
Omnilingual ASR是什么
Omnilingual ASR是Meta推出的多语言语音识别框架,覆盖1600+语言,78%语言字符错误率低于10%。其70亿参数wav2vec 2.0编码器结合CTC与Transformer解码器,支持零样本转录未见语言,仅需少量示例即可适配新语种。模型开源,含350种低资源语言语料库,推动全球濒危语言数字化与语音技术普惠。
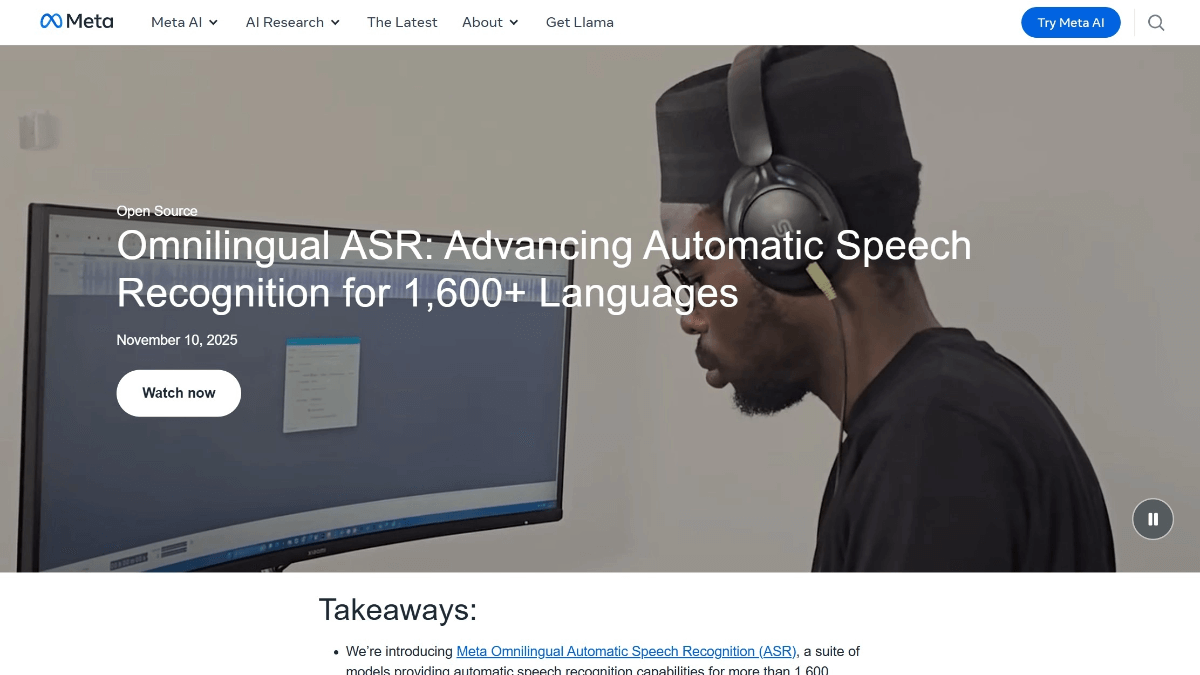
Omnilingual ASR的功能特色
- 多语言覆盖:支持超过1600种语言,涵盖多种低资源和濒危语言,显著提升语音识别的全球语言覆盖率。
- 低资源语言支持:通过自监督学习和数据增强技术,有效解决低资源语言数据稀疏问题,降低语音识别门槛。
- 零样本学习能力:能仅通过少量示例进行新语言的转录,无需大规模语料库,极大拓展了语言覆盖范围。
- 高性能架构:采用wav2vec 2.0编码器结合CTC和Transformer解码器,支持高精度和高效能的语音识别。
- 开源与合作:模型和数据集开源,促进全球开发者和研究者共同推动语音识别技术发展,助力濒危语言保护。
Omnilingual ASR的核心优势
- 广泛的语言覆盖:支持超过1600种语言,包括大量低资源和濒危语言,显著提升语音识别的全球语言覆盖率。
- 零样本学习能力:仅需少量音频和文本示例即可转录未见过的语言,极大降低了新语言的开发成本。
- 高性能架构:采用70亿参数的wav2vec 2.0编码器和先进的解码器,结合自监督学习,实现高精度语音识别。
- 开源与社区支持:模型和数据集开源,促进全球开发者和研究者共同参与,推动技术发展和语言保护。
- 创新的数据增强技术:通过合成语音等技术解决低资源语言数据稀疏问题,提升模型的泛化能力。
- 灵活的解码器选择:提供CTC和Transformer解码器两种选择,满足不同场景下的性能和效率需求。
Omnilingual ASR官网是什么
- 项目官网:https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
- GitHub仓库:https://github.com/facebookresearch/omnilingual-asr
- HuggingFace模型库:https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
- 技术论文:https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/
Omnilingual ASR的适用人群
- 语言研究者:可用于研究低资源和濒危语言,助力语言保护和语言学研究。
- 技术开发者:适合开发语音识别应用,利用其开源特性进行二次开发和集成。
- 内容创作者:方便制作多语言音频和视频内容,实现快速转录和字幕生成。
- 教育工作者:帮助开发多语言教育资源,支持语言教学和跨文化交流。
- 企业用户:适用于需要多语言语音识别服务的企业,如客服、会议记录等场景。
- 社区和非营利组织:可用于支持语言多样性项目,推动文化交流和语言保护工作。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...