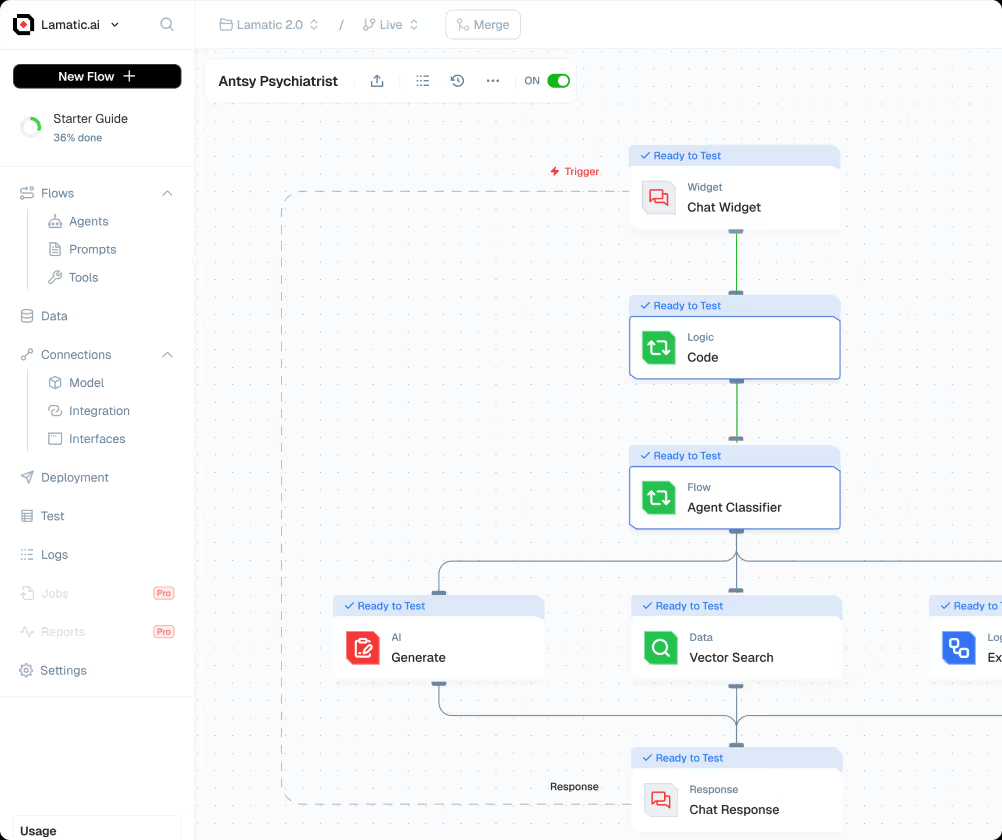

综合介绍
Open-Reasoner-Zero 是一个专注于强化学习(RL)研究的开源项目,由 GitHub 上的 Open-Reasoner-Zero 团队开发。它旨在通过提供高效、可扩展且易用的训练框架,加速人工智能领域的研究进程,特别是向通用人工智能(AGI)的探索。该项目基于 Qwen2.5 模型(7B 和 32B 参数版本),结合 OpenRLHF、vLLM、DeepSpeed 和 Ray 等技术,提供完整的源代码、训练数据和模型权重。它的显著特点是用不到 DeepSeek-R1-Zero 1/30 的训练步骤,就达到了相似的性能水平,展现了其在资源利用上的高效性。项目采用 MIT 许可证,用户可以自由使用和修改,非常适合研究人员和开发者参与协作。

功能列表
- 高效强化学习训练:支持在单控制器上实现训练和生成,最大化 GPU 利用率。
- 完整开源资源:提供 57k 条高质量训练数据、源代码、参数设置和模型权重。
- 高性能模型支持:基于 Qwen2.5-7B 和 Qwen2.5-32B,提供优异的推理性能。
- 灵活的研究框架:采用模块化设计,便于研究人员调整和扩展实验。
- Docker 支持:提供 Dockerfile,确保训练环境的可复制性。
- 性能评估工具:包含基准测试数据和评估结果展示,如 GPQA Diamond 的性能对比。
使用帮助
安装流程
Open-Reasoner-Zero 的使用需要一定的技术基础,以下是详细的安装和操作指南,适合在 Linux 或类 Unix 系统上运行。
环境准备
- 安装基础依赖:
- 确保系统已安装 Git、Python 3.8+ 和 NVIDIA GPU 驱动(需支持 CUDA)。
- 安装 Docker(推荐版本 20.10 或更高),用于快速部署训练环境。
sudo apt update sudo apt install git python3-pip docker.io
- 克隆项目仓库:
- 在终端运行以下命令,将项目下载到本地:
git clone https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero.git cd Open-Reasoner-Zero - 使用 Docker 配置环境:
- 项目提供了一个 Dockerfile,方便构建训练环境。
- 在项目根目录下运行:
docker build -t open-reasoner-zero -f docker/Dockerfile .- 构建完成后,启动容器:
docker run -it --gpus all open-reasoner-zero bash- 这将进入一个带有 GPU 支持的容器环境,预装了必要的依赖。
- 手动安装依赖(可选):
- 如果不使用 Docker,可以手动安装依赖:
pip install -r requirements.txt- 确保安装 OpenRLHF、vLLM、DeepSpeed 和 Ray,具体版本参考项目文档。
功能操作流程
1. 训练模型
- 准备训练数据:
- 项目自带 57k 条高质量训练数据,位于
data文件夹中。 - 如果需要自定义数据,按文档说明整理格式并替换。
- 项目自带 57k 条高质量训练数据,位于
- 启动训练:
- 在容器或本地环境中运行以下命令:
python train.py --model Qwen2.5-7B --data-path ./data- 参数说明:
--model:选择模型(如 Qwen2.5-7B 或 Qwen2.5-32B)。--data-path:指定训练数据路径。
- 训练日志会显示在主节点终端上,方便监控进度。
2. 性能评估
- 运行基准测试:
- 使用提供的评估脚本对比模型性能:
python evaluate.py --model Qwen2.5-32B --benchmark gpqa_diamond- 输出结果将显示模型在 GPQA Diamond 等基准上的准确率。
- 查看评估报告:
- 项目包含图表(如 Figure 1 和 Figure 2),展示性能和训练时间扩展情况,可在
docs文件夹中找到。
- 项目包含图表(如 Figure 1 和 Figure 2),展示性能和训练时间扩展情况,可在
3. 修改与扩展
- 调整参数:
- 编辑
config.yaml文件,修改学习率、批量大小等超参数。
learning_rate: 0.0001 batch_size: 16 - 编辑
- 添加新功能:
- 项目采用模块化设计,可在
src文件夹中添加新模块。例如,新增一个数据预处理脚本:
# custom_preprocess.py def preprocess_data(input_file): # 自定义逻辑 pass - 项目采用模块化设计,可在
操作注意事项
- 硬件要求:建议使用至少 24GB 显存的 GPU(如 NVIDIA A100),以支持 Qwen2.5-32B 的训练。
- 日志监控:训练过程中,保持终端开启,随时查看日志以排查问题。
- 社区支持:如遇问题,可通过 GitHub Issues 提交,或联系团队邮箱 hanqer@stepfun.com。
实践示例
假设你想训练一个基于 Qwen2.5-7B 的模型:
- 进入 Docker 容器。
- 运行
python train.py --model Qwen2.5-7B --data-path ./data。 - 等待数小时(视硬件而定),完成后运行
python evaluate.py --model Qwen2.5-7B --benchmark gpqa_diamond。 - 查看输出结果,确认性能提升。
通过以上步骤,用户可以快速上手 Open-Reasoner-Zero,无论是复现实验还是开发新功能,都能高效完成。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...