
1.引言
两个月前,Qwen团队升级了 Qwen2.5-Turbo,使其支持最多一百万个Tokens的上下文长度。今天,Qwen正式推出开源的 Qwen2.5-1M 模型及其对应的推理框架支持。以下是本次发布的亮点:
开源模型: 本次发布了两个新的开源模型,分别是 Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M,这是Qwen首次将开源的 Qwen 模型的上下文扩展到 1M 长度。
推理框架: 为了帮助开发者更高效地部署 Qwen2.5-1M 系列模型,Qwen团队完全开源了基于 vLLM 的推理框架,并集成了稀疏注意力方法,使得该框架在处理 1M 标记输入时的速度提升了 3倍到7倍。
技术报告: Qwen团队还分享了 Qwen2.5-1M 系列背后的技术细节,包括训练和推理框架的设计思路以及消融实验的结果。
模型链接:https://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
技术报告:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
体验链接:https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2.模型性能
首先,来看看 Qwen2.5-1M 系列模型在长上下文任务和短文本任务中的性能表现。
长上下文任务
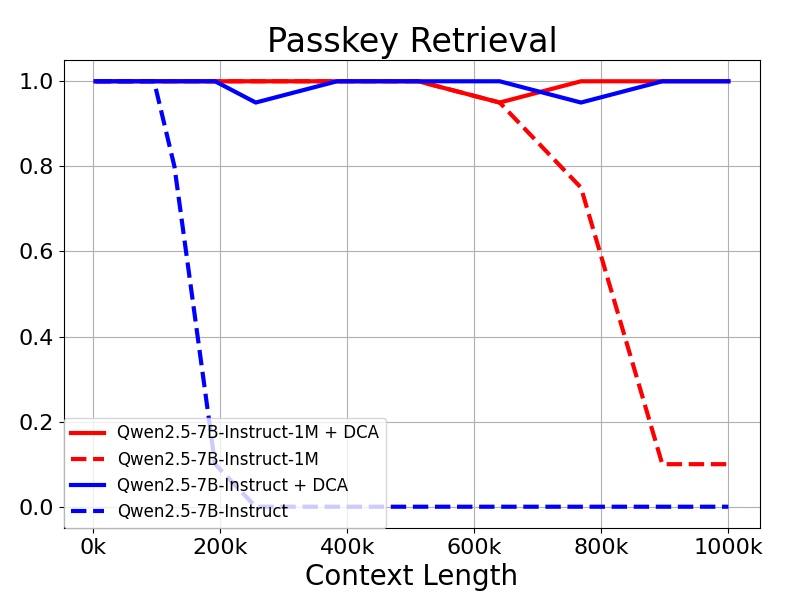
在上下文长度为100万 Tokens 的大海捞针(Passkey Retrieval)任务中,Qwen2.5-1M 系列模型能够准确地从 1M 长度的文档中检索出隐藏信息,其中仅有7B模型出现了少量错误。
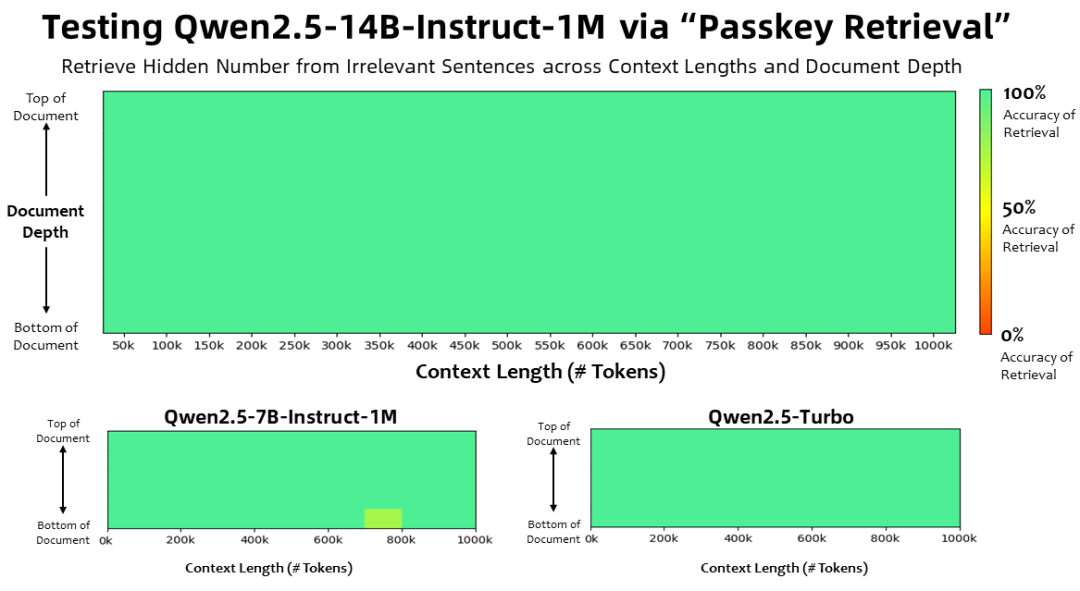
对于更复杂的长上下文理解任务,选择了RULER、LV-Eval 和 LongbenchChat测试集。
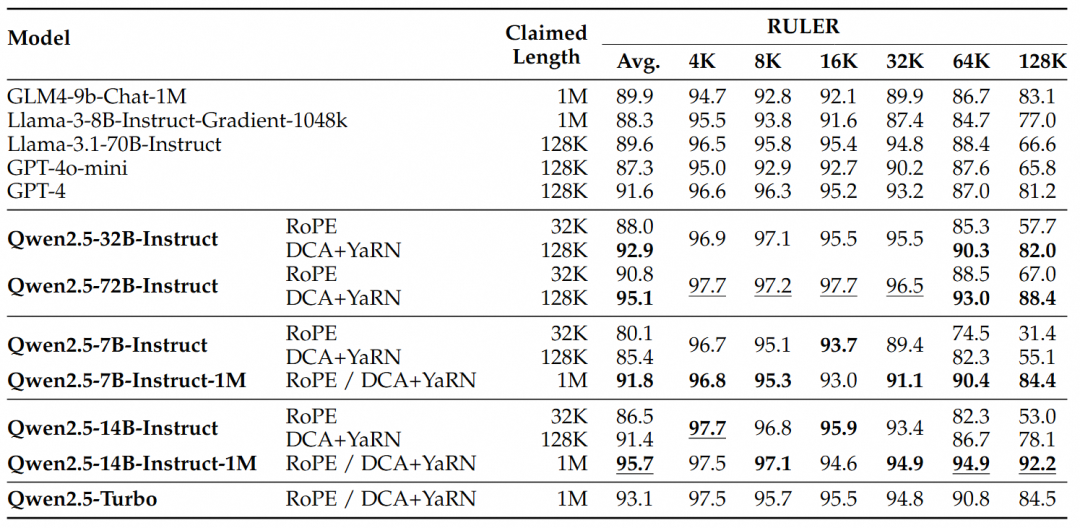
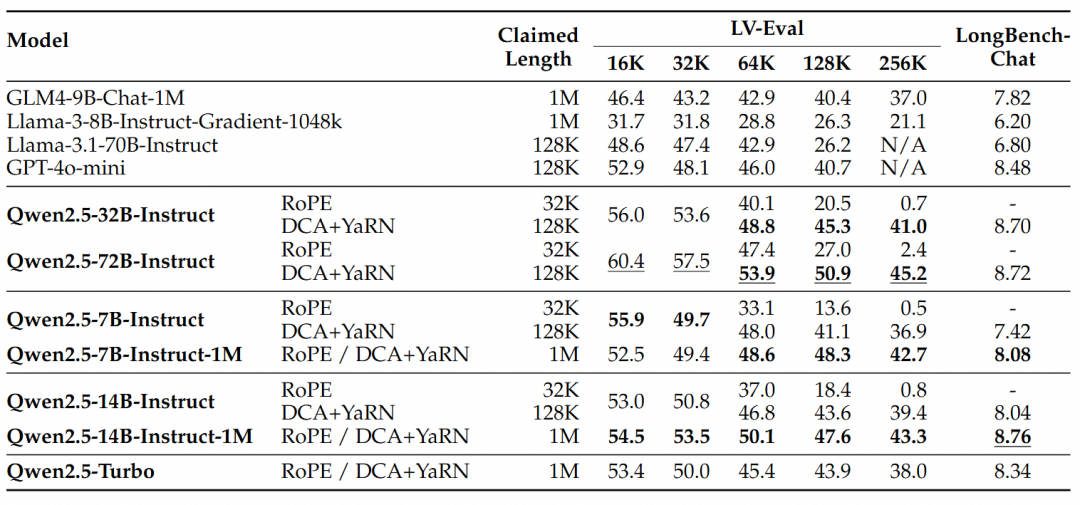
从这些结果中,可以得出以下几点关键结论:
- 显著超越128K版本:Qwen2.5-1M系列模型在大多数长上下文任务中显著优于之前的128K版本,特别是在处理超过64K长度的任务时表现出色。
- 性能优势明显:Qwen2.5-14B-Instruct-1M 模型不仅击败了 Qwen2.5-Turbo,还在多个数据集上稳定超越 GPT-4o-mini,为长上下文任务提供了开源模型的选择。
短序列任务
除了长序列任务的性能外,模型在短序列上的表现同样很重要。在广泛使用的学术基准测试中比较了 Qwen2.5-1M 系列模型及之前的128K版本,并加入了GPT-4o-mini进行对比。 
可以发现:
- Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M 在短文本任务上的表现与其128K版本相当,确保了基本能力没有因为增加了长序列处理能力而受到影响。
- 与 GPT-4o-mini 相比,Qwen2.5-14B-Instruct-1M 和 Qwen2.5-Turbo 在短文本任务上实现了相近的性能,同时上下文长度是GPT-4o-mini的八倍。
3.关键技术
长上下文训练
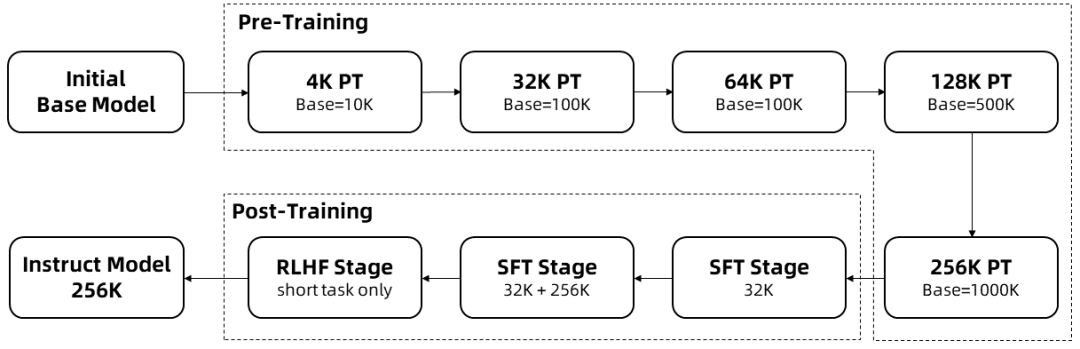
长序列的训练需要大量的计算资源,因此采用了逐步扩展长度的方法,在多个阶段将Qwen2.5-1M的上下文长度从4K扩展到256K:
从预训练的Qwen2.5的一个中间Checkpoint开始,此时上下文长度为4K。
在预训练阶段,逐步将上下文长度从 4K 增加到 256K,同时使用Adjusted Base Frequency的方案,将 RoPE 基础频率从 10,000 提高到 10,000,000。
在监督微调阶段,分两个阶段进行以保持短序列上的性能:
第一阶段: 仅在短指令(最多32K长度)上进行微调,这里使用与 Qwen2.5 的 128K 版本相同的数据和步骤数。
第二阶段: 混合短指令(最多32K)和长指令(最多256K),实现在增强长任务的性能的同时,保持短任务的质量。
在强化学习阶段,在短文本(最多8K标记)上训练模型。我们发现,即使在短文本上进行训练,人类偏好的对齐的提升能够很好地泛化到长上下文任务中。 通过以上训练,我们最终获得的 Instruct 模型能够处理长达256K Tokens的序列。
通过以上训练,获得了256K上下文长度的指令微调模型。
长度外推
在上述训练过程中,模型的上下文长度仅为 256K 个 Token。为了将其扩展到 1M Tokens,采用了长度外推的技术。
当前,基于旋转位置编码的大型语言模型在长上下文任务中会产生性能下降,这主要是由于在计算注意力权重时,Query 和 Key 之间的相对位置距离过大,在训练过程中未曾见过。为了解决这一问题,Qwen2.5-1M采用Dual Chunk Attention(DCA)的方法,该方法通过将过大的相对位置,重新映射为较小的值,从而解决了这一难题。
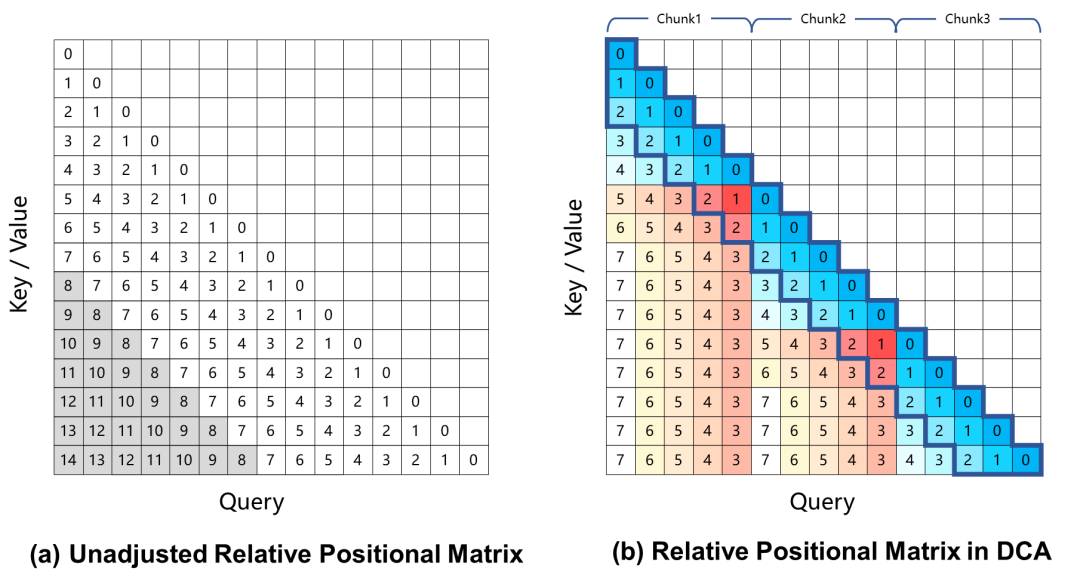
对 Qwen2.5-1M 模型及之前 128K 的版本进行了评估,分别测试了使用和不使用长度外推方法的情况。
结果表明:即使是仅在32K标记上训练的模型,如Qwen2.5-7B-Instruct,在处理1M标记上下文的 Passkey Retrieval 任务中也能达到近乎完美的准确率。这充分展示了 DCA 在无需额外训练的情况下,即可显著扩展支持的上下文长度的强大能力。
稀疏注意力机制
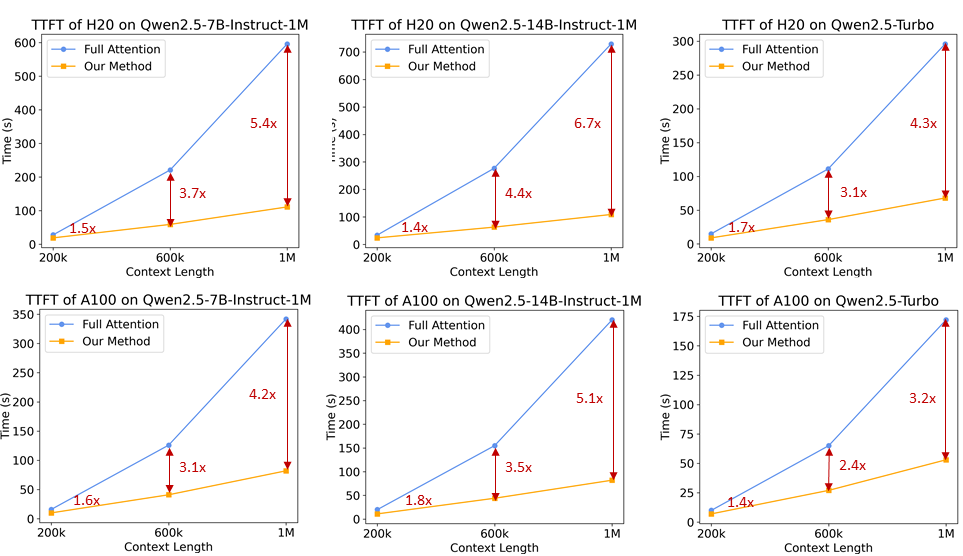
对于长上下文语言模型,推理速度对于用户体验至关重要。为了加速预填充阶段,研究团队引入了基于 MInference 的稀疏注意机制。此外,提出了几项改进:
- 分块预填充: 如果直接使用模型处理长度100万的序列,其中 MLP 层的激活权重会产生巨大的显存开销。以Qwen2.5-7B 为例,这部分开销高达 71GB。通过将分块预填充(Chunked Prefill)与稀疏注意力适配,可以将输入序列以 32768 长度分块,逐块进行预填充,MLP 层激活权重的显存使用量可减少 96.7%,因而显著降低了设备的显存需求。
- 集成长度外推方案: 我们在稀疏注意力机制中进一步集成了基于 DCA 的长度外推方案,这使我们的推理框架能够同时享受更高的推理效率和长序列任务的准确性。
- 稀疏性优化: 原始的 MInference 方法需要进行离线搜索以确定每个注意力头的最佳稀疏化配置。由于全注意力权重对内存的要求太大,这种搜索通常在短序列上进行,不一定能在更长序列下起到很好的效果。我们提出了一种能够在100万长度的序列上优化稀疏化配置的方法,从而显著减少了稀疏注意力带来的精度损失。
- 其他优化: 我们还引入了其他优化措施,如优化算子效率和动态分块流水线并行,以充分发挥整个框架的潜力。
通过这些改进,推理框架在不同模型大小和 GPU 设备上将 1M 个 token 长度的序列的预填充速度提高了 3.2 倍到 6.7 倍。
4.模型部署
系统准备
为了获得最佳性能,建议使用支持优化内核的 Ampere 或 Hopper 架构的 GPU。
请确保满足以下要求:
- CUDA 版本:12.1 或 12.3
- Python 版本:>=3.9 且 <=3.12
显存要求,对于处理 1M 长度的序列:
- Qwen2.5-7B-Instruct-1M:至少需要 120GB 显存(多 GPU 总和)。
- Qwen2.5-14B-Instruct-1M:至少需要 320GB 显存(多 GPU 总和)。
如果 GPU 显存不满足以上要求,你仍然可以使用 Qwen2.5-1M 进行较短任务的处理。
安装依赖项
暂时,你需要从自定义分支克隆 vLLM 仓库,并手动安装。研究团队正在努力将该分支提交到 vLLM 项目中。
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
启动 OpenAI 兼容的 API 服务
指定模型从ModelScope下载
export VLLM_USE_MODELSCOPE=True
发布OpenAI兼容的API服务
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
参数说明:
--tensor-parallel-size- 设置为您使用的 GPU 数量。7B 模型最多支持 4 个 GPU,14B 模型最多支持 8 个 GPU。
--max-model-len- 定义最大输入序列长度。如果遇到内存不足问题,请减少此值。
--max-num-batched-tokens- 设置 Chunked Prefill 的块大小。较小的值可以减少激活内存使用,但可能会减慢推理速度。
- 推荐值为 131072,以获得最佳性能。
--max-num-seqs- 限制并发处理的序列数量。
与模型交互
可以使用以下方法与部署的模型进行交互:
选项 1. 使用 Curl
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
选项 2. 使用 Python
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
您还可以探索其他框架,例如Qwen-Agent,以使模型能够读取 PDF 文件等。
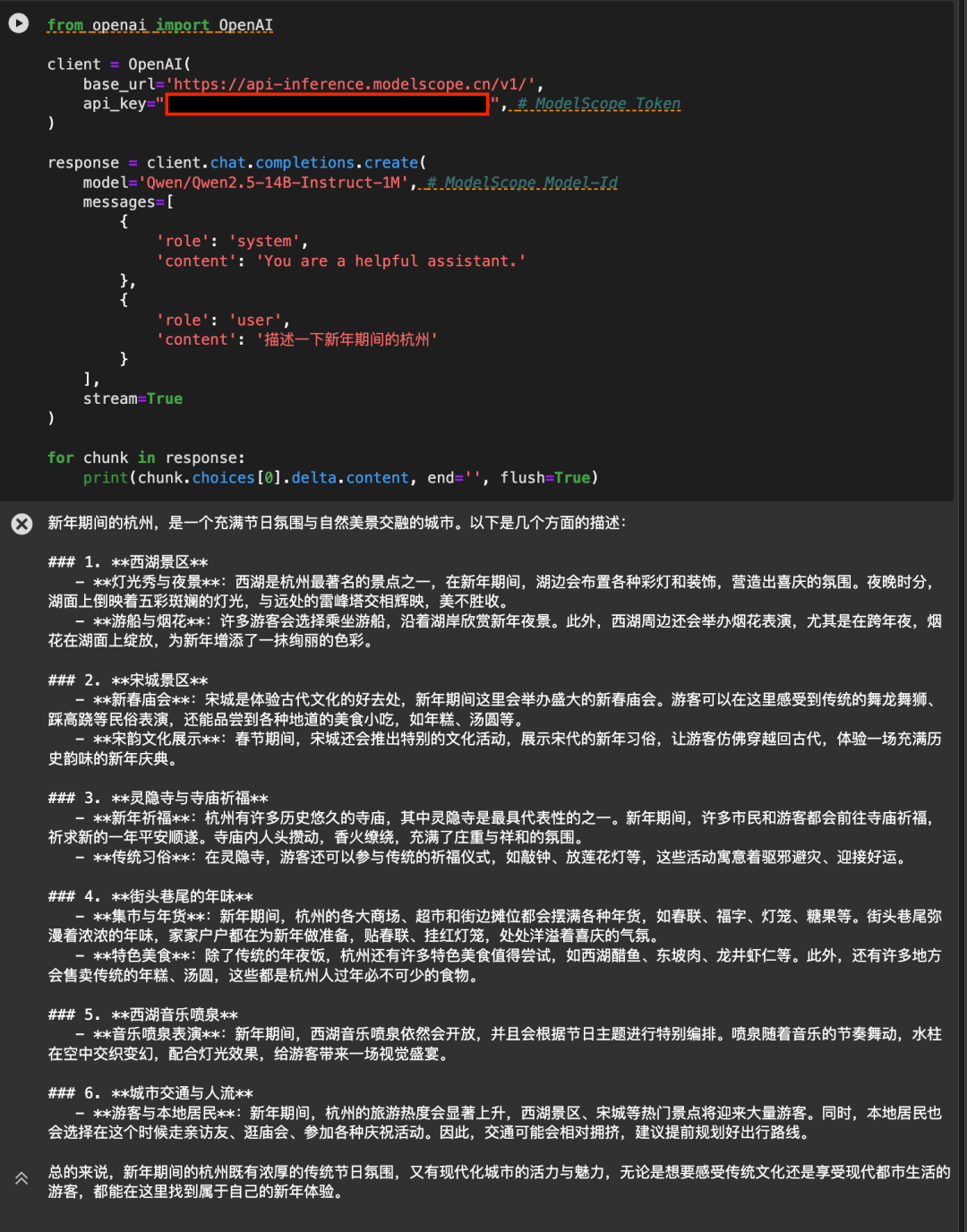
5.使用魔搭API-Inference直接调用
魔搭平台的API-Inference,也第一时间为Qwen2.5-7B-Instruct-1M和Qwen2.5-14B-Instruct-1M模型提供了支持。魔搭的用户可通过API调用的方式,直接使用该模型。具体API-Inference的使用方式可参见模型页面(例如 https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M )说明:

或者参见API-Inference文档:https://www.modelscope.cn/docs/model-service/API-Inference/intro
感谢阿里云百炼平台提供背后算力支持。
使用Ollama和llamafile
为了方便大家在本地使用,魔搭在第一时间提供了Qwen2.5-7B-Instruct-1M模型的GGUF版本和llamafile版本。可通过Ollama框架调用,或者直接使用拉起llamafile。
1.Ollama调用
首先设置ollama下启用:
ollama serve
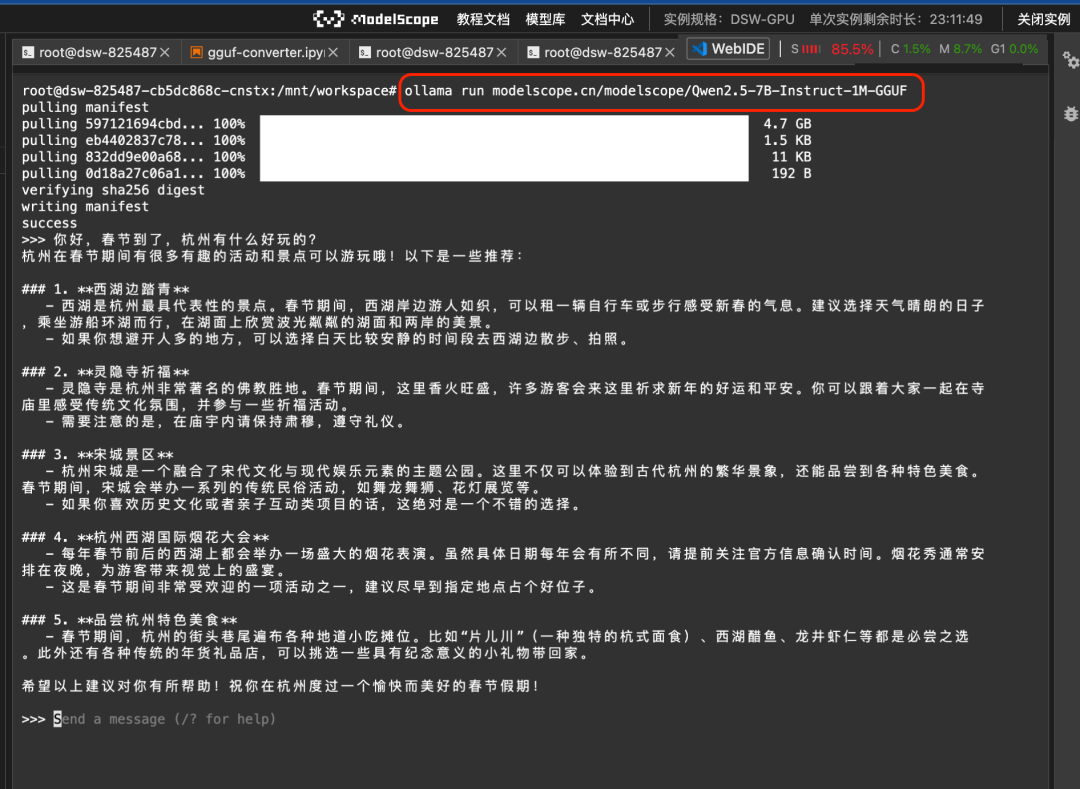
然后就可以直接使用 ollama run 的命令运行魔搭上的GGUF模型:
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUF运行结果:
2.llamafile模型直接拉起
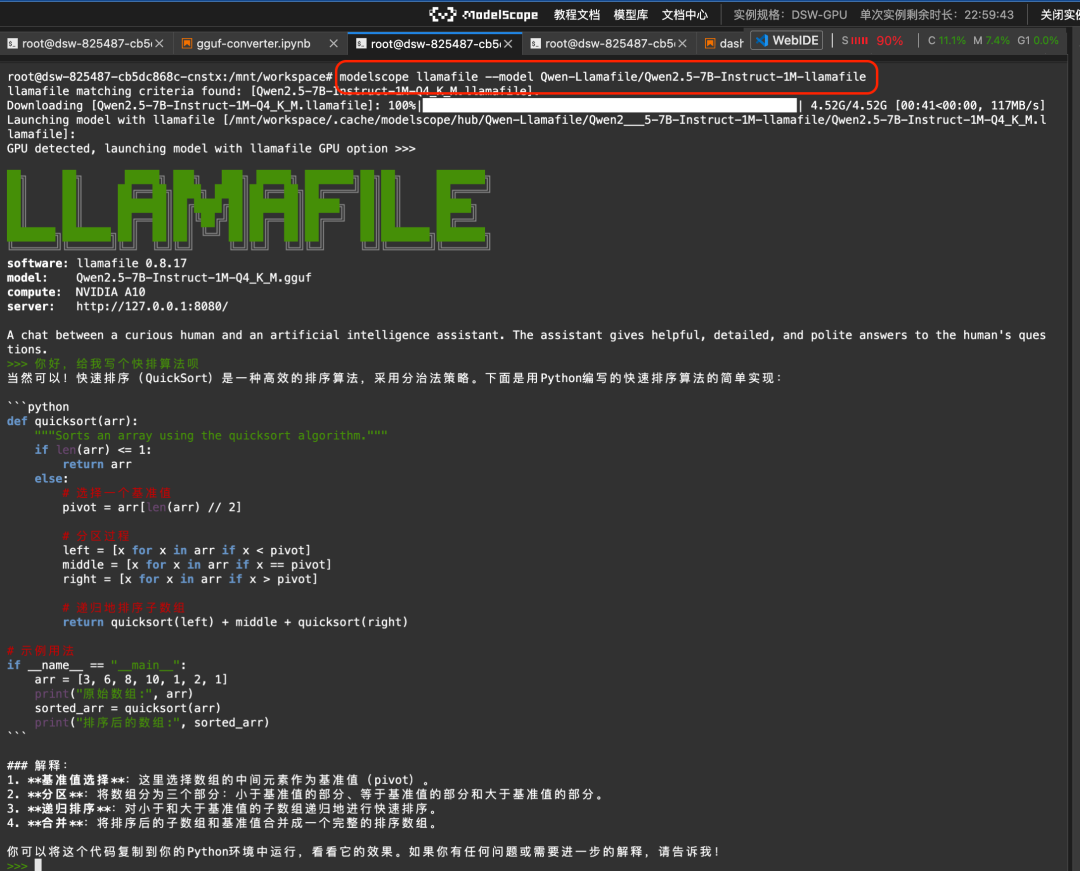
Llamafile 提供了大模型和运行环境全部封装在一个可执行文件中的方案。通过魔搭命令行和llamafile的集成,可以真正实现在Linux/Mac/Windows等不同操作系统环境中,一键运行大模型:
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafile运行结果:
更多文档可参见 https://www.modelscope.cn/docs/models/advanced-usage/llamafile
6.模型微调
这里我们介绍使用ms-swift对Qwen/Qwen2.5-7B-Instruct-1M进行微调。
在开始微调之前,请确保您的环境已正确安装:
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
我们给出可运行的微调demo和自定义数据集的样式,微调脚本如下:
CUDA_VISIBLE_DEVICES=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
训练显存占用:

自定义数据集格式:(直接使用`--dataset <dataset_path>`指定即可)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
推理脚本:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7.下一步是什么?
虽然 Qwen2.5-1M 系列为长序列处理任务带来了优秀的开源选择,研究团队也充分认识到长上下文模型仍有很大的提升空间。我们的目标是打造在长短任务中均能表现卓越的模型,确保它们在实际应用场景中真正发挥作用。为此,研究团队正深入研究更高效的训练方式、模型架构和推理方法,力求使这些模型即使在资源有限的环境中也能高效部署并且获得最佳的性能效果。 研究团队坚信,这些努力将为长上下文模型开启全新的可能性,大幅拓展其应用范围,并将持续突破这一领域的边界,敬请期待!
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...