https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
- arXiv技术论文:https://arxiv.org/pdf/2512.12967
QwenLong-L1.5的适用人群
- 自然语言处理研究人员:QwenLong-L1.5的长上下文处理能力和创新训练策略,为研究人员提供了研究长文本推理、记忆管理等前沿问题的新工具,有助于推动自然语言处理领域的研究进展。
- 人工智能开发者:开源的特性使其成为开发者构建长文本处理应用的理想选择,例如智能客服、文档分析、内容创作等,能帮助开发者快速开发出高性能的长文本处理功能。
- 数据科学家:在处理大规模文本数据集时,QwenLong-L1.5能有效进行长文本分析和推理,为数据科学家提供强大的支持,助力数据分析和机器学习任务。
- 企业技术团队:对于需要处理长文本业务的企业,如金融、法律、医疗等行业,QwenLong-L1.5可以帮助团队更高效地处理合同、报告、病历等长文本数据,提升业务效率。
- 学术研究人员:在学术研究中,尤其是涉及长文本分析的领域,如文学研究、历史文献分析等,QwenLong-L1.5可以作为研究工具,帮助研究人员挖掘文本中的深层次信息。
- 教育工作者:在教育领域,QwenLong-L1.5可用于辅助教学,如自动批改长篇作文、分析学术论文等,为教育工作者提供更高效的教学支持工具。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...