
在大语言模型( LLM )的研究领域,模型的 Leap-of-Thought 能力,即创造力,其重要性不亚于以 Chain-of-Thought 为代表的逻辑推理能力。然而,目前针对 LLM 创造力的深入讨论和有效评估方法仍然相对匮乏,这在一定程度上制约了 LLM 在创意应用方面的发展潜力。
造成这一现状的主要原因在于,为“创造力”这一抽象概念构建一个客观、自动化且可靠的评估流程极其困难。
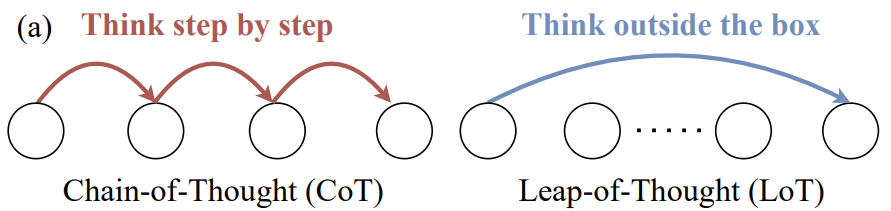
过去许多对 LLM 创造力的测评尝试,如图 1 所示,依然沿用评估逻辑思维能力时常用的选择题、排序题等形式。这类方法擅长考察模型是否能识别出预设的“最优”或“最符合逻辑”的选项,但对于评估真正的创造力——生成新颖、独特内容的能力——则显得力不从心。
例如,考虑图 2 中的任务:根据图片和已有文字,填补“?”处,要求内容富有创造性和幽默感。
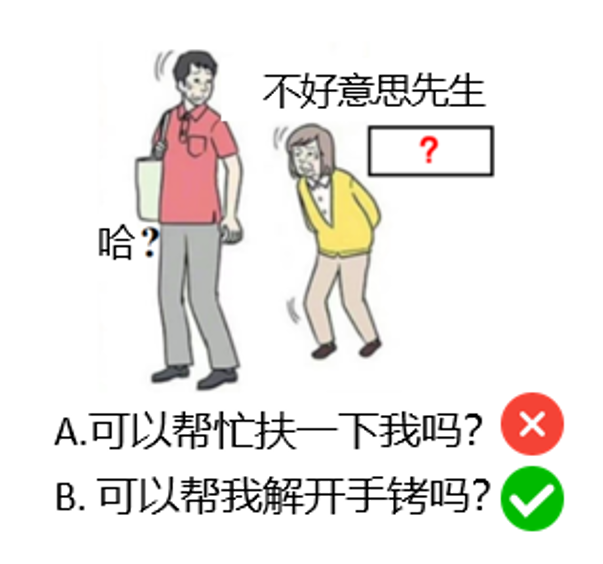
如果这是一个选择题,提供选项“A. 可以帮忙扶一下我吗?”和“B. 可以帮我解开手铐吗?”。 LLM 很可能选择 B,并非因为它展现了创造力,而仅仅是因为 B 选项相对于 A 选项更“特别”或“不寻常”,模型能够通过模式识别而非创造性思考来完成选择。
评估 LLM 的创造力,核心应该是考察其生成创新内容的能力,而不是判定内容是否创新的能力。传统的评估方法,如多项选择,更侧重于后者,因此存在局限性。当前,能够直接评估生成能力的方法主要是人工评估和 LLM-as-a-judge (使用 LLM 作为评审)。人工评估虽然准确且符合人类价值观,但成本高昂且难以规模化。而 LLM-as-a-judge 方法在创造力评估任务上的表现尚不成熟,结果稳定性也有待提高。
面对这些挑战,来自中山大学、哈佛大学、鹏城实验室和新加坡管理大学的研究者提出了一种新的思路。他们不再直接评判生成内容的“好坏”,而是通过研究 LLM 产生与人类高质量创新内容相当的响应所需要的“代价”(可以理解为所需付出的努力或交互成本),构建了一个名为 LoTbench 的多轮交互式自动化创造力评估范式。该方法旨在提供一个更可信、可扩展的创造力衡量标准。相关研究成果已发表于 IEEE TPAMI 期刊。

- 论文题目: A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models
- 论文链接: https://arxiv.org/abs/2501.15147
- 项目主页: https://lotbench.github.io
任务场景:日式冷吐槽
LoTbench 的研究基于 CVPR'24 会议上提出的“梗王”大模型(Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation)工作的期刊扩展。研究者选择了一种源自日本传统游戏“大喜利”(Oogiri)、在中文互联网上被称为“日式冷吐槽”的任务形式,如图 2 所示。
这种任务要求参与者观看图片,并补全文字,使得图文结合后产生创新且幽默的效果。选择该任务作为评估基础,主要基于以下几点考虑:
- 高创造力要求: 该任务直接要求生成创意幽默内容,是典型的创造力挑战。
- 契合多模态模型: 输入为图文,输出为文字补全,完全符合当前多模态
LLM的能力范畴。 - 丰富的数据资源: “日式冷吐槽”在网络社区流行度高,积累了大量高质量的人类创作实例及带有评价信息的数据,便于构建评测数据集。
因此,“日式冷吐槽”为评估多模态 LLM 的创造力提供了一个理想且独特的平台。
LoTbench 评估方法

与传统评估范式(如选择、排序)不同, LoTbench 的核心思想是:测量一个 LLM 需要经过多少轮交互才能生成一个与预设的人类高质量创新响应( HHCR )“异曲同工”的答案。 这个所需的“轮数”反映了 LLM 达到特定创意目标的“距离”或“成本”。
如图 3 右侧所示,对于一个给定的 HHCR , LoTbench 并非要求 LLM 精确复制它,而是看 LLM 能否在多轮尝试中,生成一个虽然表达方式不同、但创意核心和效果相似(即 DAESO - Different Approach but Equally Satisfactory Outcome)的响应。
LoTbench 的具体流程如图 4 所示:
- 任务构建: 从“日式冷吐槽”数据中精选
HHCR样本。每一轮,要求待测LLM根据图文信息,生成一个响应Rt来补全文字空缺。 - DAESO 判断: 判定生成的
Rt是否与目标HHCR(记为R)达到了DAESO。如果是,则记录当前轮数,用于后续计算分数;如果否,则进入步骤 3。 - 交互式提问: 若未达到
DAESO,则要求待测LLM根据当前的交互历史,提出一个一般疑问句Qt(例如,询问关于目标创意方向的线索)。 - 系统反馈: 评测系统根据
HHCR的内在逻辑,对LLM提出的问题Qt回答“是”或“否”。 - 信息整合与迭代: 将本轮的所有交互信息(包括
LLM的生成、提问、系统的反馈)以及系统提供的提示整合,形成下一轮的history prompt,返回步骤 1,开始新一轮的尝试。
这个过程持续进行,直到 LLM 生成了 DAESO 响应,或者达到了预设的最大轮数上限。
最终的创造力分数 Sc 基于对 n 个 HHCR 样本、进行 m 次重复实验的结果计算得出。其计算方式大致如下(以 HTML 公式表示):
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
其中,k_ij 是模型在第 j 次重复实验中,针对第 i 个 HHCR 样本,成功生成 DAESO 响应所用的轮数。
这个创造力分数 Sc 具有以下特点:
- 反比关系: 分数与所需轮数
k成反比。轮数越少,表明LLM越快达到目标创意水平,得分越高,创造力越强。 - 零分下限: 如果
LLM在最大轮数限制内始终无法生成DAESO响应(相当于轮数趋于无限),其对应该样本的分数趋近于 0,表示在此任务上创造力不足。 - 鲁棒性: 通过对多个
HHCR样本进行多次重复实验取平均,分数考虑了创意的多样性和难度,减少了单次实验的随机性影响。
如何判断“异曲同工之妙”( DAESO )?
DAESO 的判定是 LoTbench 方法的核心难点之一。
为何需要 DAESO 判定? 创造力任务的关键特征之一是其开放性和多样性。对于同一个“日式冷吐槽”场景,人类可以想出很多种不同但同样具有创意和幽默感的答案。如图 5 所示,“有活力的闹钟”和“有活力的手机”都围绕“物品因充满活力而跳动并发出声音”这一核心创意点,达到了相似的幽默效果。
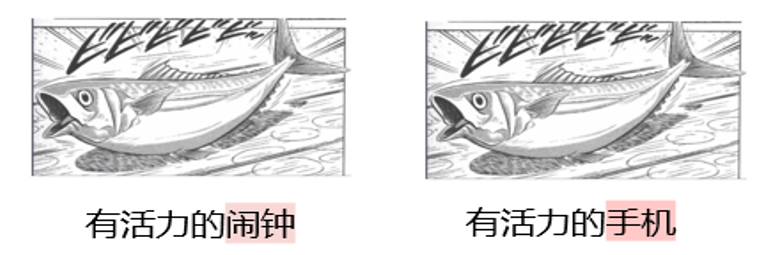
简单地通过文字表面匹配或常规的语义相似度计算,无法准确捕捉这种深层次的创意相似性。例如,“有活力的跳蚤”虽然也有“活力”,但缺少了“闹钟”或“手机”所暗示的“发出声音提醒”的功能关联。因此,必须引入对“异曲同工之妙”的判定机制。
如何实现 DAESO 判定?
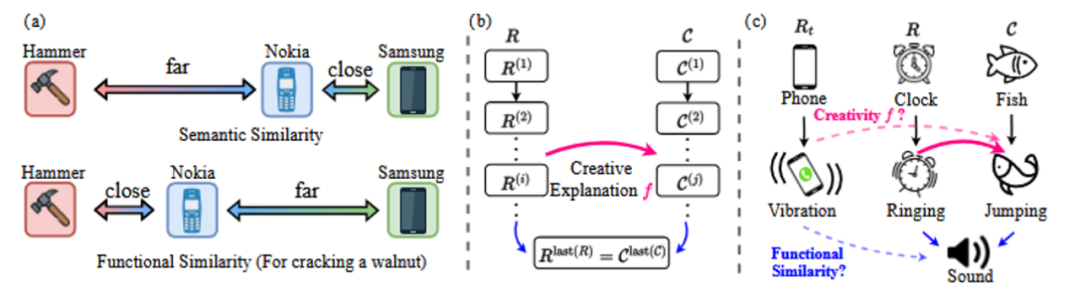
研究者在论文中提出,两个响应若要满足 DAESO ,需要同时满足两个条件:
- 相同的核心创新解释: 两个响应背后的创意逻辑或幽默点是基本一致的。
- 相同的功能相似性: 两个响应在引发幽默的“功能”或“场景角色”上是相似的。
功能相似性不同于纯粹的语义相似性。如图 6(a) 的例子所示,在“砸核桃”这个特定功能场景下,“诺基亚手机”与“锤子”的功能相似性,可能高于它与“三星手机”的语义相似性。
仅满足核心创新解释相同,可能导致响应偏离主题(如图 5 例子中的“有活力的跳蚤”,缺少“发声提醒”功能);仅满足功能相似性相同,则可能未能抓住创意的核心(如图 5 例子中的“有活力的鼓”,同样是发声物体,但缺少了因自身“活力”而跳动的感觉)。
在具体的 DAESO 判断实现中,研究者首先为每个 HHCR 样本标注了详细的解释,说明其幽默和创意的来源。然后,结合图像的标题(caption)信息,利用 LLM 本身的能力,在文本空间中为 HHCR 构建因果链条(如图 6(c) 所示),解析其创意构成。最后,设计特定的指令(instruction),让另一个 LLM (如 GPT-4o mini )根据这些信息,在文本空间中判断待测响应 Rt 与目标 HHCR 是否同时满足上述两个 DAESO 条件。
研究表明,使用 GPT-4o mini 进行 DAESO 判断,可以在较低的计算成本下达到 80%-90% 的准确率。考虑到 LoTbench 会进行多次重复实验,单次 DAESO 判断的微小误差对最终平均得分的影响会进一步减小,从而保证了整体评估的可靠性。
测评结果
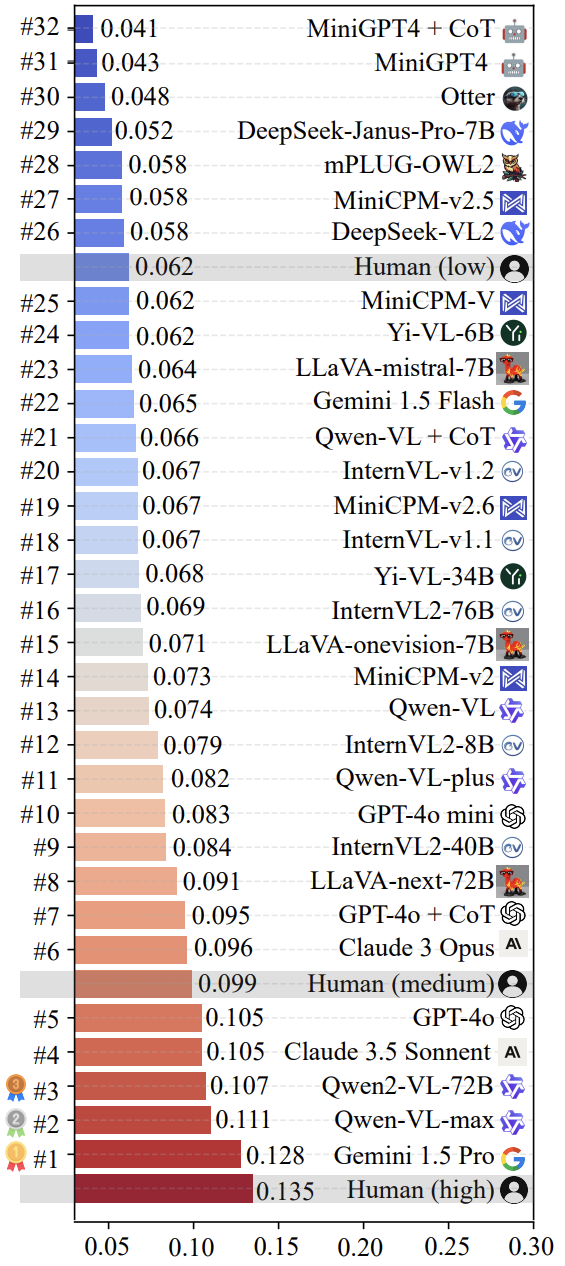
研究团队使用 LoTbench 对当前一些主流的多模态 LLM 进行了测评。如图 7 所示,结果显示,以 LoTbench 的标准衡量,现有 LLM 的创造力普遍不算强,与人类高质量创意响应( HHCR )相比仍有差距。然而,与普通人类水平(图中未明确标出,但可推断)或初级人类水平相比,部分顶尖 LLM (如 Gemini 1.5 Pro 和 Qwen-VL-max )已经展现出一定的竞争力,也暗示了 LLM 在创造力方面具备超越人类的潜力。
图 8 可视化了榜单中排名前二的 Gemini 1.5 Pro 和 Qwen-VL-max 模型针对部分 HHCR (红色标注)生成的 DAESO 响应(蓝色标注)。
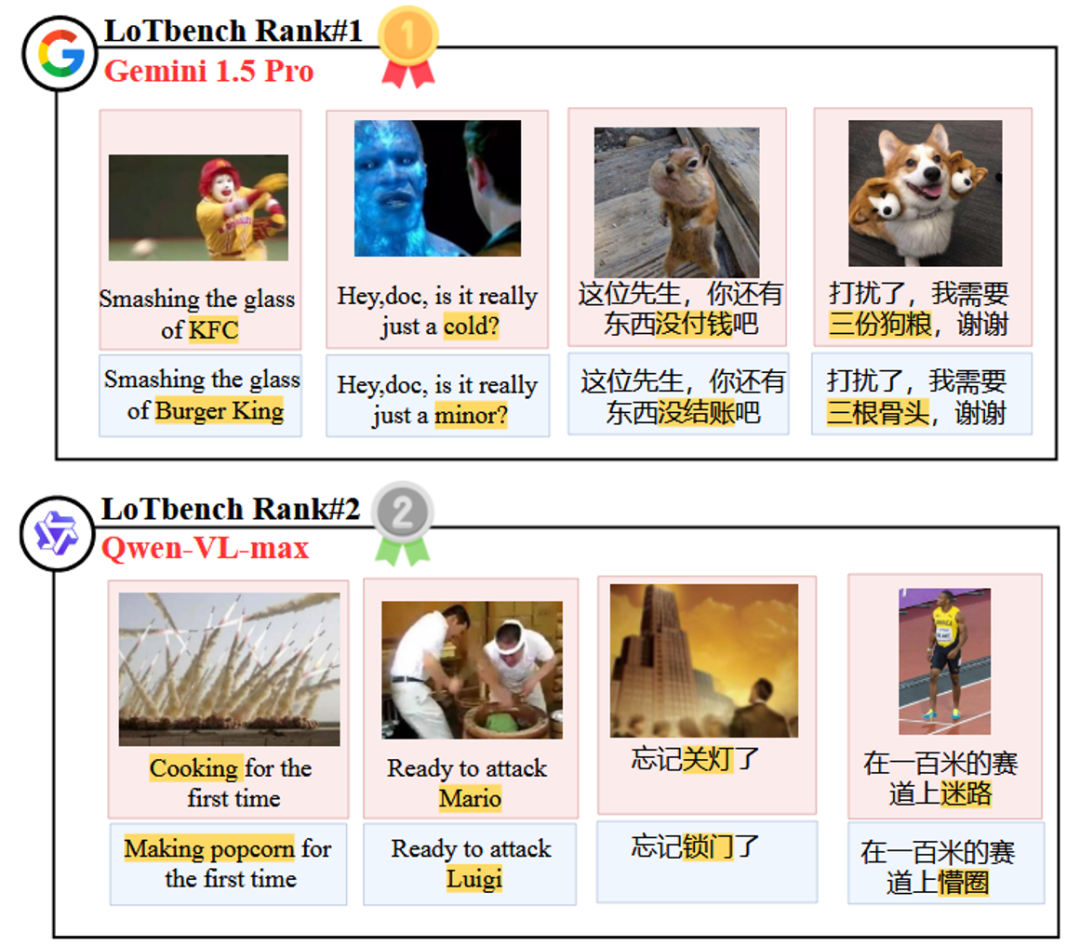
值得一提的是,近期备受关注的 DeepSeek-VL2 和 Janus-Pro-7B 系列模型也接受了评估。结果表明,它们的创造力在 LoTbench 框架下,大致处于人类初级阶段的水平。这表明在提升多模态 LLM 的深度创造力方面,仍有相当大的探索空间。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...