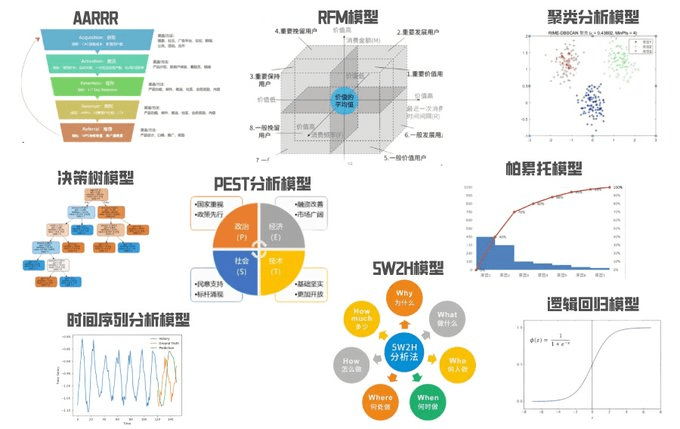

今天我在Hacker News上看到了一篇关于Obsidian集成了ChatGPT的新插件的文章。市场上有不少此类工具,我乐于看到人们用不同的方式把它们应用于Obsidian。它们能够帮助人们建立联系,让你的笔记内容更加深入。有评论者觉得这会替代你原本应自行完成的工作,然而我认为这实际上为你提供了新颖且惊人的能力。
与笔记对话
或许最直接也是你最想做的事情,就是与笔记内容对话。提出问题以深入了解。如果能直接将这个模型对准你的笔记,然后就一切顺利,那会非常便利。但是大部分模型无法一次性处理所有内容。
当你有问题时,并非所有笔记都与之相关。你需要找到相关部分,然后提交给模型。Obsidian提供搜索功能,但它只能搜寻确切的词语和短语,我们需要搜寻的是概念。这就是嵌入索引的用武之地。创建索引实际上是非常简单的。
构建索引器
创建Obsidian插件时,你可以设置它在启动时执行某些操作,然后当你执行命令、打开笔记或在Obsidian中进行其它活动时执行其他操作。所以我们希望这个插件一开始就能理解你的笔记,并且它应该保存它的进度,这样就不需要再次生成索引了。让我们看一段代码示例,它展示了如何为我们的笔记建立索引。我此处使用的是[Llama Index],[LangChain]也是一个极好的选择。
import { VectorStoreIndex, serviceContextFromDefaults, storageContextFromDefaults, MarkdownReader } from "llamaindex";
const service_context = serviceContextFromDefaults({ chunkSize: 256 })
const storage_context = await storageContextFromDefaults({ persistDir: "./storage" });const mdpath = process.argv[2];
const mdreader = new MarkdownReader();
const thedoc = await mdreader.loadData(mdpath)
首先,我们要初始化一个内存中的数据仓库。这是Llama Index自带的存储设施,但Chroma DB也是受欢迎的选择。第二行代码表示我们要持久化索引中的所有内容。接下来,获取文件路径并初始化一个读取器,然后读取文件。Llama Index懂Markdown,所以它可以正确读取并为内容建立索引。它还支持PDF、文本文件、Notion文档等等。它不仅存储单词,还理解单词的含义以及它们与文本中其他单词的关系。
await VectorStoreIndex.fromDocuments(thedoc, { storageContext: storage_context, serviceContext: service_context });
现在,这部分代码利用了OpenAI的一个服务,但它与ChatGPT是分开的,使用的是不同的模型和产品。Langchain也提供替代品,可以本地完成这项工作,尽管速度稍慢。Ollama也提供嵌入功能。你还可以在云端的一个超快速自托管实例上使用这些服务,待索引完成后再关闭该实例。
搜索笔记
我们已经为这个文件建立了索引。Obsidian可以列出所有文件,因此我们可以反复运行这一过程。我们正在持久化数据,因此只需操作一次。现在我们如何提问?我们需要一些代码,去我们的笔记中找到相关部分,递交给模型,并使用这些信息得到答案。
const storage_context = await storageContextFromDefaults({ persistDir: "./storage" });
const index = await VectorStoreIndex.init({ storageContext: storage_context });
const ret = index.asRetriever();
ret.similarityTopK = 5
const prompt = process.argv[2];
const response = await ret.retrieve(prompt);
const systemPrompt = `Use the following text to help come up with an answer to the prompt: ${response.map(r => r.node.toJSON().text).join(" - ")} `
在这段代码中,我们使用已处理的内容来初始化索引。`Retriever.retrieve`这一行会利用提示信息找到所有相关的笔记片段,并将文本返回给我们。这里我们设定使用前5个最匹配的结果。因此我将从笔记中得到5个文本片段。有了这些原始数据,我们可以生成一个系统提示来指导模型在我们提出问题时应该如何作答。
const ollama = new Ollama();
ollama.setModel("llama2");
ollama.setSystemPrompt(systemPrompt);
const genout = await ollama.generate(prompt);
接着,我们开始使用模型。我使用了我几天前创建的一个在[npm]上的库。我设定模型使用llama2,它已经通过命令`ollama pull llama2`下载到我的机器上了。你可以试验不同的模型来找到最适合你的答案。
为了快速得到答案,你应该选择一个小型模型。但同时,你也要选择一个输入上下文大小足够容纳所有文本片段的模型。我设置了至多5个256令牌的文本片段。系统提示中包括了我们的文本片段。只需提出问题,几秒钟内就可以得到答案。
太棒了,现在我们的Obsidian插件能够适当地显示答案。
我们还能做什么?
你还可以考虑简化文本内容,或者找出最佳关键词与你的文本相匹配并将它们加入到元数据中,这样你就能更好地将笔记联系起来。我尝试过制作10个有用的问题和答案,并将它们发送到[Anki]。你可能会想尝试不同的模型和提示来达成这些不同的目的。根据任务需求更改提示甚至模型权重都非常容易。
我希望这篇文章能给你一些启发,让你了解如何为Obsidian或其他笔记工具开发下一个优秀的插件。如你在[ollama.com]所见,使用最新的本地AI工具是轻而易举的,并且我希望你能向我展示你的创意。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...