

综合介绍
openai-fm 是一个开源项目,托管在 GitHub 上,专门用于展示 OpenAI 文本转语音(Text-to-Speech, TTS)API 的功能。这个项目通过一个交互式网页应用,让开发者可以直观体验 OpenAI 的语音生成能力。它使用 NextJS 框架开发,结合 TailwindCSS 和 ShadcnUI 打造简洁现代的界面。用户可以输入文本,选择不同语音和情感风格,生成高质量的语音输出。项目代码完全开源,遵循 MIT 许可证,鼓励开发者克隆、修改和贡献代码。openai-fm 适合开发者快速了解和测试 OpenAI 语音API,特别适合需要语音功能的应用开发场景。
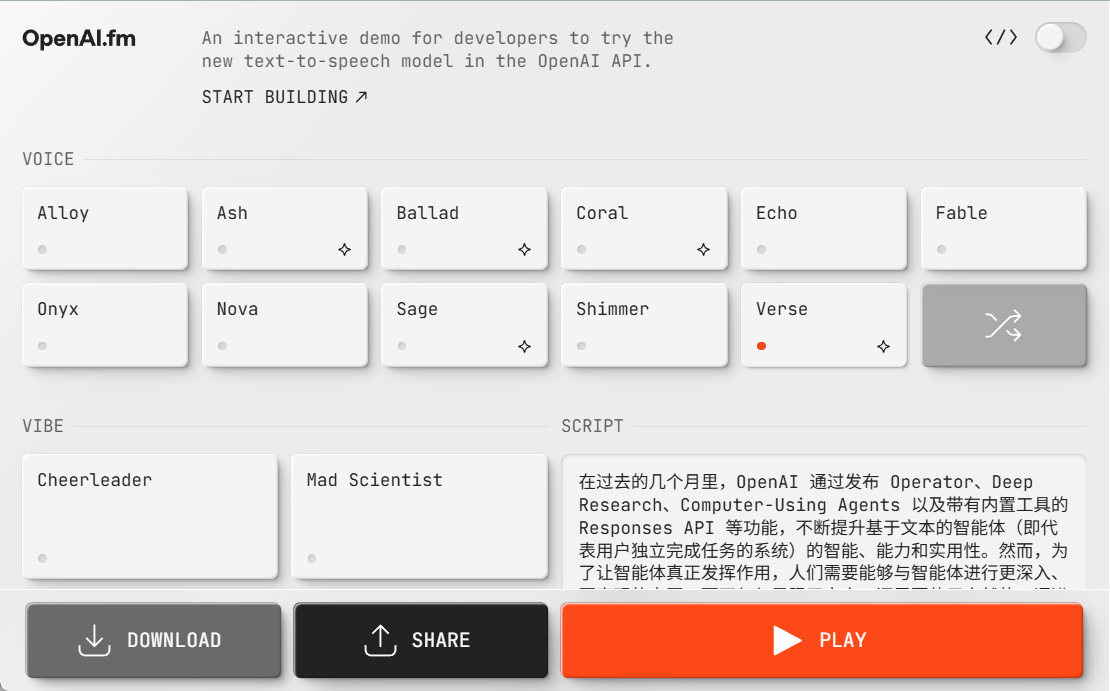
演示地址:https://www.openai.fm/
功能列表
- 文本转语音转换:将输入的文本转化为自然流畅的语音。
- 多种语音选择:提供多种语音选项,满足不同场景需求。
- 情感风格控制:支持调整语音的情感语气,如友好、严肃等。
- 实时交互演示:通过网页界面实时生成和播放语音。
- 数据库分享功能:支持连接 PostgreSQL 数据库,保存和分享生成的语音。
- 开源代码支持:提供完整源码,允许开发者自定义和扩展功能。
使用帮助
安装流程
要使用 openai-fm,首先需要克隆项目并配置环境。以下是详细步骤:
- 获取 API 密钥
访问 OpenAI 官网,注册或登录账户。在账户仪表盘中,导航到 API 密钥管理页面,点击“创建新密钥”,生成并保存你的OPENAI_API_KEY。这个密钥用于调用 OpenAI 的语音 API。注意:密钥需保密,避免泄露。 - 克隆仓库
打开终端,运行以下命令克隆 openai-fm 仓库:git clone https://github.com/openai/openai-fm.git
进入项目目录:
cd openai-fm
- 设置环境变量
你可以通过两种方式设置OPENAI_API_KEY:- 全局设置:在你的系统环境变量中添加
OPENAI_API_KEY。- Linux/MacOS 示例:
export OPENAI_API_KEY=<你的API密钥> - Windows 用户可在系统设置中添加环境变量。
- Linux/MacOS 示例:
- 项目内设置:在项目根目录创建
.env文件,参考.env.example,添加以下内容:OPENAI_API_KEY=<你的API密钥>
- 全局设置:在你的系统环境变量中添加
- 安装依赖
项目使用 Node.js 和 npm 管理依赖。确保已安装 Node.js(建议版本 16 或更高)。在项目根目录运行:npm install这会安装 NextJS、TailwindCSS、ShadcnUI 等必要依赖。
- (可选)配置数据库
如果需要使用分享功能,需连接 PostgreSQL 数据库。在.env文件中添加数据库连接信息,参考.env.example:POSTGRES_URL="postgresql://用户名:密码@主机:端口/数据库名"确保 PostgreSQL 服务已运行,并创建好相应的数据库。如果不使用分享功能,可跳过此步骤。
- 运行项目
安装完成后,运行以下命令启动开发服务器:npm run dev打开浏览器,访问
http://localhost:3000,即可看到 openai-fm 的交互界面。
主要功能操作
openai-fm 的核心是文本转语音的交互演示。以下是具体操作流程:
- 输入文本
在网页界面的文本框中输入你想转换为语音的文本。支持多行文本,适合长对话或脚本。示例:你好!这是一个测试,展示如何将文本转为自然语音。 - 选择语音和情感
界面提供下拉菜单,列出可用的语音选项(如男声、女声)和情感风格(如友好、严肃)。这些选项基于data/voices.json和data/vibes.json文件配置。选择后,点击“生成”按钮,系统会调用 OpenAI 语音 API 生成音频。 - 播放和下载
生成的音频会自动在页面播放。你也可以下载音频文件,文件默认保存为 WAV 格式,存储在项目目录的output/文件夹中,文件名以openaifm_开头并带时间戳。 - 分享功能
如果配置了 PostgreSQL 数据库,生成的语音可以保存到数据库并生成分享链接。点击“分享”按钮,系统会返回一个可访问的 URL,其他用户可通过此链接查看和播放你的语音。
开发者自定义
openai-fm 是开源项目,开发者可以根据需要修改代码。例如:
- 添加新语音:编辑
data/voices.json,增加新的语音配置。 - 调整界面:修改 NextJS 组件(如
pages/index.js)或 TailwindCSS 样式。 - 扩展功能:添加新的 API 调用或集成其他服务。
要贡献代码,可 fork 仓库,创建分支,提交 pull request。提交前请阅读项目的贡献指南,确保代码符合规范。[](https://github.com/openai/openai-fm)[](https://github.com/fairy-root/ComfyUI-OpenAI-FM)
注意事项
- API 费用:使用 OpenAI 语音 API 会产生费用,具体取决于使用量。请在 OpenAI 仪表盘监控你的 API 配额。
- 安全性:如果部署到公网服务器,确保
.env文件不被公开,防止 API 密钥泄露。 - 社区支持:遇到问题可在 GitHub 提交 issue,社区会提供帮助。
应用场景
- 开发者测试语音 API
开发者可用 openai-fm 快速测试 OpenAI 语音 API 的效果,验证不同语音和情感风格的表现,优化应用集成方案。 - 教育和培训内容制作
教师或培训师可将课程脚本转为语音,生成自然流畅的音频,用于在线课程或教学视频。 - 无障碍辅助工具
openai-fm 可为视障用户生成语音朗读内容,帮助他们访问文本信息。 - 创意内容创作
播客制作者或内容创作者可利用 openai-fm 生成个性化语音,快速制作试听样本。
QA
- openai-fm 需要付费吗?
项目本身免费,但使用 OpenAI 语音 API 需要有效的 API 密钥,并根据使用量支付费用。建议查看 OpenAI 官网的定价详情。 - 如何添加新的语音选项?
编辑项目目录下的data/voices.json文件,添加新的语音配置。重启服务器后,新语音会出现在下拉菜单中。 - 分享功能必须使用数据库吗?
是的,分享功能需要 PostgreSQL 数据库支持。如果不配置数据库,仍可正常生成和播放语音。 - 能否在移动端使用 openai-fm?
openai-fm 的网页界面支持响应式设计,可在移动端浏览器访问,但需确保网络连接稳定。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...